
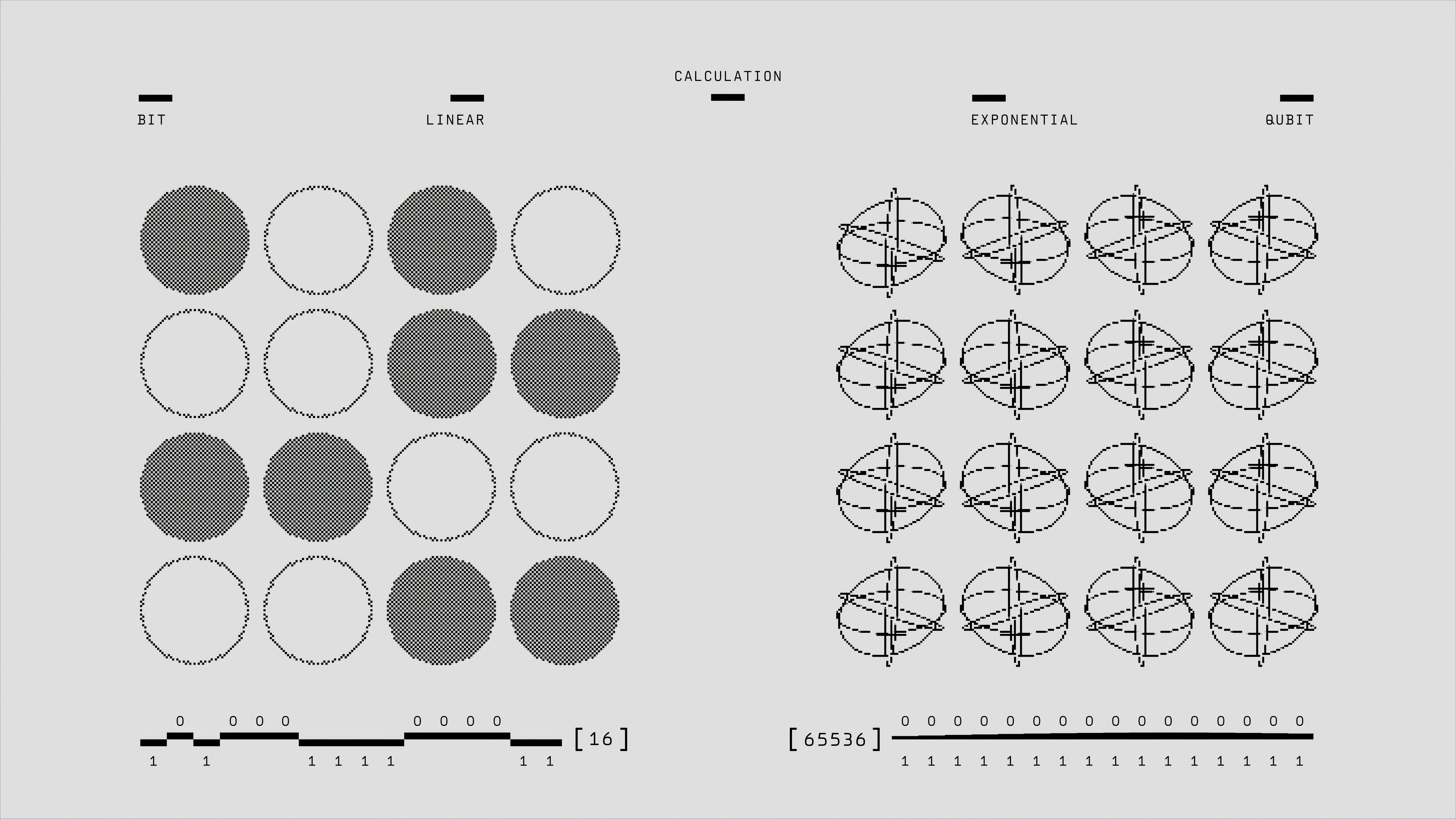
LongTraceRL: Razón de largo contexto con recompensas de rúbrica
LongTraceRL mejora el razonamiento en contexto largo usando recompensas de rúbrica y distractores por niveles desde trayectorias de agentes de búsqueda.
LongTraceRL mejora el razonamiento en contexto largo usando recompensas de rúbrica y distractores por niveles desde trayectorias de agentes de búsqueda.
PATHS: temple paralelo para muestreo inicial en alineación de recompensas. Evita modas locales y explora regiones raras de alta recompensa en modelos generativos.

Softmax Recocido logra arrepentimiento casi óptimo en bandidos Bayesianos, explicando por qué GRPO funciona sin incertidumbre explícita.

EchoRL identifica EchoClips en rollouts exitosos para proporcionar supervisión auxiliar y mejorar el aprendizaje por refuerzo en LLMs, superando la degeneración de ventajas.
Recompensas con momentum para semáforos de bajas emisiones: descubre cómo este sistema innovador incentiva la conducción ecológica y reduce la contaminación urbana.

Descubre qué son los puntos de fidelidad y cómo funcionan las recompensas. Aprende a aprovecharlos al máximo.

<meta name=description content=HPO optimiza el entrenamiento de IA con recompensas dispersas: estable, eficiente y robusto. Descubre cómo mejorar tus modelos.>
Propagación de recompensas en grafos de estado para RL agentivo con LLMs: optimiza el aprendizaje por refuerzo y la toma de decisiones en agentes inteligentes.
<meta content=Diagnóstico y refinamiento de recompensas en LLM cuando falla el RL disperso. Aprende a identificar y corregir errores en el diseño de recompensas para mejorar el entrenamiento>
Modelado de recompensas con LLM para equidad demográfica en edificios interactivos. Descubre cómo la IA optimiza la justicia entre grupos en entornos inteligentes.
PIRS: Recompensas informadas por física para gestión energética en edificios con SAC. Optimiza el consumo energético mediante aprendizaje por refuerzo.

Enrutamiento de tareas por habilidades en redes descentralizadas de agentes IA con incentivos: optimiza la asignación y recompensa para una eficiencia superior.
<meta name=description content=Transforma tu subtitulado visual de débil a fuerte usando recompensas hipergeométricas. Mejora tu SEO con esta técnica avanzada.>
IRDS selección interpretable de datos RLVR con autoencoder disperso y verificador. Optimiza el aprendizaje por refuerzo con transparencia y eficiencia.

<meta name=description content=10 series como The Mandalorian para ver a continuación. Descubre las mejores recomendaciones de ciencia ficción y acción para seguir disfrutando.>
Refina modelos de recompensa de video multidimensionales con funciones de influencia desenredadas. Mejora la precisión y eficiencia en aprendizaje por refuerzo.
Pak Cab obtiene 31 en prueba de utilidad con su app sostenible de viajes eléctricos y recompensas gamificadas. Descubre cómo esta innovadora propuesta transforma la movilidad urbana.
<meta name=description content=Soft-SVeRL combina aprendizaje por refuerzo con auto-verificación y recompensas suaves para optimizar el rendimiento de los modelos. Descubre esta innovadora técnica.>
Analizamos el doble filo de las ventajas negativas en GRPO para agentes de búsqueda: beneficios y riesgos clave en su aplicación.
<meta name=description content=Método innovador de razonamiento auto-evolutivo mediante minería de lógica latente y descomposición de recompensas para optimizar la toma de decisiones en IA.>