Atención Consistente en Preguntas Visuales Médicas con Modelos Base
Aprende cómo la atención consistente guiada por modelos base de visión optimiza el diagnóstico en radiografías de tórax con preguntas visuales longitudinales.
Aprende cómo la atención consistente guiada por modelos base de visión optimiza el diagnóstico en radiografías de tórax con preguntas visuales longitudinales.

Descubre cómo ViSAE usa circuitos de concepto inspirados en neurociencia para interpretar y guiar Vision Transformers, mejorando precisión y confianza.

Descubre PURe: redes residuales que modelan interacciones no lineales, mejoran robustez y eficiencia en datos reducidos, y ofrecen interpretabilidad con SHAP.

Los modelos de lenguaje pueden resistir manipulaciones internas. Descubre cómo funciona la resistencia endógena y sus implicaciones para la seguridad.

Descubre cómo descompilar Transformers a RASP revela algoritmos interpretables. Un método innovador para entender la generalización de longitud en IA.

Descubre TRUE: un marco que unifica verificación ejecutable, diagramas DAG de regiones factibles y análisis causal de fallos para hacer el razonamiento de los LLM más interpretable y confiable.

Descubre cómo el aprendizaje profundo de representaciones abre la caja negra de las redes neuronales. Principios, teoría matemática y aplicaciones prácticas.

Descubre cómo mejora la reconstrucción cerebral con aprendizaje de correcciones estructuradas, preservando la interpretabilidad bayesiana.

Descubre cómo los expertos lineales diminutos con puertas dispersas (sgatlin) mejoran la eficiencia e interpretabilidad de los modelos de lenguaje, sin aumentar costo.

Descubre cómo sgatlin, expertos lineales diminutos con activación dispersa, mejora la eficiencia y la interpretabilidad de los modelos transformer. Una nueva vía hacia IA más comprensible.
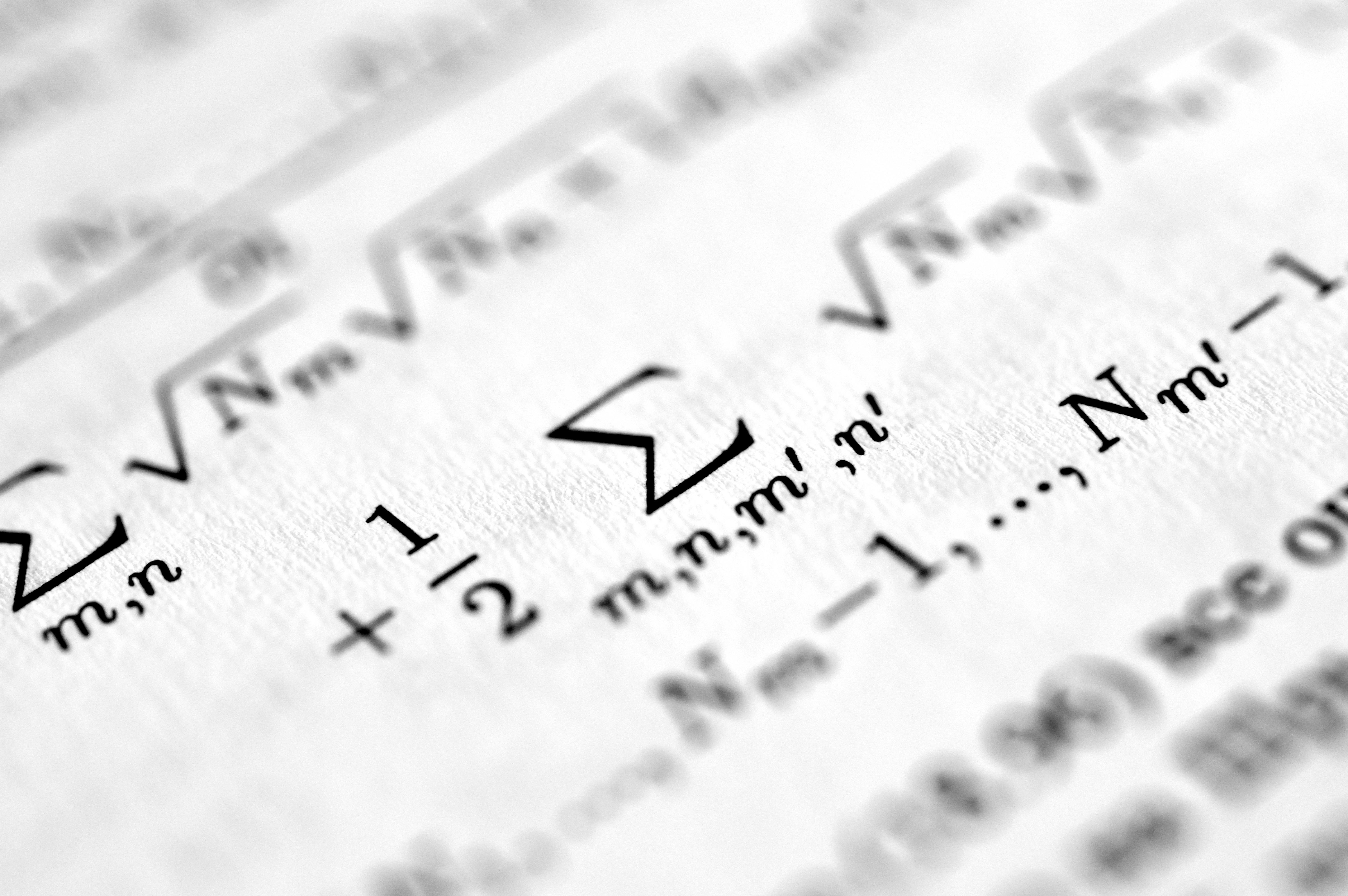
Descubre DeSI: una técnica de regresión semiparamétrica que combina redes neuronales profundas con un índice interpretable para predecir en espacios métricos como distribuciones y matrices.

Descubre cómo la factorización interpretable de cuestionarios clínicos revela factores latentes en psicopatología y mejora el diagnóstico.

Mejora la interpretabilidad del aprendizaje por refuerzo con RSA2C, un algoritmo kernelizado que usa atribuciones SHAP para entrenar actores y críticos con estabilidad y eficiencia.

Explora cómo la geometría revela el aprendizaje de conceptos en autoencoders dispersos y permite interpretar neuronas de forma clara.

Descubre qué es el sumidero de atención en Transformers, cómo afecta a la IA y las estrategias para mitigarlo en esta revisión completa.

Descubre cómo la alineación de señales acústicas mejora el reconocimiento de emociones en modelos de lenguaje de audio. Resultados en FAU-Aibo e IEMOCAP.
Descubre cómo un marco de IA interpretable y confiable utiliza aprendizaje profundo y predicción conforme para estudiar la relación estructura-dolor en la osteoartritis.
Descubre cómo un marco de IA interpretable y confiable analiza miles de resonancias para predecir dolor y progresión en osteoartritis de rodilla.

Descubre cómo los LLMs pueden reconocer sus propias salidas mediante firmas de activación internas, logrando una atribución precisa sin degradar la calidad del texto.

Descubre cómo SHAP y LLM explican las puntuaciones automáticas en evaluación docente. Análisis de fidelidad y transferibilidad en el marco CLASS.