
Contraste y sesgo inductivo: cómo separar ruido lento de dinámicas
Descubre cómo el aprendizaje contrastivo puede confundir ruido lento con la dinámica real, y cómo muestrear negativos dentro de la misma trayectoria mejora las representaciones.
Descubre cómo el aprendizaje contrastivo puede confundir ruido lento con la dinámica real, y cómo muestrear negativos dentro de la misma trayectoria mejora las representaciones.
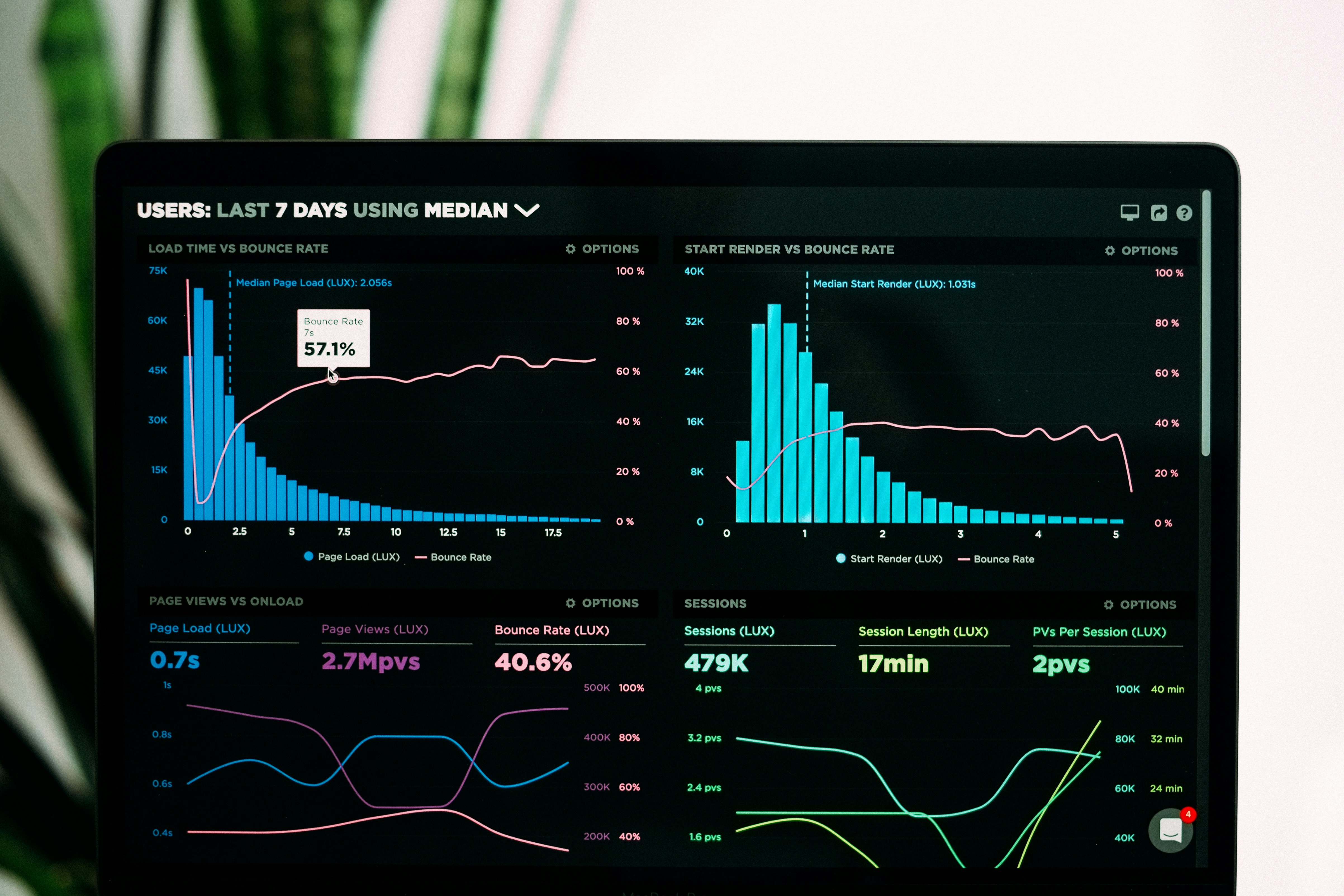
Descubre cómo la predicción parcialmente performativa aborda cambios de distribución endógenos y exógenos en modelos predictivos. Aprende heurísticas prácticas para adaptarte.
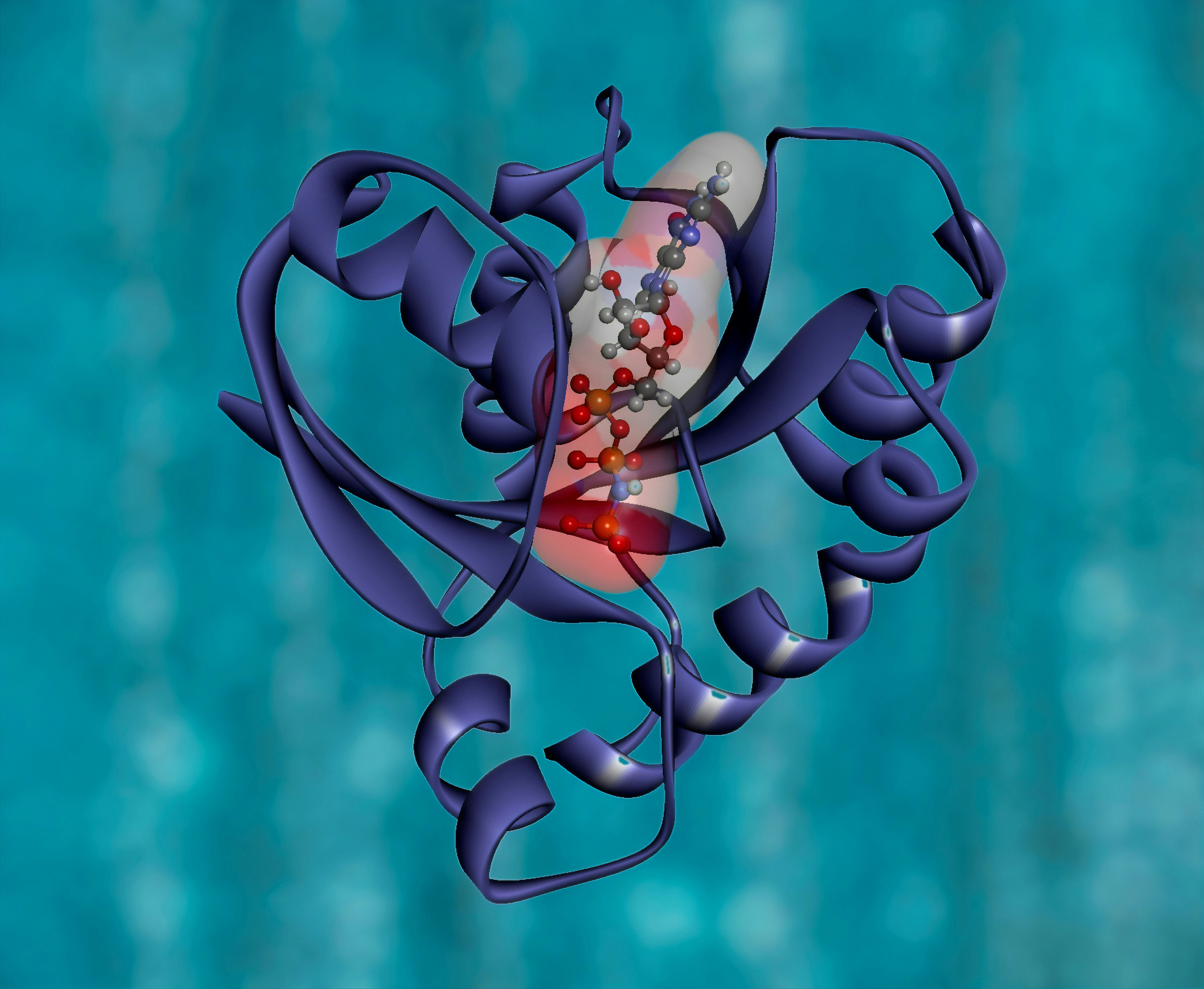
Nuevo marco de optimización con restricciones mejora la predicción de estabilidad proteica, elevando correlación Spearman sin cambios arquitectónicos.

Descubre CROTS, una nueva clase de espacios métricos que evalúa no solo la distancia entre distribuciones sino la dirección del transporte, clave para aprendizaje fiable con restricciones.

Descubre TRUST-SCF, un framework basado en transformers que mejora la puntuación crediticia y predicción de riesgo en financiamiento de cadenas de suministro.
Exploramos la dinámica espectral y geometría del ruido del optimizador Muon: su sesgo hacia espectro plano y cuándo es útil frente a AdamW. Resultados experimentales.
Muon reemplaza el gradiente por su factor polar, aplanando el espectro. Descubre cómo este sesgo mejora la optimización en ciertos regímenes, y cuándo AdamW es mejor.

La auditoría espectral revela dependencia aperiódica según la tarea en EEG y ECG. ¡Controla el sesgo en tu IA!

La geometría del espacio de parámetros de transformers revela por qué fallan en funciones booleanas sensibles como PARITY: un sesgo hacia baja sensibilidad.
PROBE-Web: sistema interactivo para evaluar modelos de completado de grafos de conocimiento. Ajusta perspectivas de nitidez y sesgo de popularidad. ¡Explora paisajes de evaluación!

DynaCF reduce el aprendizaje superficial en modelos de recompensa mediante reajuste dinámico con contrafácticos, mejorando robustez y calidad de preferencias.

Janus audita fallos en modelos de lenguaje: calibra con señuelos y replica en datos nuevos para confirmar solo los errores genuinos. Descubre el método.

Descubre cómo PRISM elimina el sesgo oculto en los PRM, mejorando la precisión del razonamiento y reduciendo falsos positivos en un 22%.

Descubre cómo los modelos de lenguaje mantienen prioridades léxicas al ser anuladas, según estudio con paradigma Stroop. Implicaciones para IA.

Descubre cómo la falta de etiquetas protegidas afecta las auditorías de equidad en ML. Resultados revelan patrones de daño interseccional y la necesidad de calibración.

Descubre cómo el marco BGPS automatiza la búsqueda de prompts para exponer sesgos ocultos en modelos de texto a imagen como Stable Diffusion.
Descubre cómo lograr una agregación justa de etiquetas ruidosas en crowdsourcing usando restricciones de paridad demográfica. Teoría, algoritmos y experimentos.

Descubre cómo Shortcut Guardrail mitiga atajos en modelos de texto durante el despliegue sin datos de entrenamiento. Recupera rendimiento en clasificación, toxicidad e inferencia.

Cómo las variables sombra débiles de modelos preentrenados permiten acotar estimaciones con datos faltantes, reduciendo sesgo y mejorando precisión

Aprende a generalizar la selección justa de top-k con múltiples grupos protegidos, minimizando la disparidad. Un enfoque integrador con resultados empíricos.