Mejora de precisión con fidelidad de ruta escalar en potenciales interatómicos
Descubre cómo la fidelidad de ruta escalar reduce errores en potenciales interatómicos en un 22-27% con solo 5% extra de costo.
Descubre cómo la fidelidad de ruta escalar reduce errores en potenciales interatómicos en un 22-27% con solo 5% extra de costo.

Optimiza modelos sin gradientes completos: conoce SILAGE, el algoritmo que ahorra memoria y acelera el entrenamiento.

Descubre cómo la fidelidad de trayectoria escalar reduce errores en potenciales interatómicos equivariantes, mejorando precisión en fuerzas y energía.

Descubre GENIE, un optimizador que usa el ratio OSGR para equilibrar actualizaciones de parámetros y mejorar la generalización a dominios no vistos. Supera a

Protege tu privacidad en inferencia de LLM con transformadores equivariantes ortogonales. Reduce recuperación de tokens del 35% al 1.3% sin aumentar

Tres invariantes matemáticos (números de Betti, brecha espectral y torsión analítica) capturan la esencia del Laplaciano persistente para aprendizaje eficiente.

Descubre cómo NEXIS identifica efectos causales de intervenciones usando imágenes satelitales para optimizar políticas contra la pobreza.
Mejora la predicción de series temporales en grafos con elipsoides conformales filtrados: cobertura adaptativa sin asumir normalidad, ideal para tráfico y

Descubre SN-VI, un nuevo marco de inferencia variacional que modela dependencias latentes sin suposiciones de campo medio. Mejora la precisión en modelos
VarDeepPCA es un plugin DNN variacional sin muestreo que restaura segmentaciones médicas OOD, ofreciendo incertidumbre con pequeños conjuntos de datos.

Aprende cómo los flujos normalizadores reducen la varianza en QCD de retículo hasta tres órdenes de magnitud, mejorando estimadores de correlación.
Descubre cómo Helmholtz-SDE cierra la brecha de aproximación en SDEs latentes sin simulación, logrando inferencia precisa y rápida. Ideal para sistemas
Descubre cómo el modelado generativo identifica variables clave en gemelos digitales, reduciendo complejidad y creando sustitutos interpretables para control.

Descubre cómo el marco VPINN Petrov-Galerkin resuelve con alta precisión problemas bidimensionales singularmente perturbados, capturando capas límite afiladas.

Resuelve problemas singularmente perturbados en 2D con el marco VPINN Petrov-Galerkin. Alta precisión y robustez.

El Markov VAE contextual mejora la compresión de CSI en MIMO masivo con retroalimentación limitada. Resultados muestran mejoras significativas.
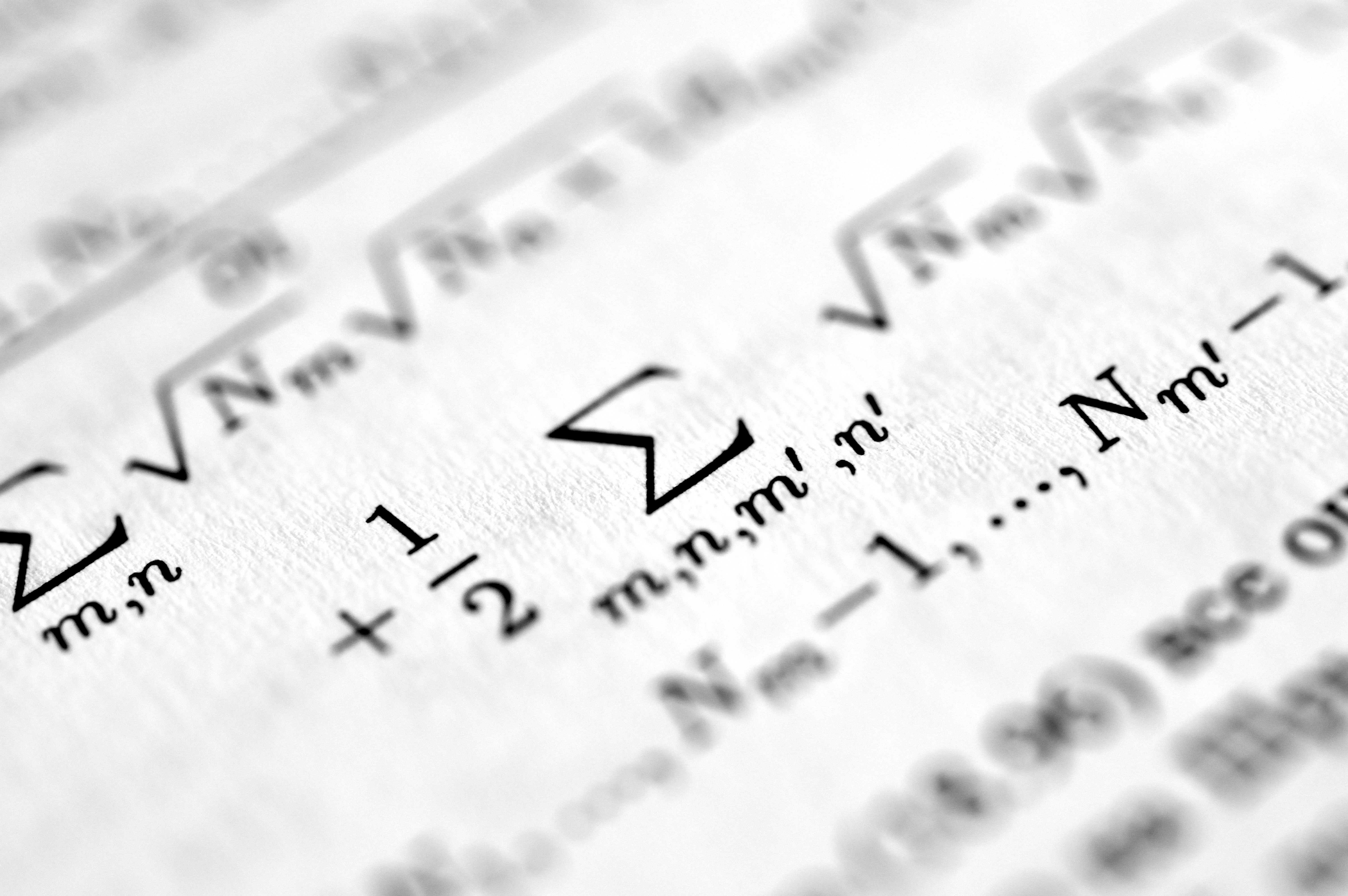
Descubre cómo el teorema de Buckingham permite identificar grupos adimensionales automáticamente desde datos, combinando física y machine learning.

Descubre cómo el teorema Pi de Buckingham y el aprendizaje automático encuentran grupos adimensionales a partir de datos. Ejemplo con compresor.
Descubre cómo el análisis de espacios de formas revela patrones ocultos en datos geométricos. Revisión matemática para científicos de datos.

Descubre cómo las redes neuronales ReLU pueden ser caracterizadas mediante ecuaciones polinómicas y variedades algebraicas, revelando su expresividad y