
Modelos toman notas en prefill: caché KV editable y componible
Descubre cómo editar y componer la caché KV durante el prefill reduce la latencia hasta 14.9x sin perder precisión. Ideal para modelos de IA en producción.
Descubre cómo editar y componer la caché KV durante el prefill reduce la latencia hasta 14.9x sin perder precisión. Ideal para modelos de IA en producción.

Re-alimentar el prompt introduce ruido en crédito contrafactual, afectando selección de tokens. Estudio vLLM revela diferencias hasta 28pp.

MiniPIC: solución minimalista de caché KV mejora el throughput de prefill un 49% y reduce latencia. Ideal para cargas agentivas.

Descubre DiffusionGemma, el nuevo modelo de Google que genera texto 4x más rápido en paralelo. Ideal para inferencia local, pero con menor calidad. ¿Vale la pena?

Descubre DiffusionGemma, el modelo de texto por difusión que genera bloques de 256 tokens en paralelo. Más rápido, bidireccional y ajustable en GPUs de consumo. Ideal para desarrolladores.
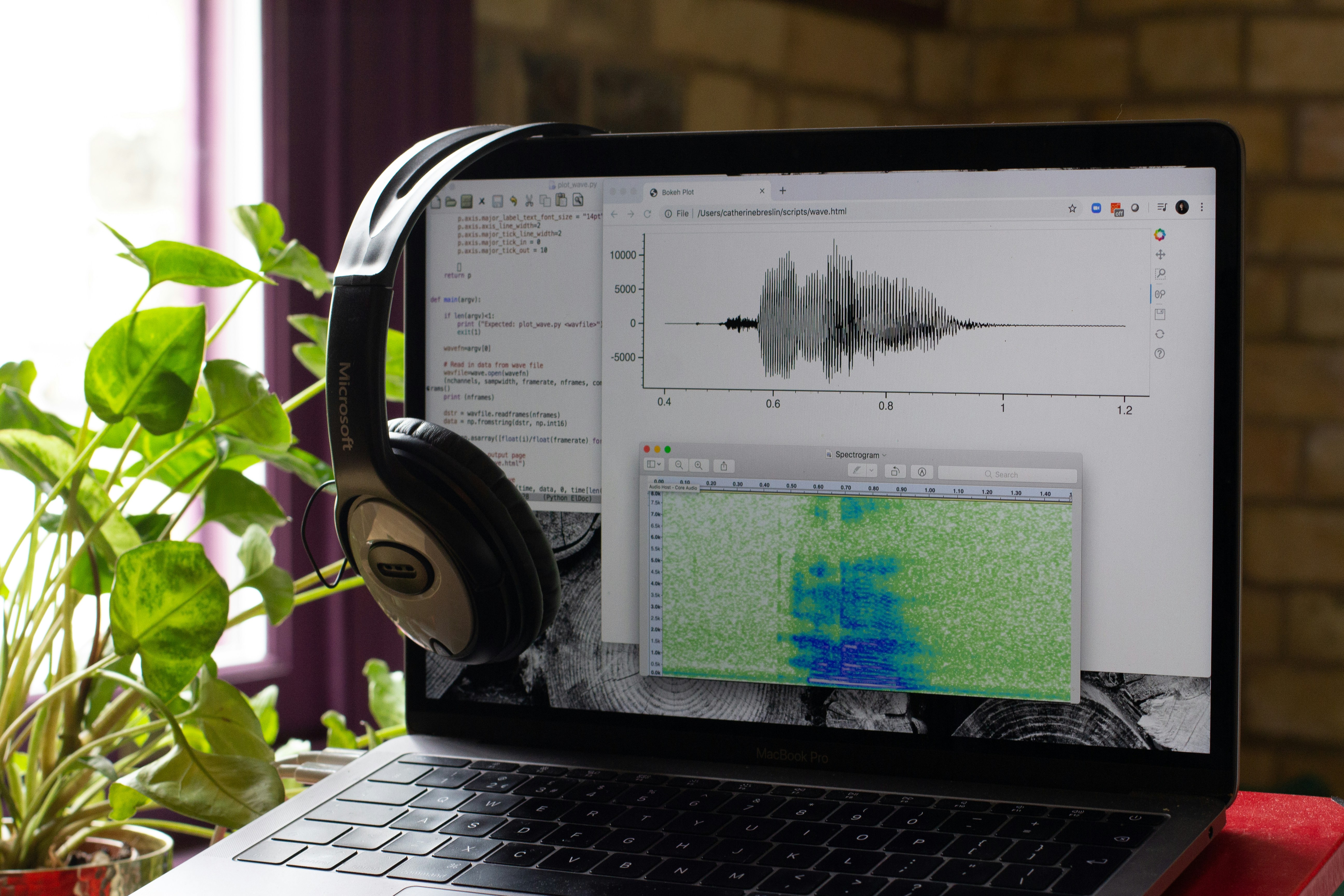
Descubre como los modelos multimodales combinan audio y video para decisiones. Las rutas internas de informacion en AVLLMs permiten inferencia eficiente.

Descubre cómo la cuantización de caché KV puede destruir la alineación de seguridad en LLMs y cómo PCR recupera hasta un 97% del daño en solo 35 minutos.

¿Quieres optimizar la inferencia offline de modelos grandes? BlendServe combina batching consciente de recursos y prefijo compartido logrando hasta 1.44x más rendimiento que vLLM y SGLang.

Descubre cómo la latencia de arranque en frío de vLLM afecta el rendimiento en inferencias escalables. Analizamos sus 6 fases y presentamos un modelo predictivo para optimizar recursos.
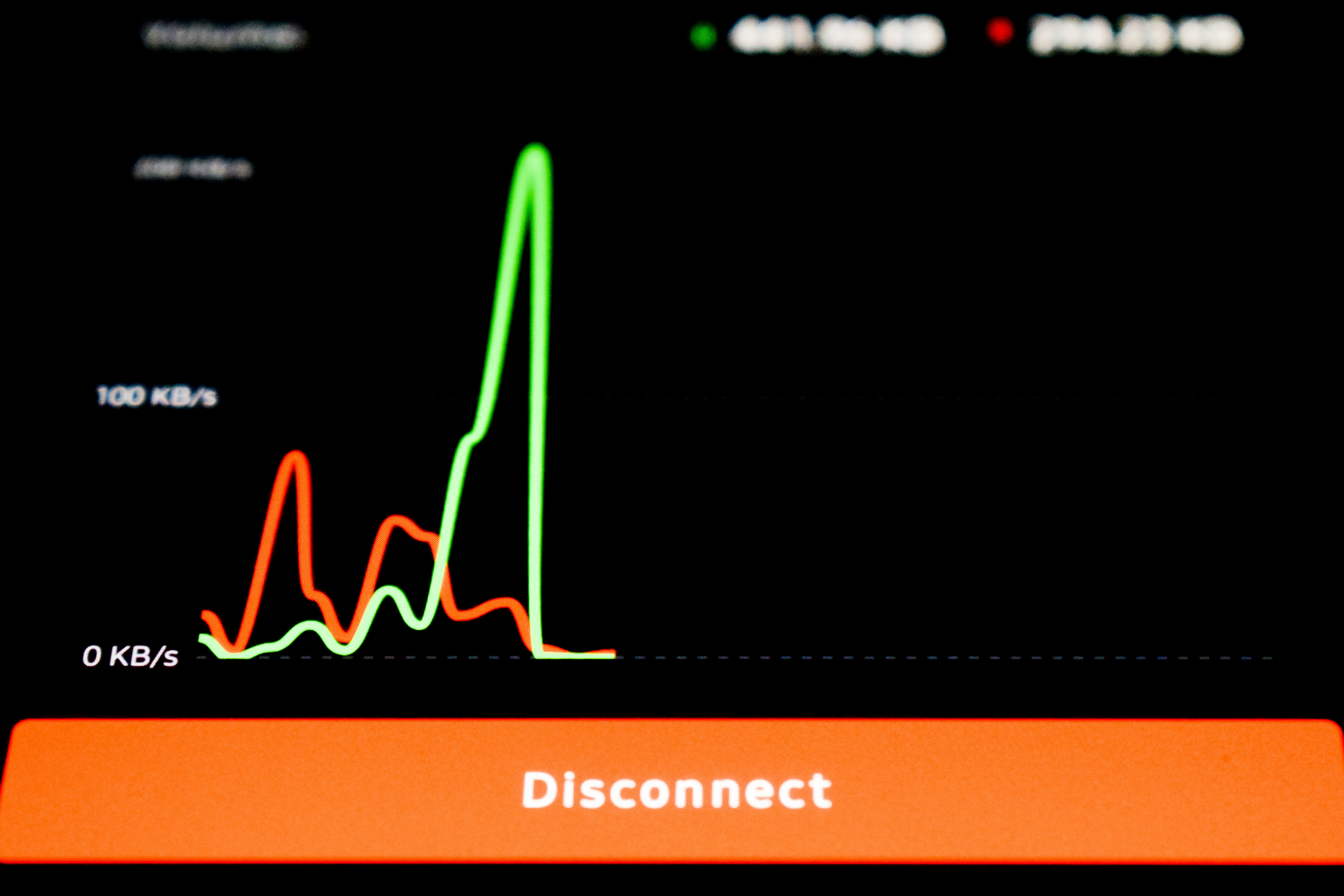
Descubre vLLM: latencia de arranque en frío en inferencia escalable. Análisis de seis pasos y modelo predictivo para optimizar recursos.

NVIDIA Dynamo Snapshot reduce el cold start de modelos de IA en Kubernetes hasta 21x. Checkpoint/restore con CRIU y CUDA para escalado elástico rápido.

Descubre cómo vLLM Semantic Router optimiza el enrutamiento de modelos multimodales mediante señales composables, mejorando costos, privacidad y seguridad.

Reduce errores en razonamiento con KVarN. Cuantificación KV de 2 bits que optimiza la memoria y mejora el rendimiento en modelos de lenguaje.

DriftSched optimiza la programación GPU multi-inquilino con compensación adaptativa de deriva de tokens, reduciendo latencia un 42% y mejorando QoS.

Descubre cómo llama.cpp b9455 iguala la velocidad de vLLM en 2x3090 con Qwen 27B. 70 t/s en decodificación y prefill ultrarrápido para agentes.