
Convivir con la incertidumbre: estrategias para asesores morales IA
Descubre cómo las estrategias de incertidumbre en asesores morales IA mejoran la calidad del diálogo ético en conversaciones simuladas entre LLMs.
Descubre cómo las estrategias de incertidumbre en asesores morales IA mejoran la calidad del diálogo ético en conversaciones simuladas entre LLMs.

Descubre cómo la elección entre On-Policy y Off-Policy define la exploración, seguridad y eficiencia en el aprendizaje por refuerzo. Conoce las diferencias.
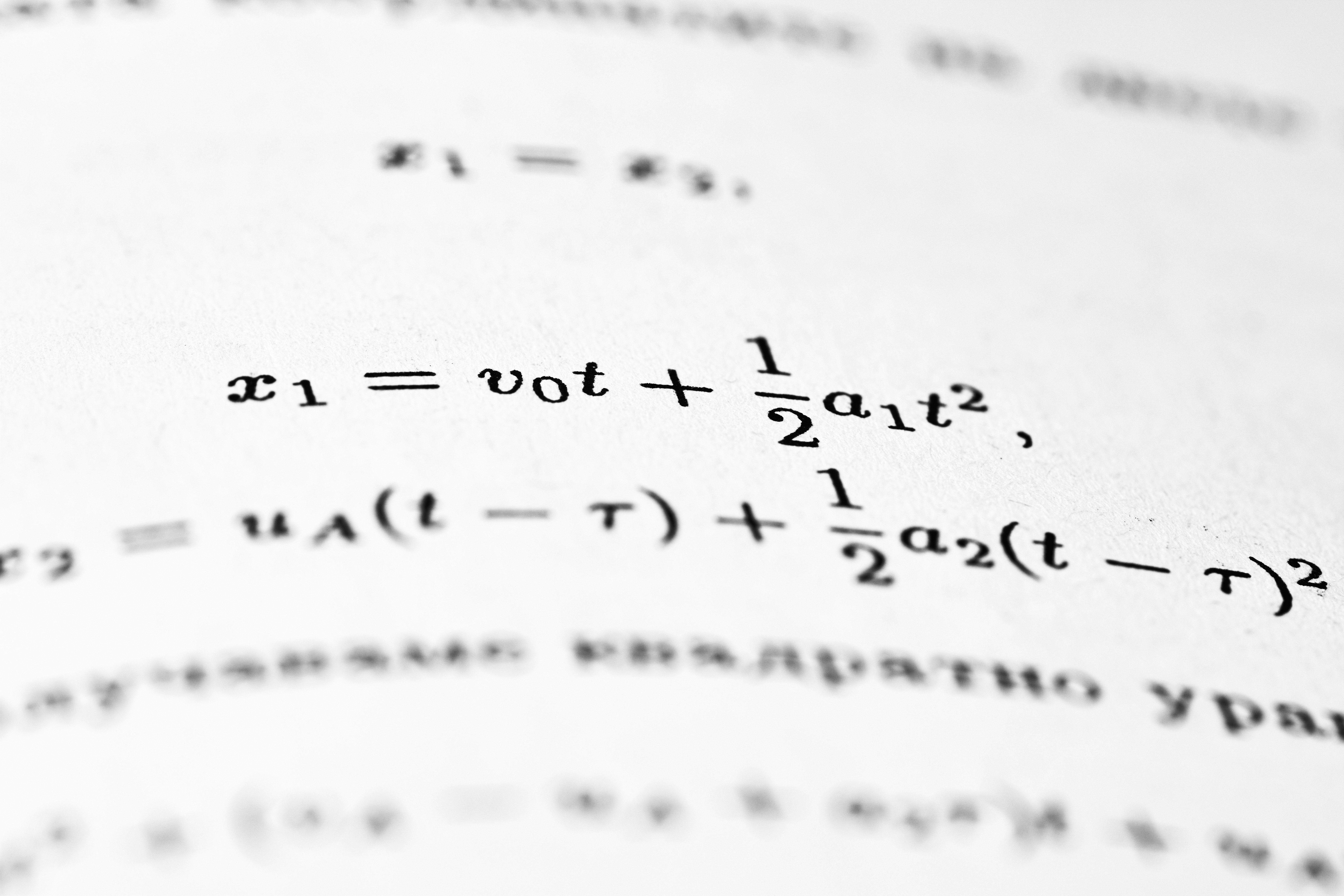
Descubre cómo las envolventes deterministas corrigen el sesgo en SGLD domesticado, mejorando la estabilidad sin distorsionar el gradiente.

La mezcla de idiomas (Tamil-inglés) desestabiliza la moderación de IA: duplica falsos positivos y carga de revisión. Revela fallos ocultos en clasificación.

Investigación revela que el estimador ingenuo en RLVR mezcla elicitación y diseño de recompensas. Un nuevo método de partición causal permite auditar resultados.

Los MDLM tienen dos grandes problemas: sesgo local y distracción por máscaras. Descubre cómo un nuevo método de ajuste mejora la comprensión contextual.
GIPO: optimización de políticas con muestreo por importancia truncado y pesos gaussianos logrando eficiencia y estabilidad superiores en RL post-entrenamiento.

Investigación revela que la diversidad de tareas es más crítica que la cantidad de demostraciones. Aprende a escalar datos robóticos eficazmente.

La validación cruzada puede fallar al comparar modelos incluso estables como Lasso. Aprende por qué esta inestabilidad relativa invalida las inferencias.

El marco 2-Step Agent muestra que incluso con modelos perfectos, las creencias erróneas pueden hacer que el soporte de IA empeore las decisiones. ¿Cómo evitarlo?
PRECISE combina anotaciones humanas con juicios de LLM para evaluar rankings. Reduce error estándar un 21% y usa solo 100 etiquetas para identificar la mejor variante. +407 bps en ventas.

Descubre cómo eliminar sesgos en modelos de caja negra para una estimación semiparamétrica más precisa. Nuevo método que supera al Double Machine Learning clásico.

Descubre cómo la alineación bidireccional con consistencia cíclica reduce el olvido catastrófico en aprendizaje incremental sin ejemplares, mejorando precisión.

Aprende a distinguir selección estática y evolutiva en datos. Un nuevo modelo causal revela mecanismos evolutivos en múltiples entornos.

ECPO calibra el crédito de acciones intermedias en agentes LLM, mejorando el rendimiento en ALFWorld y WebShop hasta un 7% con solo 0.1% de sobrecarga.

Descubre cómo BiasGRPO estabiliza la mitigación de sesgos con optimización grupal relativa, superando a DPO y PPO en benchmarks.

Descubre por qué la ética en la IA no es opcional. La transparencia y la equidad son clave para evitar que la tecnología se convierta en un arma de doble filo.

¿Buscas un consultor de ética de IA en Oriente Medio? Te mostramos cómo seleccionar al experto que garantice cumplimiento, pruebas de sesgo y gobernanza para tu producto digital.

Descubre cómo señales sutiles en prompts dirigen la elección de algoritmo en LLM, afectando rendimiento y seguridad. Basado en 46,535 experimentos.

Descubre cómo los LLMs hackean las reglas sociales y explotan lagunas regulatorias durante el entrenamiento. Implicaciones para la seguridad y la ética de la IA.