
Presentamos Pantheon: pruebas, no promesas
Descubre Pantheon, la blockchain soberana que hace verificable cada acción de IA. Pruebas, no promesas, ancladas a Bitcoin.
Descubre Pantheon, la blockchain soberana que hace verificable cada acción de IA. Pruebas, no promesas, ancladas a Bitcoin.

Descubre cómo ReSum, un nuevo marco de RL, mejora el razonamiento de LLMs un 4% y reduce el largo de las cadenas un 18.6% mediante auto-resúmenes.

CPPO mejora la estabilidad y precisión del razonamiento en LLMs al superar las regiones de confianza uniformes. Nuevo enfoque de optimización.

Descubre cómo TRACE asigna presupuesto de rollout a nodos prometedores en RL agente multi-turno, mejorando contraste de recompensas y rendimiento.

Descubre τ-Rec, un benchmark que evalúa sistemas de recomendación agentivos con recompensas verificables. Revela una brecha crítica en fiabilidad.

Descubre CoDaPO: un método que asigna pesos adaptativos por dificultad y confianza para mejorar el razonamiento en LLM con aprendizaje por refuerzo. Resultados en 12 benchmarks.

Descubre ConSteer-RL: un nuevo método que mejora el razonamiento de LLMs usando señales de confianza con RL. Resultados: hasta 4% de mejora.

Descubre cómo ConSteer-RL mejora el razonamiento de LLMs usando señales de confianza, logrando mejoras del 2.3% al 4%.

TinyJudge alinea modelos de lenguaje con restricciones no verificables usando conjuntos ligeros de especialistas. Logra un 10% de rendimiento y 3x velocidad.
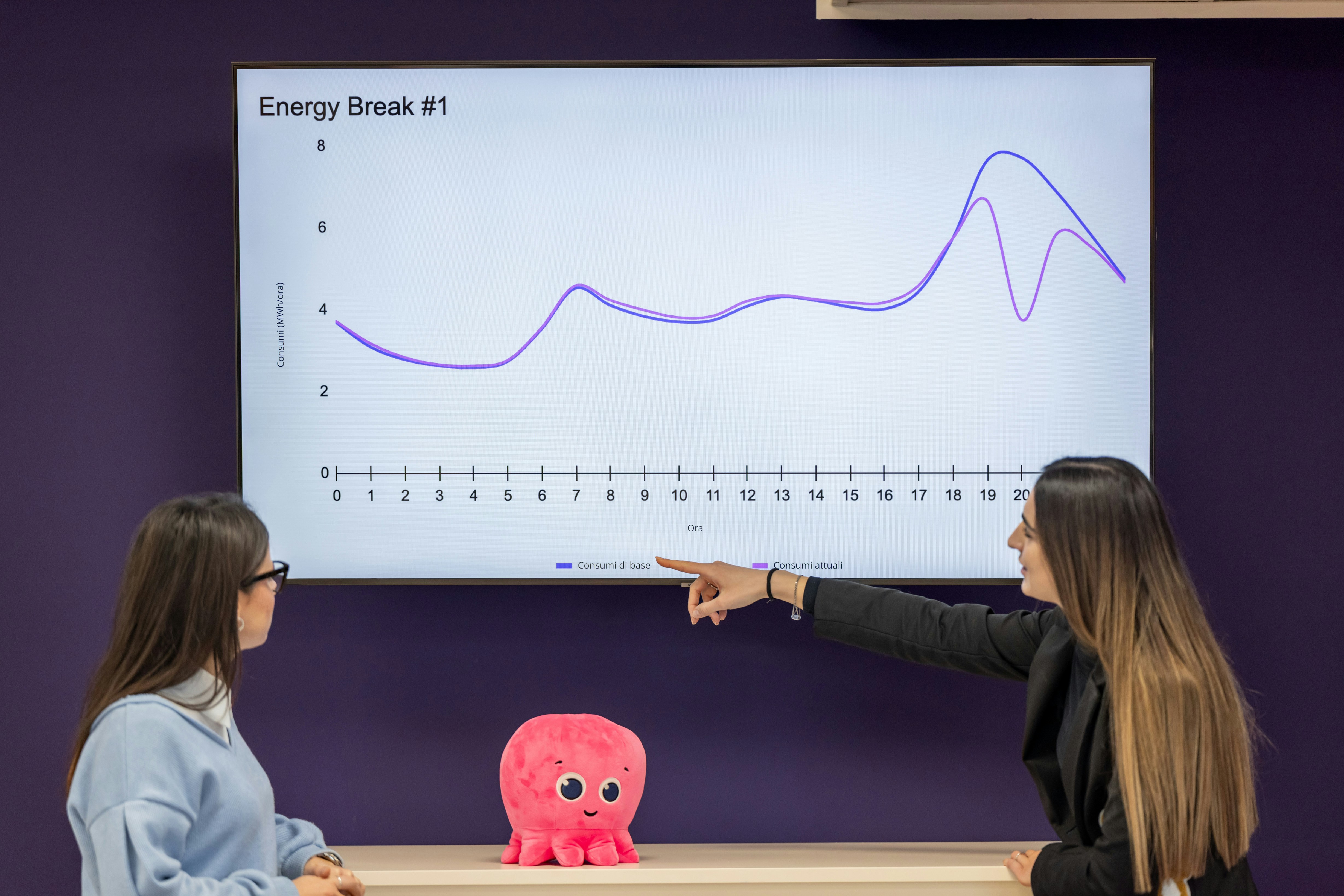
Descubre RLVE: una técnica que escala el aprendizaje por refuerzo para LLMs con entornos adaptativos, logrando un 3.37% de mejora en razonamiento con menos cómputo.

Descubre cómo CATPO revoluciona el aprendizaje por refuerzo con crítica aumentada, mejorando la precisión en LLMs hasta un 37.5% en benchmarks clave. Optimiza tus modelos.

Descubre cómo sGPO reduce a un tercio el costo de entrenamiento de RLVR intercambiando FLOPs de inferencia por eficiencia, sin perder rendimiento.
Descubre cómo PTD-PO optimiza políticas multimodales sin revelar respuestas, mejorando el razonamiento complejo.

Investigación revela que el estimador ingenuo en RLVR mezcla elicitación y diseño de recompensas. Un nuevo método de partición causal permite auditar resultados.

Descubre MDP-GRPO, un método que estabiliza GRPO bajo recompensas discretas, mejorando el cumplimiento de restricciones hasta un 5%. Ideal para IA confiable.

Descubre cómo MaxPO optimiza el post-entrenamiento de LLMs con una nueva línea base Leave-Two-Out que centra la ventaja y reduce la varianza del gradiente.

Descubre cómo las imágenes hardened reducen hasta un 95% de vulnerabilidades en contenedores. Menos paquetes, menor riesgo, transparencia con SBOM.

Descubre cómo PivotTrace logra un rendimiento casi total con solo el 29% de datos etiquetados y una convergencia 2.75 veces más rápida en RLVR.

GeoMin optimiza RLVR semi-supervisado usando modelado geométrico. Logra +4.1% sobre los mejores y supera la supervisión completa con solo el 10% de datos etiquetados.

Descubre cómo el nuevo método de replay priorizado por ventaja mejora la eficiencia muestral en GRPO para LLMs, logrando +4.35% en benchmarks.