
ThoughtFold: Plegado de Cadenas de Razonamiento con Aprendizaje Introspectivo
Descubre ThoughtFold, un framework que elimina exploraciones redundantes en modelos de razonamiento, reduciendo tokens hasta un 56% sin perder precisión.
Descubre ThoughtFold, un framework que elimina exploraciones redundantes en modelos de razonamiento, reduciendo tokens hasta un 56% sin perder precisión.

CAST optimiza el RLVR con autoenseñanza no privilegiada y asignación de ventajas token en grupos de varianza cero. Mejora el razonamiento.
Descubre cómo el fuzzing de verificadores RLVR revela bugs antes de que el modelo los aprenda. Mejora la seguridad de tu IA con métricas clave.

POPO elimina muestras ineficaces acelerando el fine-tuning de LLM para razonamiento matemático, planificación y geometría visual con menos rollouts.

Descubre cómo CARE-RL mitiga conflictos entre dominios en LLMs con aprendizaje por refuerzo consciente de capacidades, con resultados superiores en benchmarks.
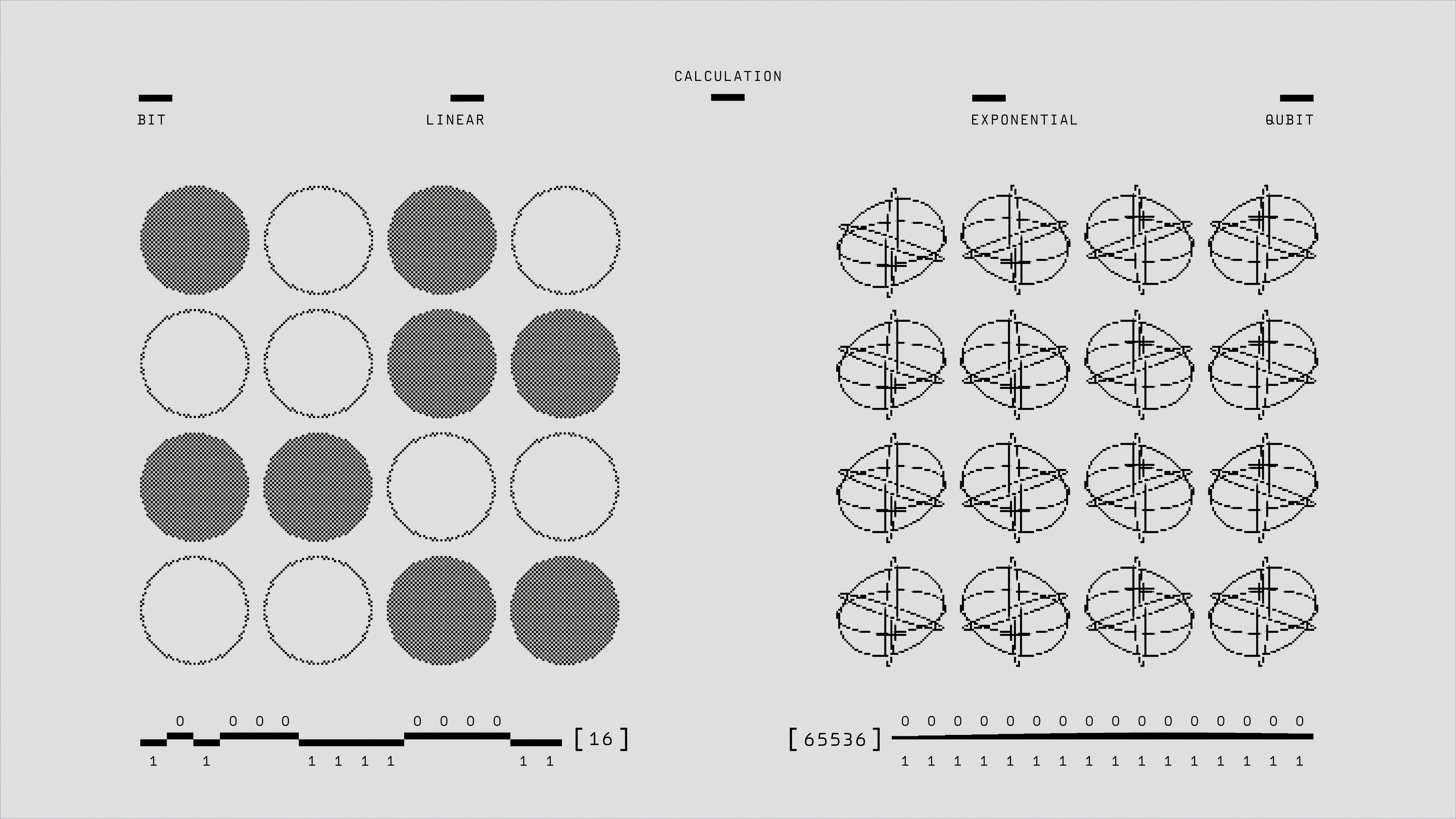
TRON genera instancias verificables bajo demanda para entrenar modelos de razonamiento visual con RL, mejorando benchmarks multimodales.

LongTraceRL mejora el razonamiento en contexto largo usando recompensas de rúbrica y distractores por niveles desde trayectorias de agentes de búsqueda.

Softmax Recocido logra arrepentimiento casi óptimo en bandidos Bayesianos, explicando por qué GRPO funciona sin incertidumbre explícita.

EchoRL identifica EchoClips en rollouts exitosos para proporcionar supervisión auxiliar y mejorar el aprendizaje por refuerzo en LLMs, superando la degeneración de ventajas.