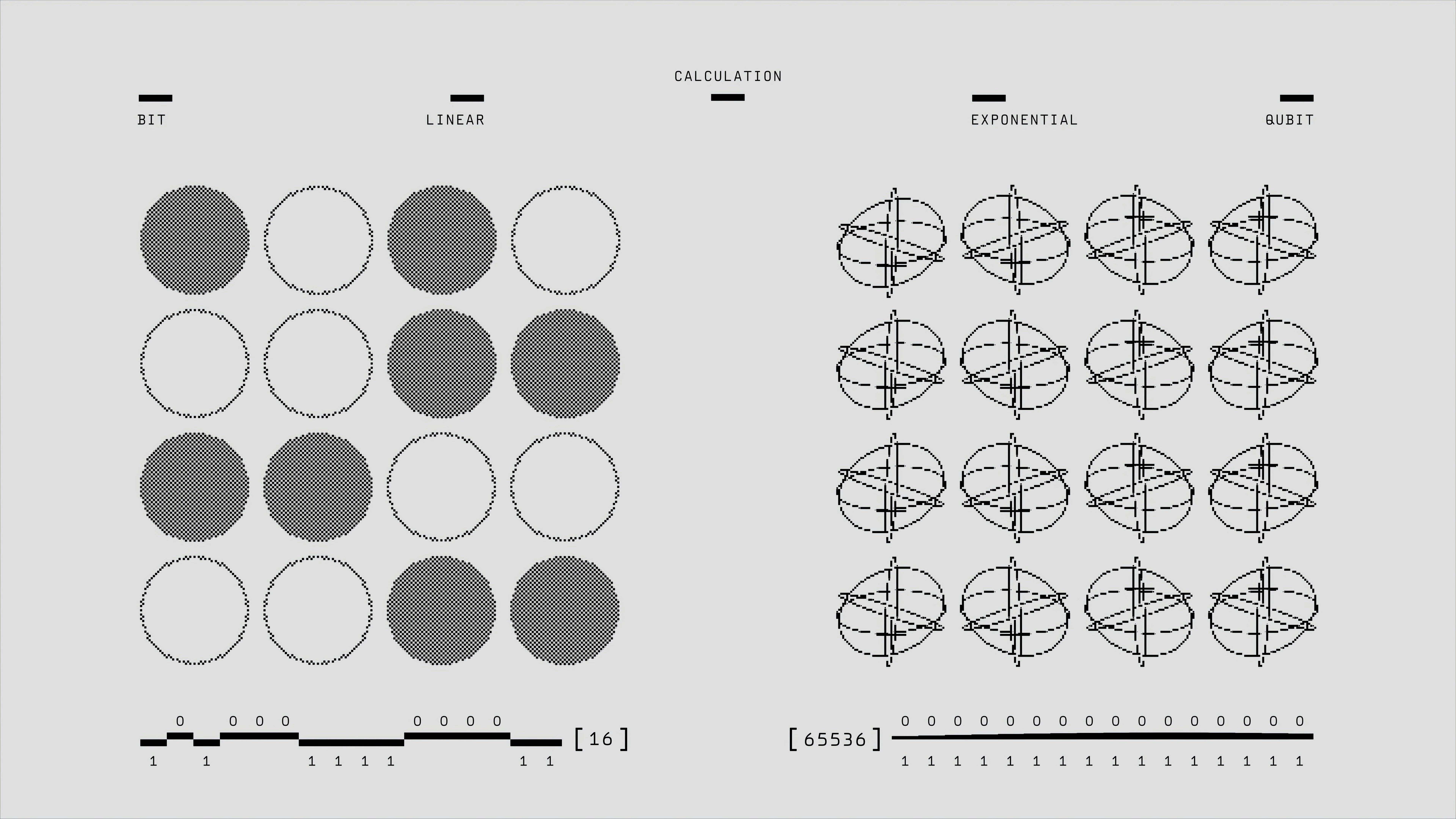
ReaLM: Puente de Cuantización Residual entre Embeddings de KG y LLMs
Descubre ReaLM, un innovador marco que une embeddings de KG y LLMs mediante cuantización residual para mejorar la completación de grafos. ¡Rendimiento líder!
Descubre ReaLM, un innovador marco que une embeddings de KG y LLMs mediante cuantización residual para mejorar la completación de grafos. ¡Rendimiento líder!

Aprende cómo la inferencia adaptativa con recursos limitados mejora la fijación de precios secuenciales. Identificación local y corrección de sesgo para decisiones precisas.

Modelo MAYA basado en bandidos multi-brazo reproduce decisiones de forrajeo de abejas con memoria limitada. Ventana temporal óptima de 7 pruebas. ¡Lee más!

BAHSD: marco de destilación adaptativa para recomendación en caja negra que logra hasta un 4.98% de mejora sobre el profesor y un 80%+ en usuarios de cola larga. Plug-and-play.

Descubre FLIPS, un método que identifica configuraciones de LLMs con un 96% de precisión, clave para la regulación de IA.

Composición secuencial de grupos: una ventana a la mecánica del deep learning. Descubre cómo redes neuronales aprenden operaciones estructuradas.

Investigación muestra que los transformers requieren más datos que las RNN para seguimiento de estado y no comparten pesos entre longitudes. Descubre las diferencias clave.

Descubre cómo las extensiones del framework HiPPO ofrecen memoria adaptativa y asociativa en modelos de espacio de estado, manteniendo la interpretabilidad. Un
Descubre cómo el método SLSE-FRS combina Sketch-and-Solve e Iterative-Sketching para obtener estimadores de alta precisión en modelos lineales a gran escala.
Descubre un método asintóticamente óptimo para pruebas secuenciales en cadenas de Markov. Mejora límites inferiores y aplicaciones en MCMC y MDPs.
Descubre EuroBERT, la nueva familia de codificadores multilingües. Supera a alternativas en recuperación, clasificación y más. Soporta 8,192 tokens.

El escalamiento en inferencia mejora el preentrenamiento generativo, superando la falsa dicotomía entre autoregresión y difusión.

Nuevo método libre de distribución para localizar puntos de cambio después de una detección secuencial. Garantías de cobertura finitas y rendimiento superior.

Descubre cómo NeuroLDS utiliza aprendizaje profundo para generar secuencias de baja discrepancia, superando métodos clásicos en integración numérica y robótica.
El fine-tuning secuencial con LoRA vence a métodos CRL complejos en modelos VLA: alta plasticidad, sin olvido catastrófico.

Descubre APB-V: acelera la comprensión de videos largos en múltiples GPUs hasta 12.72x sin pérdida de rendimiento. Ideal para modelos multimodales.

Descubre cómo datos sintéticos de calidad permiten las primeras leyes de escalado para LLMs en recomendación, superando datos reales.

Descubre DistMatch, nuevo método de agrupación adaptativa que mejora la robustez de la predicción conforme secuencial ante cambios de distribución.
Descubre cómo la estructura de la tarea invierte la codificación de estado en modelos como Transformers y Mamba. Un estudio revela patrones opuestos en paridad y Dyck.

Descubre cómo la escala en modelos de secuencias simpliciales se correlaciona con estructura y rendimiento en transformers. Un estudio revela patrones predecibles.