
RDA: Agente de diseño de recompensas para aprendizaje por refuerzo
Descubre RDA, un agente basado en VLM que diseña recompensas semánticas para robots. Logra políticas alineadas con instrucciones humanas en manipulación.
Descubre RDA, un agente basado en VLM que diseña recompensas semánticas para robots. Logra políticas alineadas con instrucciones humanas en manipulación.

SceneSmith: genera escenas interiores realistas con IA para simulación robótica. Hasta 6x más objetos, <2% colisiones, 96% estables.

HALO estabiliza aprendizaje descentralizado en colaboración humano-robot mediante optimización de Lyapunov, mejorando generalización y robustez en casos extremos.

Intel regresa al mercado de robótica con sus nuevos chips Series 3 para IA física y edge. Descubre cómo impulsan robots como el barista Ella y el futuro de la automatización.

Nuevo método certifica la seguridad de robots autónomos con filtros de creencia menos conservadores, usando predicción conforme para una interacción humano-robot más eficiente y segura.

Desde un beanie baby hasta una dentadura postiza: los objetos más raros olvidados en robotaxis según Uber. Descubre la lista completa.

Descubre cómo los videos humanos entrenan robots con modelos VLA escalables. Encuesta sobre aprendizaje robótico con datos humanos.
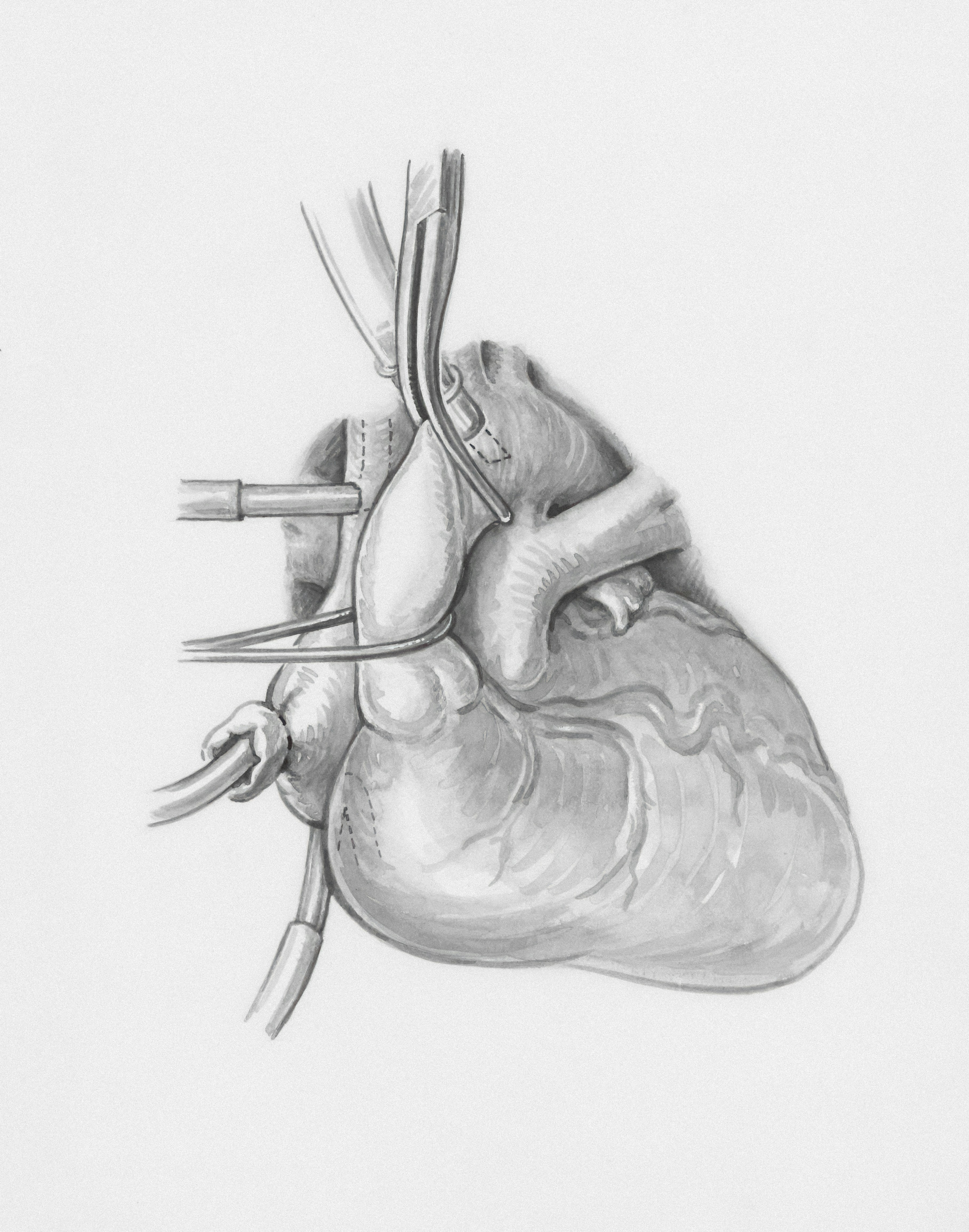
Descubre cómo VDSB-GWSyn utiliza Diffusion Schrödinger Bridge para sintetizar guías coronarias realistas, mejorando la localización de puntas en angiografías y la seguridad en PCI robótica.

IDP: genera acciones en un paso con corrección del entrenamiento usando geometría condicional de experto. Ideal para control robótico de alta frecuencia.
Descubre cómo el control de pose con DRL supera incertidumbres en robots Double-Ackermann, logrando un 92% éxito en simulación y transferencia real sin ajustes.

PaCo-VLA introduce un prior de cumplimiento con escudo de pasividad para manipulación robótica de contacto, asegurando cero violaciones incluso bajo cambios adversos.

Optimiza el diseño de robots multi-cuerpo con gradientes de valor e IA. Ahorra tiempo y mejora el rendimiento sin reentrenar cada morfología.

Descubre cómo reestructurar la comunicación entre robots mejora un 47% el rendimiento, frente al 9% de escalar modelos. Estudio con 10 robots reales.

Descubre el gap de inferencia en IA física: memoria limitada pero no ancho de banda. CUDA Graphs muestra un overhead oculto en GPUs rápidas como H100.

Aprendizaje continuo con modelos de lenguaje y visión permite a robots aprender de adversidades en entornos reales para mejorar predicción y planificación.

Aprende cómo Hide-and-Seek logra detectar fallos en robots VLA sin anotaciones paso a paso, mejorando la fiabilidad en tiempo real.

Descubre TARIC, navegación exterior VLN que supera interrupciones semánticas con memoria 3D y transitabilidad. Mejora tasa de éxito real al 40% vs 17.5%.

Descubre cómo los modelos de visión-lenguaje fallan en detectar colisiones robot-humano. TouchSafeBench revela sus limitaciones en seguridad.

Descubre cómo un portal de estudiantes con prácticas automatiza tareas repetitivas con IA. Ahorra tiempo y reduce errores. Q2BSTUDIO, tu aliado.

Aprende a construir un robot bípedo casero con músculos neumáticos de aire. Proyecto DIY detallado y funcional.