
Detección de suplantación: comparativa extractores SSL y clasificadores backend
Descubre cómo el sesgo de dominio en ASVspoof 5 afecta la detección de suplantación y cómo 8 horas de datos en el idioma objetivo mejoran la robustez.
Descubre cómo el sesgo de dominio en ASVspoof 5 afecta la detección de suplantación y cómo 8 horas de datos en el idioma objetivo mejoran la robustez.

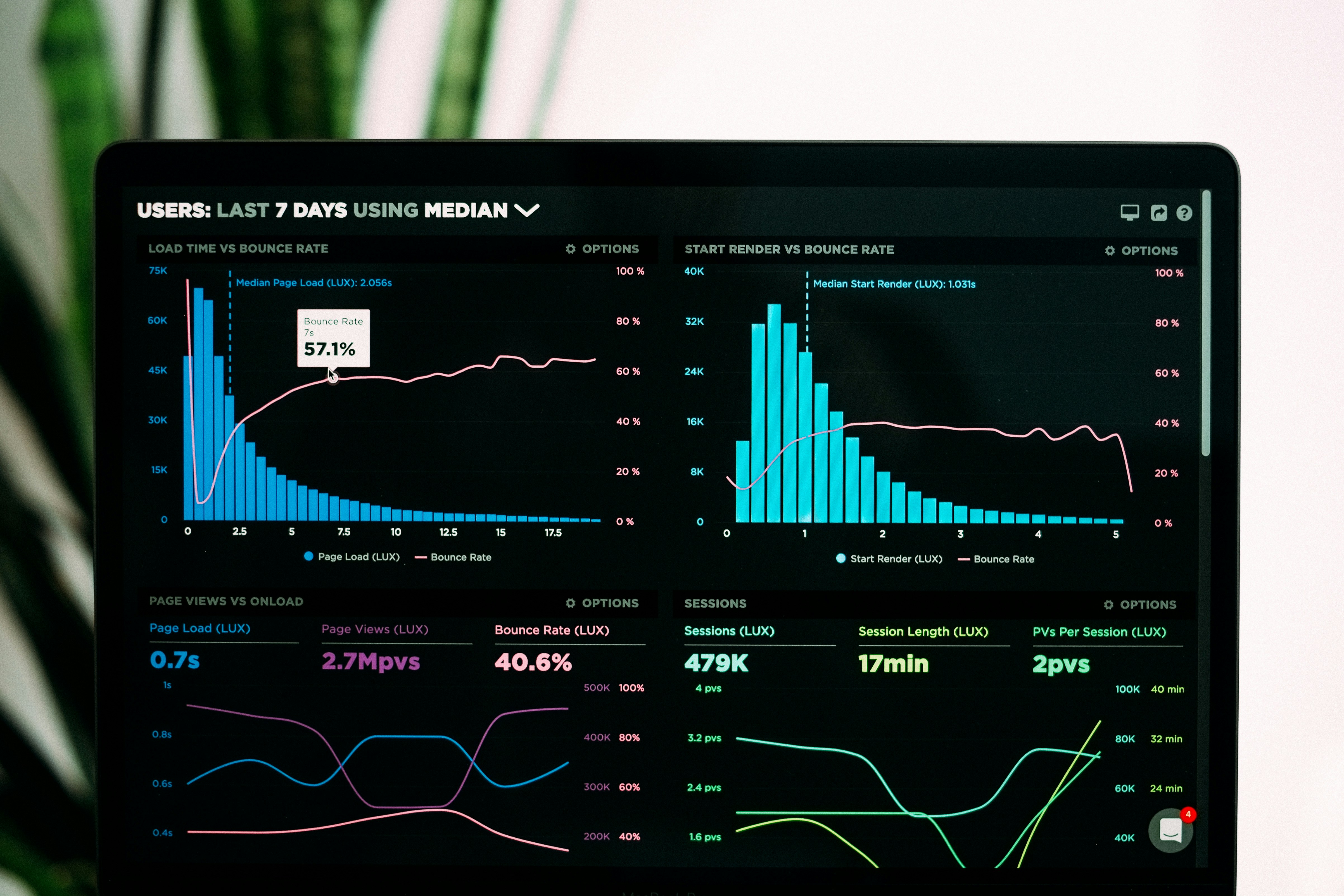
Descubre cómo nuestro modelo de detección de suplantación reduce un 25.7% el error al eliminar el sesgo del hablante, sin usar etiquetas de identidad.

Descubre cómo el moldeado de recompensas desde la perspectiva del juego de Stackelberg mejora la alineación de LLMs en inferencia, reduciendo sesgos y aumentando el rendimiento.
Descubre cómo las predicciones afectan su propio resultado. Analizamos el equilibrio entre cambiar el mundo y aprender de él con nuevos límites de generalización.

Estudio revela cómo el contexto modifica geométricamente las representaciones de verdad en LLMs. Cambios direccionales y de magnitud separan verdad de falsedad.

Descubre cómo XCR-Bench evalúa la capacidad de los LLMs para razonar entre culturas, revelando sesgos ocultos en modelos avanzados.
Explora cómo la estructura de los datasets impulsa el diseño de arquitecturas de video: de redes de dos flujos a modelos multimodales. Una guía para entender el

Descubre LCAM: diagnostica fallos de alineación interaccional en IA conversacional. Evalúa ética, confianza y empatía. Ideal para auditores y desarrolladores.

Mejora tus embeddings de texto eliminando el sesgo medio con renormalización refinada. Resultados en 38 modelos MMTEB muestran ganancias en clasificación.

FADTI: imputación de series temporales con Fourier y atención. Supera a modelos previos en datos faltantes. Ideal para salud, tráfico y biología. ¡Descúbrelo!

Descubre cómo detectar alineación propietaria en modelos de lenguaje sin un estándar de referencia. Un marco comparativo para auditar sesgos y políticas ocultas.

¿Son fiables los LLM? Estudio revela que el historial de interacción sesga la calificación de tesis con GPT y Grok.

Las comparaciones por pares con Elo generan rankings de precisión casi perfectos en modelos de IA, minimizando sesgos de estilo y juez. ¡Descúbrelo!

Descubre cómo el debate adversarial entre modelos con principios reduce la sicofanía en LLMs, logrando hasta un 53% de precisión con arbitraje ciego.

Descubre cómo el ajuste secuencial ofrece una nueva visión sobre el sesgo espectral en redes neuronales, más allá del análisis de Fourier tradicional.

Descubre cómo tratar la equidad como operación de simetría reduce sesgos en modelos de IA hasta un 90% con solo un 5% de pérdida de precisión.

La IA está homogeneizando la creatividad en internet. Descubre cómo evitar el 'slop' y crear contenido original que realmente conecte con tu audiencia.

Estudiar la dinámica del entrenamiento, no solo arreglar en postproducción. Descubre cómo predecir, intervenir y diseñar mejores sistemas de IA.

Descubre cómo los LLMs generan sesgo racial en la búsqueda de vivienda según identidad del usuario y ciudad. Estudio revela riesgos para vivienda justa.

¿Confías en la IA para etiquetar ideología? Un estudio revela que el fine-tuning crea sesgos ocultos. Descubre las implicaciones.