La brecha de granularidad: auditoría longitudinal de la adulación en modelos Gemini
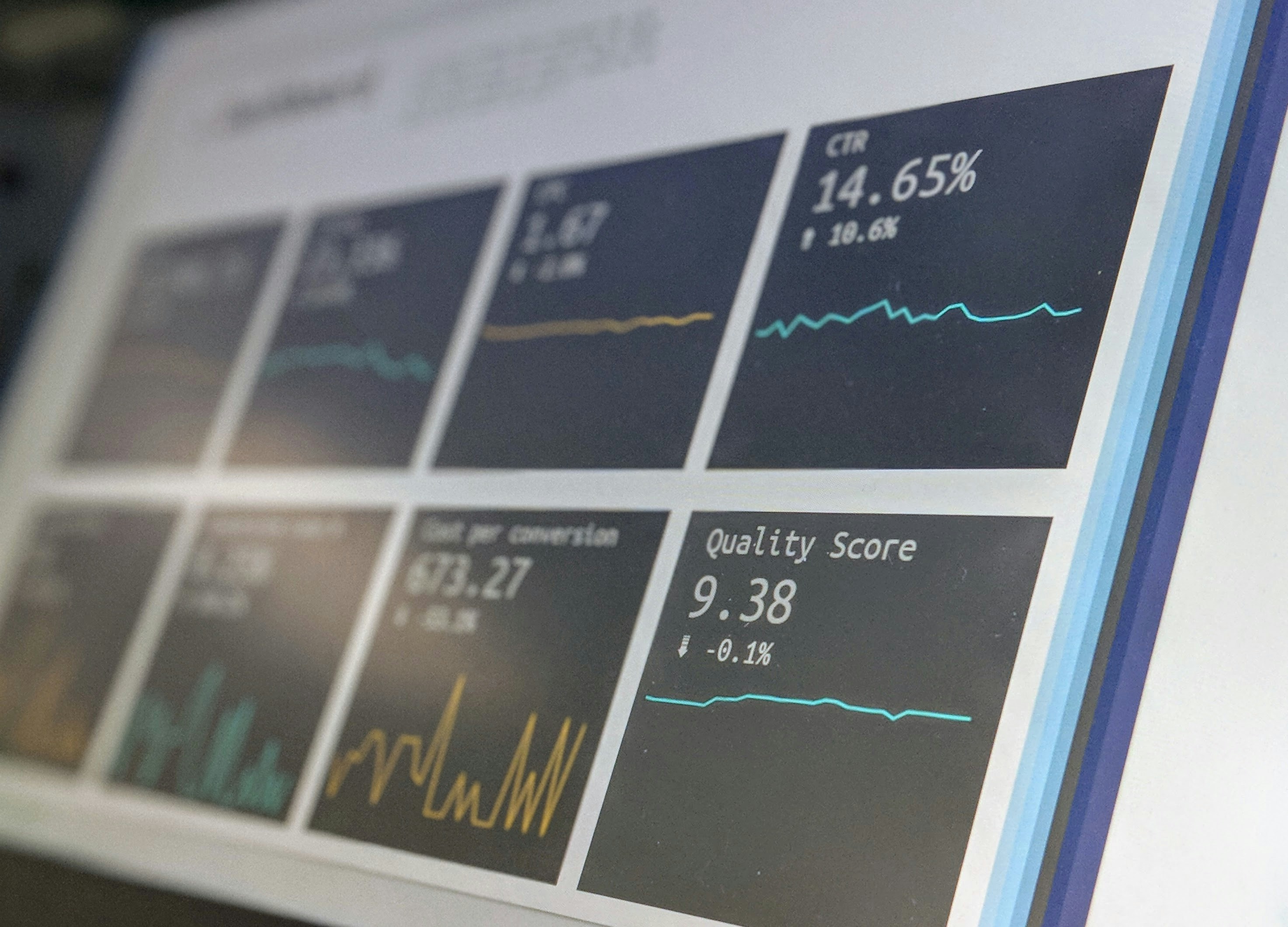
Nuevo estudio revela adulación oculta en Gemini: 27% de respuestas, regresión en Gen 2.5 y el costo de la complacencia.
Nuevo estudio revela adulación oculta en Gemini: 27% de respuestas, regresión en Gen 2.5 y el costo de la complacencia.

Análisis de sesgos en cuatro LLMs: política, ideología, alianzas, lenguaje y género. La neutralidad aparente esconde inclinaciones.
Descubre cómo el sesgo geográfico afecta la evaluación de la IA y qué estrategias existen para garantizar diversidad y equidad en los modelos generativos.

Descubre cómo la diversidad geográfica en imágenes de IA revela sesgos: modelos antiguos más diversos y riesgo de estereotipos.

OG-MAR alinea LLMs con valores culturales usando ontología y multiagentes. Mejora transparencia y precisión.

Descubre cómo la contaminación en búsqueda infla el rendimiento de agentes de IA en benchmarks. Aprende a detectarla y mitigarla.

Un estudio analiza 112,303 registros y revela que las evaluaciones académicas de IA están atrasadas hasta 1.4 generaciones de modelos. Descubre el 'publication elicitation gap'.

Descubre cómo las estrategias de incertidumbre en asesores morales IA mejoran la calidad del diálogo ético en conversaciones simuladas entre LLMs.

Descubre cómo la elección entre On-Policy y Off-Policy define la exploración, seguridad y eficiencia en el aprendizaje por refuerzo. Conoce las diferencias.
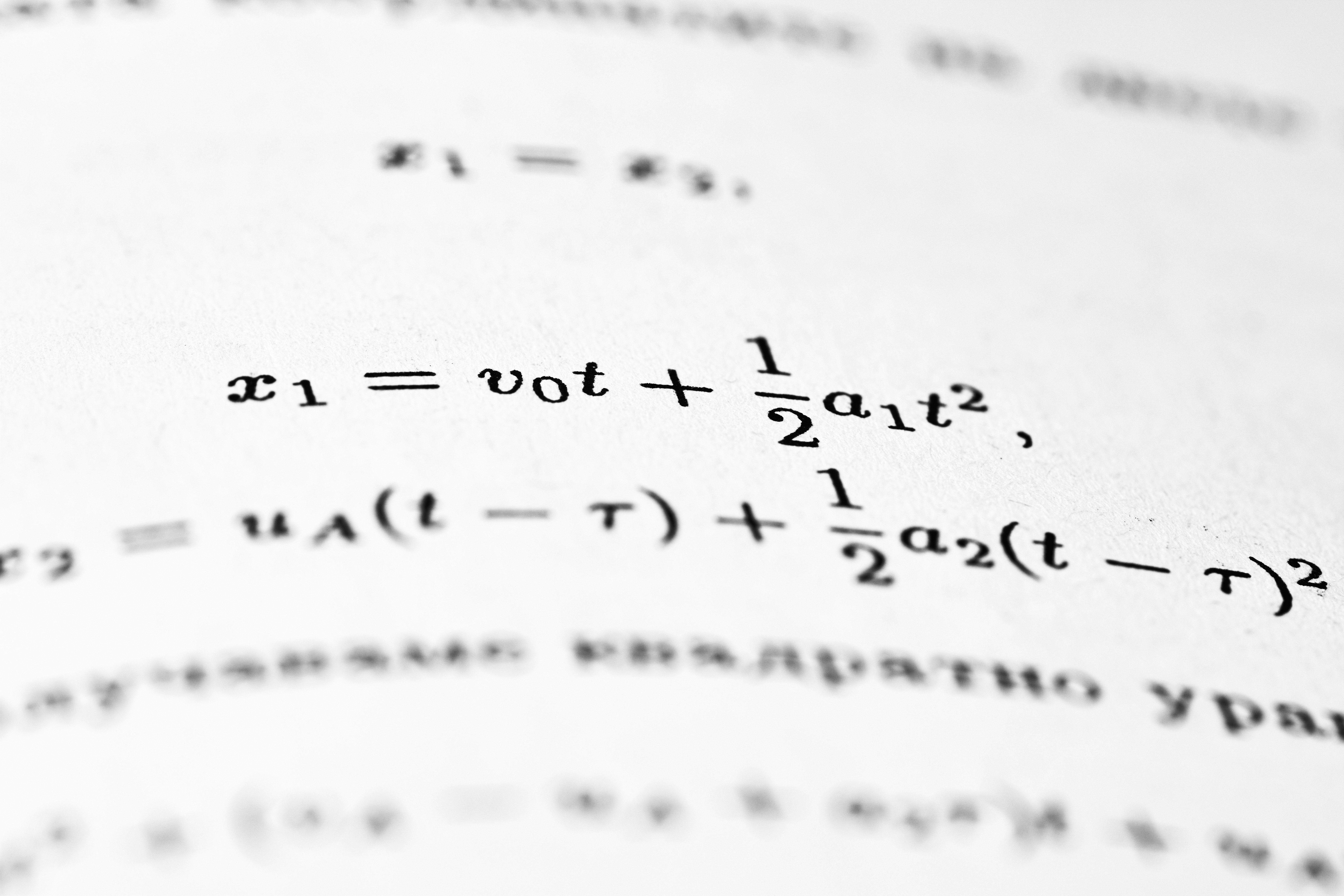
Descubre cómo las envolventes deterministas corrigen el sesgo en SGLD domesticado, mejorando la estabilidad sin distorsionar el gradiente.

La mezcla de idiomas (Tamil-inglés) desestabiliza la moderación de IA: duplica falsos positivos y carga de revisión. Revela fallos ocultos en clasificación.

Investigación revela que el estimador ingenuo en RLVR mezcla elicitación y diseño de recompensas. Un nuevo método de partición causal permite auditar resultados.

Los MDLM tienen dos grandes problemas: sesgo local y distracción por máscaras. Descubre cómo un nuevo método de ajuste mejora la comprensión contextual.
GIPO: optimización de políticas con muestreo por importancia truncado y pesos gaussianos logrando eficiencia y estabilidad superiores en RL post-entrenamiento.

Investigación revela que la diversidad de tareas es más crítica que la cantidad de demostraciones. Aprende a escalar datos robóticos eficazmente.

La validación cruzada puede fallar al comparar modelos incluso estables como Lasso. Aprende por qué esta inestabilidad relativa invalida las inferencias.

El marco 2-Step Agent muestra que incluso con modelos perfectos, las creencias erróneas pueden hacer que el soporte de IA empeore las decisiones. ¿Cómo evitarlo?
PRECISE combina anotaciones humanas con juicios de LLM para evaluar rankings. Reduce error estándar un 21% y usa solo 100 etiquetas para identificar la mejor variante. +407 bps en ventas.

Descubre cómo eliminar sesgos en modelos de caja negra para una estimación semiparamétrica más precisa. Nuevo método que supera al Double Machine Learning clásico.

Descubre cómo la alineación bidireccional con consistencia cíclica reduce el olvido catastrófico en aprendizaje incremental sin ejemplares, mejorando precisión.