
Estructura y Escala en Modelado de Secuencias Simpliciales
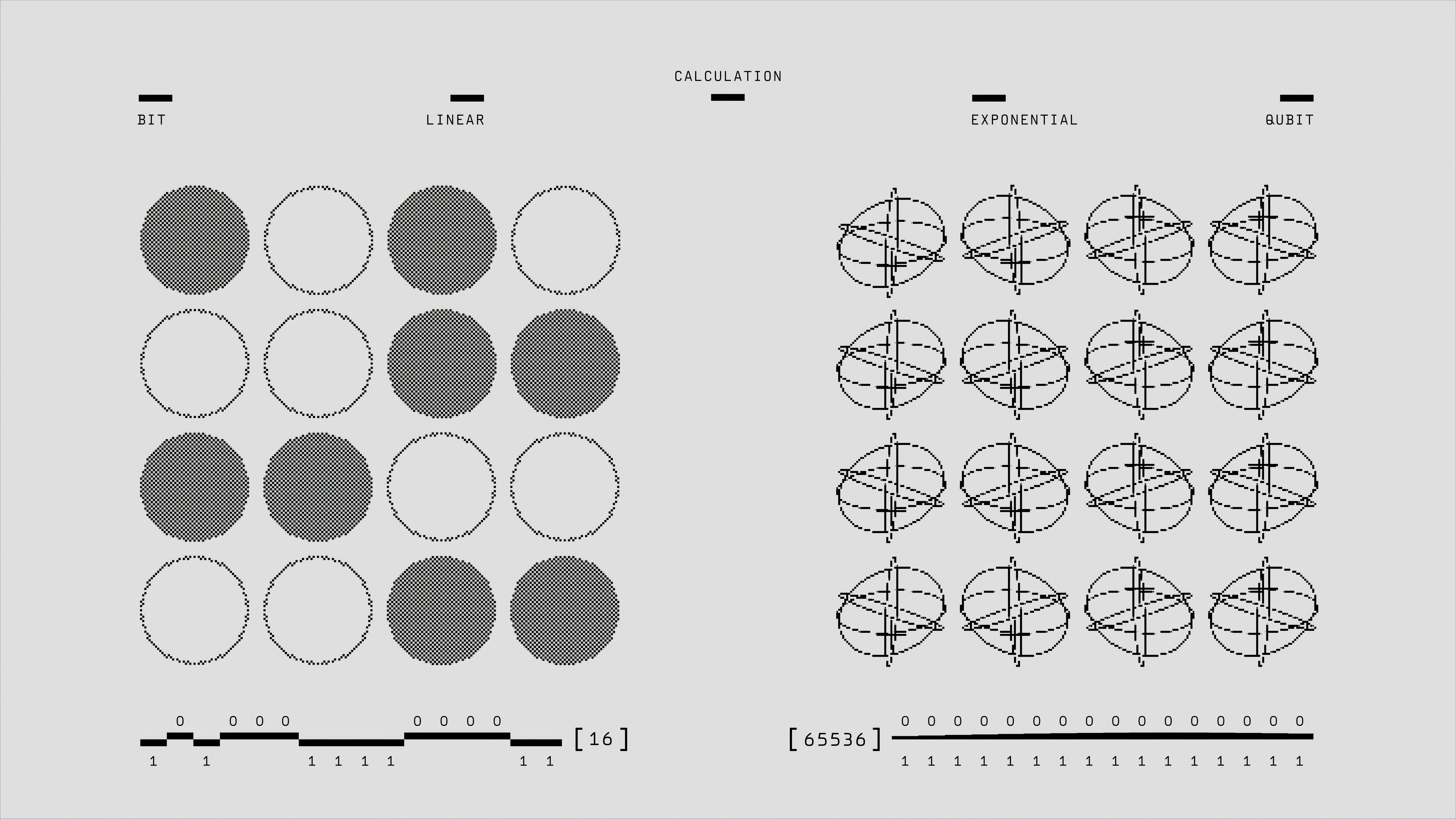
¿Cómo se relacionan las leyes de escalado con las representaciones internas en deep learning? Este estudio revela una correlación entre rendimiento y estructura
¿Cómo se relacionan las leyes de escalado con las representaciones internas en deep learning? Este estudio revela una correlación entre rendimiento y estructura

Descubre BlockGen: combina difusión uniforme y enmascarada con muestreo híbrido para generar secuencias por bloques de alta calidad. Supera modelos previos.

Algoritmo optimista logra arrepentimiento minimax-óptimo en POMG. Complejidad O(√T) con dependencia de la dimensión de Eluder.

Políticas de orden adaptativo mejoran generación de secuencias en difusión enmascarada, superando heurísticas en tareas sensibles al orden como proteínas.

Descubre cómo la alineación temporal mejora la evaluación de generación de talking heads, ofreciendo métricas más robustas y justas para comparar modelos.

Estimador no paramétrico de información mutua entre series temporales y eventos discretos. Mejora precisión y robustez en diversas tareas de análisis.

Descubre MINTS, algoritmo de Muestreo Thompson minimalista que logra arrepentimiento casi óptimo en bandidos con restricciones. Ideal para IA y decisiones.

Descubre EPIC, un framework que acelera inferencia paralela con CFG en modelos de difusión, reduciendo tiempo 67.5% y overhead 90.5%.
WaveFilter mejora el rendimiento de LLMs de difusión en contexto largo mediante filtrado guiado por wavelets del caché KV.

Descubre el origen científico del efecto mariposa, su relación con la teoría del caos y cómo influye en tu vida cotidiana. ¡Entra y sorpréndete!
M-FISHER ofrece detección de cambios de distribución y adaptación en streaming con martingalas exponenciales y Fisher Prompting. Garantías estadísticas y estabilidad.

Descubre cómo el Monte Carlo secuencial reforzado mejora el muestreo amortizado de distribuciones complejas. Entrenamiento off-policy y temperado adaptativo para mayor precisión.
La inyección de ruido secuencial en subespacios evita colapso de precisión en desaprendizaje certificado. Mejora la utilidad del modelo.
Descubre cómo un nuevo enfoque unifica y optimiza la valoración de datos usando decisiones secuenciales, mejorando la selección en LLM y benchmarks clásicos.
Descubre cómo la combinación de redes neuronales y lógica temporal mejora la precisión y consistencia en la predicción de sufijos de procesos.
PATHS: temple paralelo para muestreo inicial en alineación de recompensas. Evita modas locales y explora regiones raras de alta recompensa en modelos generativos.

Descubre SAEmnesia, un marco que elimina conceptos en modelos de difusión con precisión y eficiencia, reduciendo la búsqueda de hiperparámetros en un 96.67%.

Descubre cómo el entrenamiento secuencial de LLMs provoca colapso de representación y qué intervenciones pueden preservar la plasticidad y la generalización.
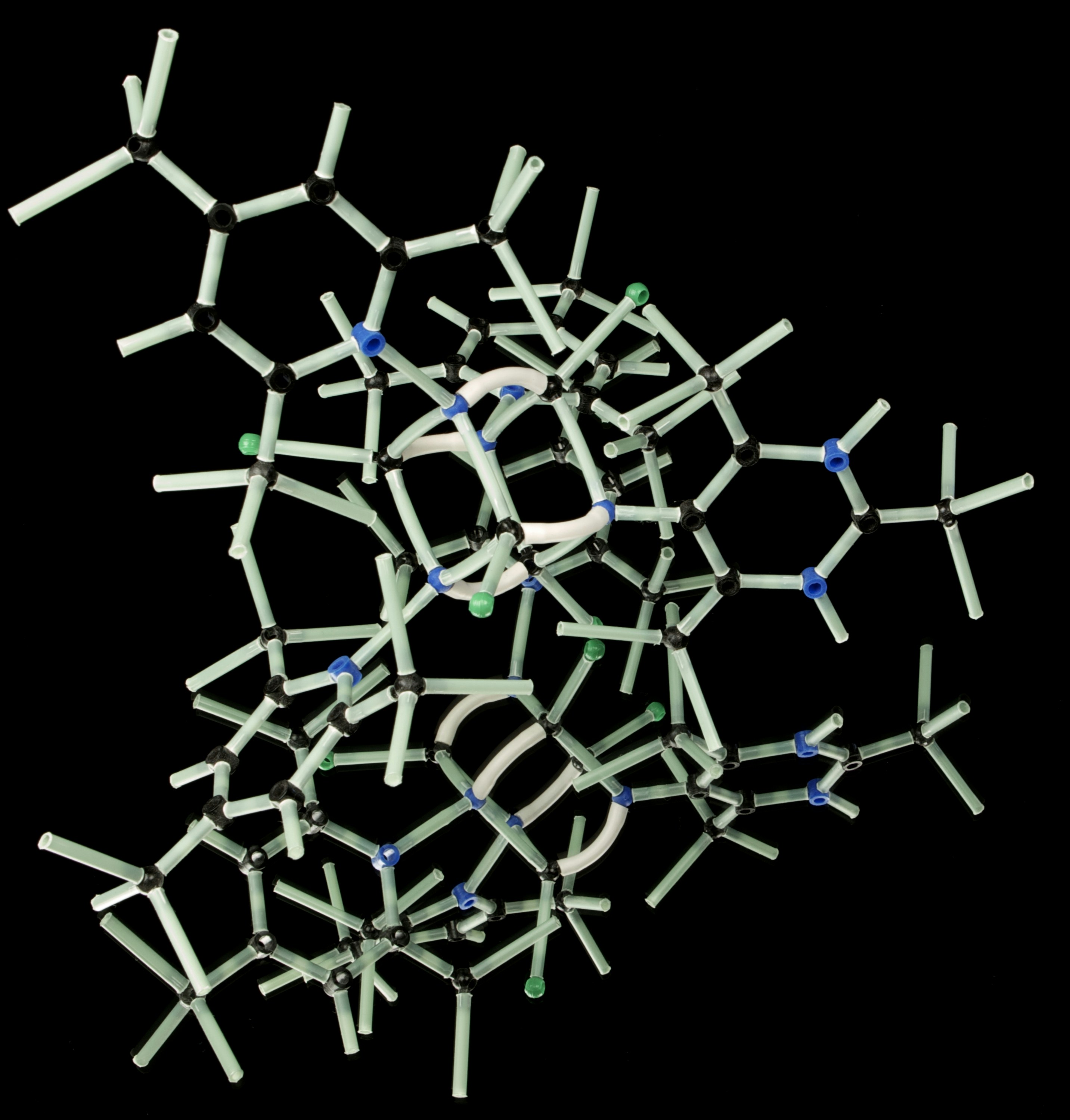
Descubre cómo el algoritmo CFO equilibra recompensa y restricciones en el diseño molecular mediante ajuste fino secuencial. Resultados prometedores.

¿Cuándo son suficientes los LLMs como optimizadores de políticas en RL? PromptPO iguala o supera algoritmos clásicos. Conoce sus límites en control continuo.