
Por qué un LMS en un bot de Telegram funciona mejor que apps dedicadas
Descubre por qué un LMS en un bot de Telegram supera a las apps tradicionales: mayor retención, menos fricción y desarrollo en semanas.
Descubre por qué un LMS en un bot de Telegram supera a las apps tradicionales: mayor retención, menos fricción y desarrollo en semanas.

Descubre cómo los LLMs permiten una moderación de contenido precisa y escalable. Aprende estrategias prácticas para detectar contenido dañino con IA.

Evaluación de agentes, seguridad y modelos locales toman el centro. Conoce AWS Agent-EvalKit, GatekeeperAI, ataques a agentes, MLX y Vilvona AI.

Google presenta la incertidumbre fiel: LLMs que ofrecen conjeturas en vez de alucinar. La clave para una IA empresarial confiable.

Descubre cuándo autoinformes de LLMs predicen su comportamiento. Estudio revela que Teoría del Comportamiento Planificado supera al Big Five en coherencia.

MLUBench: benchmark para desaprendizaje continuo en MLLMs. Revela grave degradación acumulativa. LUMoE mitiga el problema preservando la alineación multimodal.

Descubre cómo un marco de simulación de dos agentes evalúa arquitecturas de búsqueda agentiva en e-commerce, mejorando calidad y reduciendo fallos en un 62%

ReCal calibra recompensas para enrutamiento de LLMs con RL, mejorando asignación de crédito y reduciendo sesgos. Aumenta rendimiento y estabilidad.

Descubre cómo PI-Hunter automatiza la auditoría de agentes de IA para detectar y localizar inyecciones de prompt ocultas, mejorando la seguridad de tus sistemas.

UOJ-Bench evalúa LLMs en programación competitiva: generación, hacking y reparación. En una prueba, fallan en detectar >50% errores; con escalado superan >90%.

Descubre cómo TWLA, mediante cuantización post-entrenamiento, reduce el tamaño y acelera la inferencia de LLMs usando pesos ternarios y activaciones de 4 bits.

TWLA permite cuantizar LLMs a pesos ternarios y activaciones de 4 bits, reduciendo el costo de inferencia sin perder precisión.

Descubre WildIFEval: 7,000 instrucciones reales con múltiples restricciones. ¿Cómo siguen las instrucciones los LLMs? Benchmark y análisis detallado.

Descubre cómo los modelos de lenguaje crean jerarquías emocionales que imitan la psicología humana y revelan sesgos sociales. Un estudio fascinante sobre IA y emociones.

Descubre cómo identificar el autor (humano o IA) de textos en múltiples idiomas. Un estudio revela los retos de la atribución multilingüe con LLMs.

CuMA alinea modelos de lenguaje a valores culturales usando mezcla de adaptadores, evitando el colapso medio y preservando la pluralidad cultural.
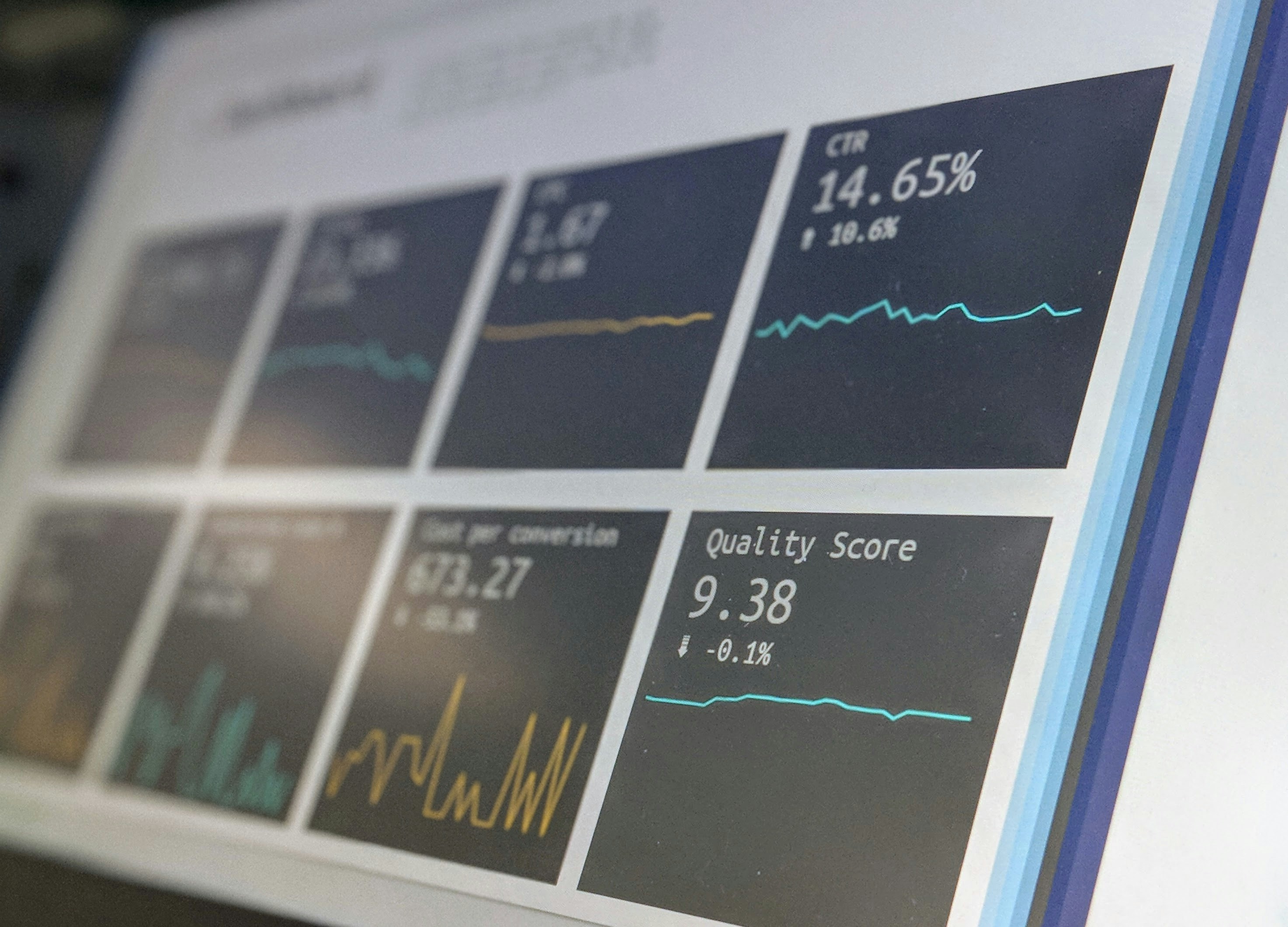
Descubre Fin-RATE, un benchmark realista que mide la capacidad de los LLMs para analizar informes financieros de la SEC, detectando errores clave.
PaLMR alinea procesos de razonamiento visual en modelos multimodales, reduciendo alucinaciones y mejorando fidelidad. Logra resultados de vanguardia en HallusionBench, MMMU, MathVista y MathVerse.

Descubre cómo SupraBench evalúa LLMs en tareas fundamentales de química supramolecular. Un benchmark innovador para predecir afinidades y más.

Una sola página contaminada engaña a los LLMs haciéndolos promover productos falsos. El benchmark FORGE revela una vulnerabilidad del 73% en tres páginas.