
FUSAR-GPT: VLM con características espacio-temporales para imágenes SAR
Descubre FUSAR-GPT, el modelo de lenguaje visual que integra características espacio-temporales para mejorar la interpretación de imágenes SAR en más del 10%.
Descubre FUSAR-GPT, el modelo de lenguaje visual que integra características espacio-temporales para mejorar la interpretación de imágenes SAR en más del 10%.

Descubre UNIVID, el modelo que unifica visión y lenguaje para moderar videos con precisión, interpretabilidad y eficiencia, reduciendo violaciones y costos.

Descubre cómo las cabezas CoRe en LLMs multimodales logran eficiencia: al eliminar solo el 5% se degrada el rendimiento, pero su uso acelera la inferencia. Una clave para la optimización.

Descubre SENSEI, IA interpretable que localiza y corrige conceptos erróneos para mejorar el rendimiento a largo plazo. ¡Corrige la mente!

SENSEI: Asistencia IA que localiza y corrige tus conceptos erróneos, no solo tus acciones. Mejora tu rendimiento a largo plazo. 90% de éxito.

EML-CD recupera mecanismos causales como ecuaciones cerradas usando árboles simbólicos EML. Supera a métodos tradicionales en precisión e interpretabilidad. ¡Descúbrelo!

Descubre cómo los métodos de aproximación dispersa reducen muestras para operadores de EDP, mejorando eficiencia e interpretabilidad

Descubre FreqX: método de interpretabilidad para aprendizaje federado que ofrece atribución y conceptos usando señales y teoría de la información. 10x más rápido.

FreqX ofrece atribución fiable y rápida con información conceptual para modelos diversos en aprendizaje federado. ¡Más de 10 veces más rápido!
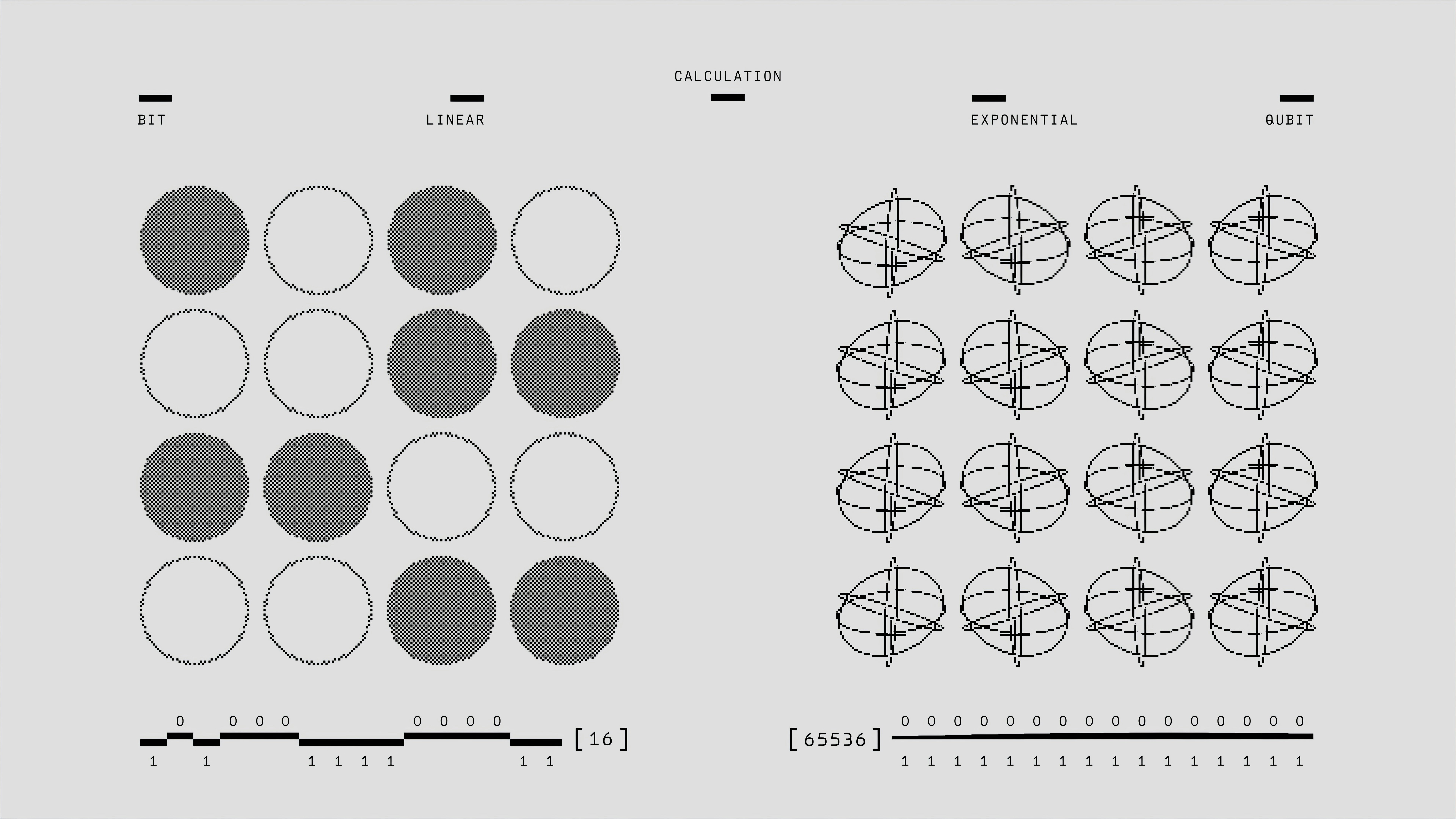
Concept-SAE: controla y edita conceptos en redes neuronales, mejorando interpretabilidad y detectando ataques adversariales. ¡Descúbrelo!

Descubre cómo Concept-SAE controla conceptos específicos en modelos de IA, mejorando interpretabilidad y detección adversarial.
Descubre WiserUI-Bench, el benchmark que evalúa si las MLLMs realmente comprenden cómo el diseño UI/UX influye en el comportamiento del usuario a través de pruebas A/B reales.

¿Son confiables las explicaciones de seguridad IA? Descubre la ilusión de fundamentación y la importancia de la alineación semántica.

¿Los patrones selectivos indican causalidad? Este estudio mecanicista entre modelos de 1B revela que no. Compara Pythia, OLMo y OLMoE en tareas compuestas.
Descubre cómo los grafos causales y las cadenas contrafactuales revelan el razonamiento interno de los LLM, mejorando la transparencia y la interpretabilidad en tareas de clasificación.

Descubre cómo modelos interpretables predicen exacerbaciones de asma infantil en Virginia costera combinando contaminación, clima y factores socioeconómicos. Es

Descubre cómo SASA mejora la interpretabilidad de LLMs reduciendo la fragmentación de características y usando la mitad de los tokens de entrenamiento.

Descubre cómo la afinidad localizada mejora el aprendizaje por refuerzo para crear agentes de IA virtuosos en el juego Fog of Love. Resultados superiores.

Las explicaciones contrafactuales revelan qué características diferencian dos grupos en pruebas de hipótesis con deep learning. Un método basado en MMD y autoen

MedForge detecta deepfakes médicos con explicaciones confiables y razonamiento forense para proteger la seguridad clínica.