Blade: Inversión bayesiana sin derivadas con priors de difusión
Blade: inversión bayesiana sin derivadas con priors de difusión. Partículas interactuantes para posteriores precisos y calibrados en dinámica de fluidos.
Blade: inversión bayesiana sin derivadas con priors de difusión. Partículas interactuantes para posteriores precisos y calibrados en dinámica de fluidos.

Nuevos límites inferiores de primer orden para optimización no convexa suave de alto orden. Resultados óptimos para Hessianas y terceras derivadas Lipschitz.

Descubre cómo la alineación bidireccional con consistencia cíclica reduce el olvido catastrófico en aprendizaje incremental sin ejemplares, mejorando precisión.

Descubre cómo las RNN asimétricas modelan dinámicas complejas con drift-diffusion matching, aplicado a memorias asociativas y episódicas.

Preserva la alineación de seguridad de tus LLMs durante el fine-tuning con PACT: restricciones focalizadas en tokens de seguridad que evitan la deriva sin sacrificar rendimiento.

Descubre cómo el nuevo método DI-Loss reduce en un 66% el error de energía y acelera hasta un 50% las iteraciones SCF en funcionales XC aprendidos.

Descubre cómo Latte, un framework de pruebas de caja negra, genera casos de prueba diversos y semánticamente cercanos para detectar fallos en redes neuronales profundas.

Descubre cómo SPLIT-PINN generaliza la predicción probabilística de microestructuras en materiales policristalinos.
Descubre cómo los gráficos de derivación simplifican el razonamiento del Do-Cálculo, permitiendo obtener estimadores más eficientes para la inferencia causal. ¡Lee más!
Descubre cómo Multi², un marco jerárquico multiagente con LLMs, evita la deriva de objetivos y mejora la toma de decisiones en entornos interactivos. ¡Lee más!

DriftSched optimiza la programación GPU multi-inquilino con compensación adaptativa de deriva de tokens, reduciendo latencia un 42% y mejorando QoS.

El olvido catastrófico no borra conocimiento, solo desalinea interfaces. Descubre cómo claves de transporte recuperan conocimiento latente en IA.
Las personas sintéticas permiten evaluar la alineación pluralista en IA generativa, superando benchmarks únicos y revelando la necesidad de mecanismos dinámicos.

ParisKV: recuperación de caché KV para LLMs largos, hasta 44x más rápido y robusto ante deriva. Optimiza tu inferencia.
El Drifting Generativo no es magia: es Score Matching. Aprende su teoría, la elección de kernels, y cómo estabilizar el entrenamiento con el operador stop-gradient.

Analizamos la propagación de errores en modelos de difusión con datos sintéticos. Primeras cotas inferiores de divergencia y regímenes de deriva.

Descubre cómo la truncación balanceada con cuadratura Hermite simétrica permite aprender sistemas dinámicos lineales a partir de datos de derivadas, preservando estabilidad y hermiticidad.

Analizamos las cotas de error teóricas de un estimador de deriva basado en modelos de difusión, descomponiendo el riesgo en discretización, aproximación de score, inicialización y varianza.

FIRM alinea LLMs con múltiples objetivos eficientemente y en privado usando aprendizaje federado. Mejora equilibrio entre utilidad e inocuidad.
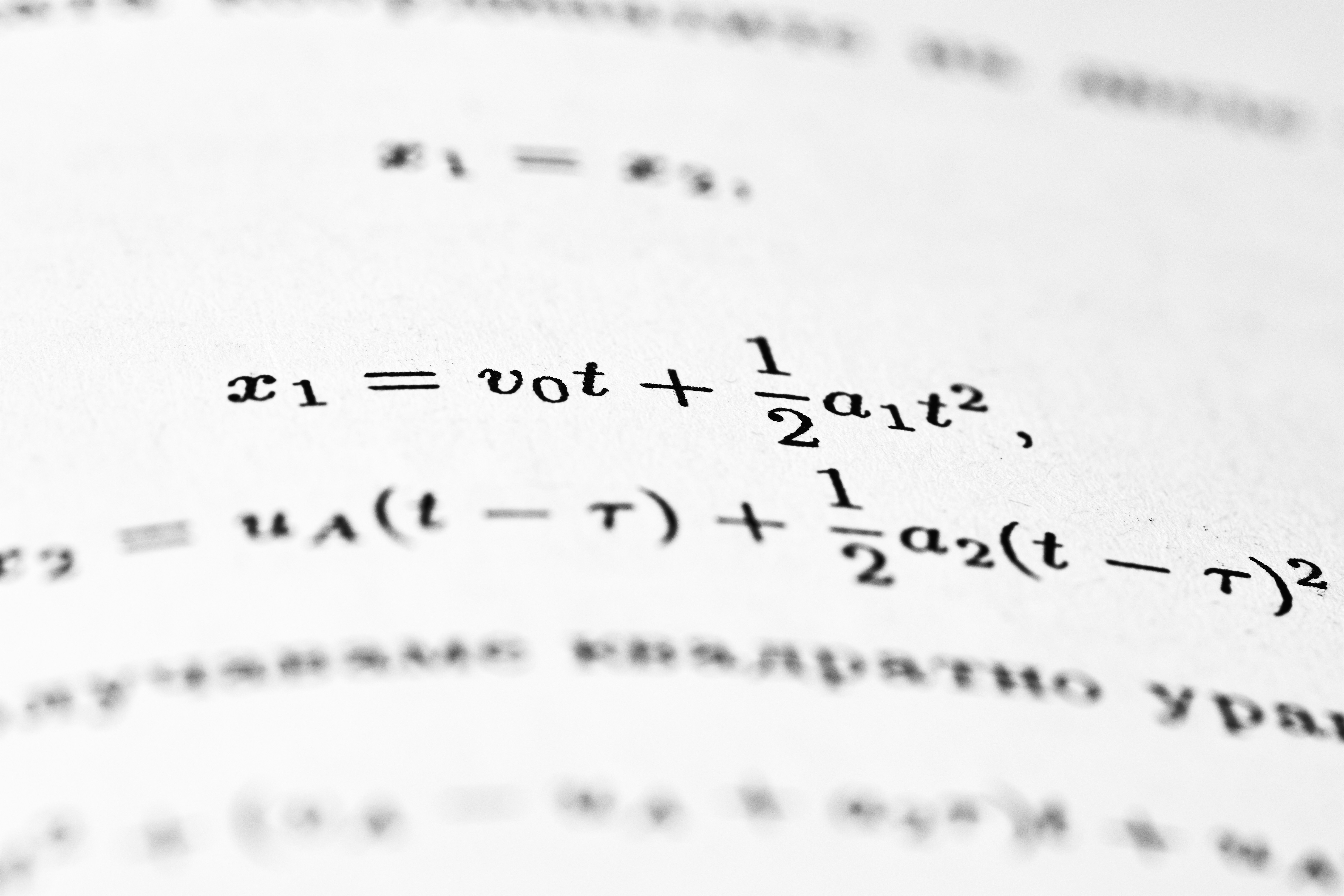
Descubre cómo la optimización bayesiana preferencial local supera limitaciones en alta dimensionalidad, reduciendo el arrepentimiento acumulativo en experimentos costosos.