
GTBench: Benchmarck curricular para evaluar LLMs en teoría de grafos
Nuevo benchmark curricular GTBench evalúa LLMs como asistentes en teoría de grafos. GPT-5 lidera, Llama falla.
Nuevo benchmark curricular GTBench evalúa LLMs como asistentes en teoría de grafos. GPT-5 lidera, Llama falla.

El marco PRPF optimiza la intervención de agentes móviles proactivos al percibir antes de razonar, reduciendo falsos positivos y mejorando la eficiencia. Descubre cómo.

Aprende a destilar reglas de programación lógica desde LLMs para VQA interpretable, con solo pocos ejemplos. Alternativa eficiente al aprendizaje de reglas tradicional.

¿Puede un modelo transmitir activaciones a otro? En nuestro experimento con Pythia, la alineación no basta para comunicación causal. Resultado negativo.
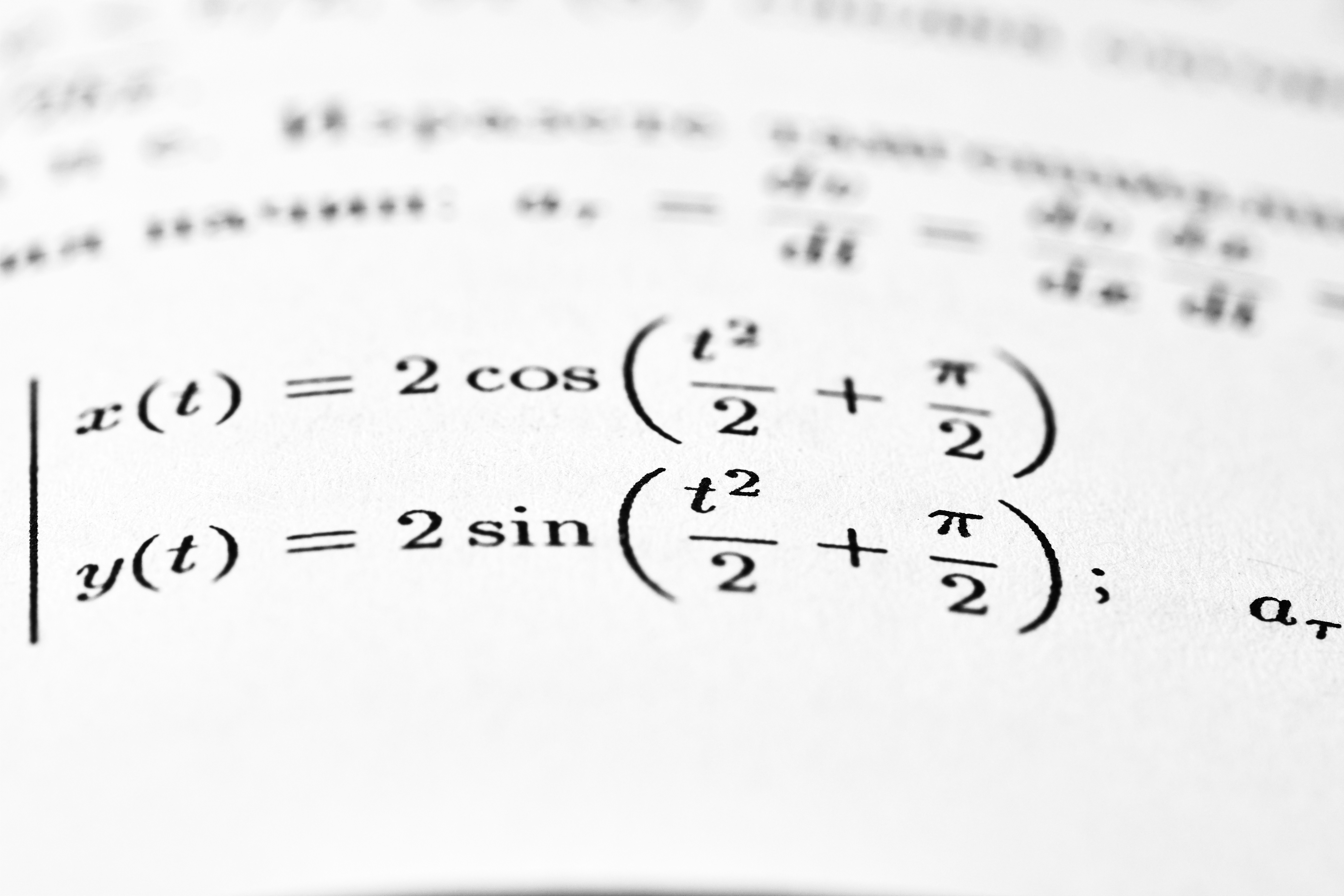
Descubre cómo LEAP, un marco agentivo, potencia LLMs para resolver problemas formales de matemáticas, superando récords en competiciones como Putnam e IMO.

CP-Agent: IA multimodal que interpreta morfología celular bajo fármacos, acelerando descubrimiento con reportes contextuales.

Descubre ThoughtFold, un framework que elimina exploraciones redundantes en modelos de razonamiento, reduciendo tokens hasta un 56% sin perder precisión.
Reduce violaciones de restricciones en un 39% con CRGC. Mejora el seguimiento de instrucciones en modelos de razonamiento.
Descubre TSQAgent, un marco de agentes de IA que evalúa la calidad de series temporales mediante razonamiento y herramientas analíticas. Mejora la selección de datos y el rendimiento.

Aprende cómo la lógica defeasible de puntos de vista permite implicaciones no monótonas con condicionales situados y cierres racional y lexicográfico.

Evalúa el razonamiento químico de los LLMs con ChemCoTBench-V2, un benchmark verificable paso a paso que detecta fallos en la lógica ocultos tras respuestas correctas.
Descubre Code-on-Graph, framework que combina LLMs y grafos de conocimiento para razonamiento programático flexible. Supera limitaciones de precisión y escalabilidad.
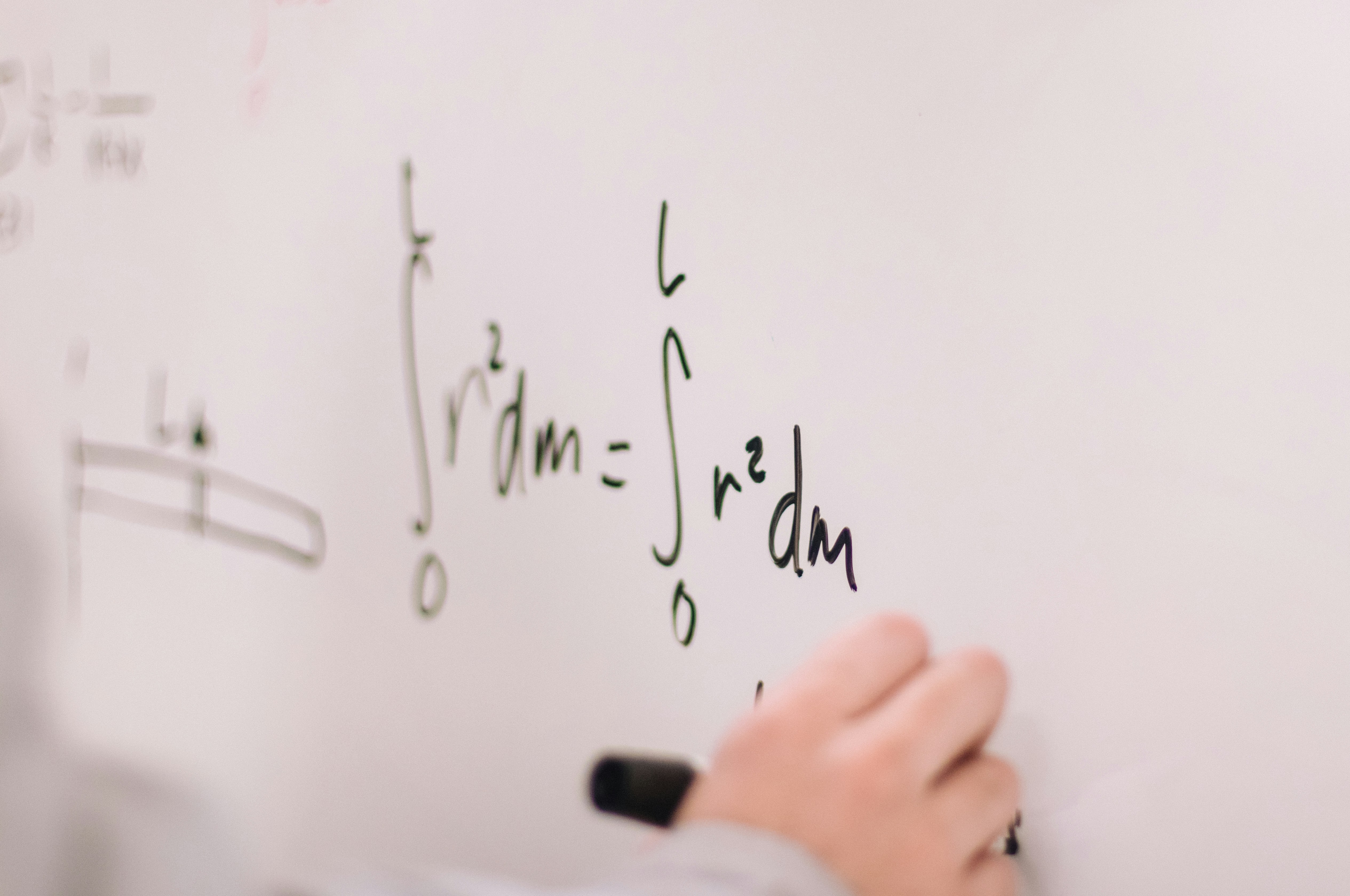
Descubre cómo los gráficos de derivación simplifican el razonamiento del Do-Cálculo, permitiendo obtener estimadores más eficientes para la inferencia causal. ¡Lee más!

Descubre cómo la persistencia moderada de subobjetivos (periodos de 3 a 6 pasos) mejora el razonamiento latente jerárquico.
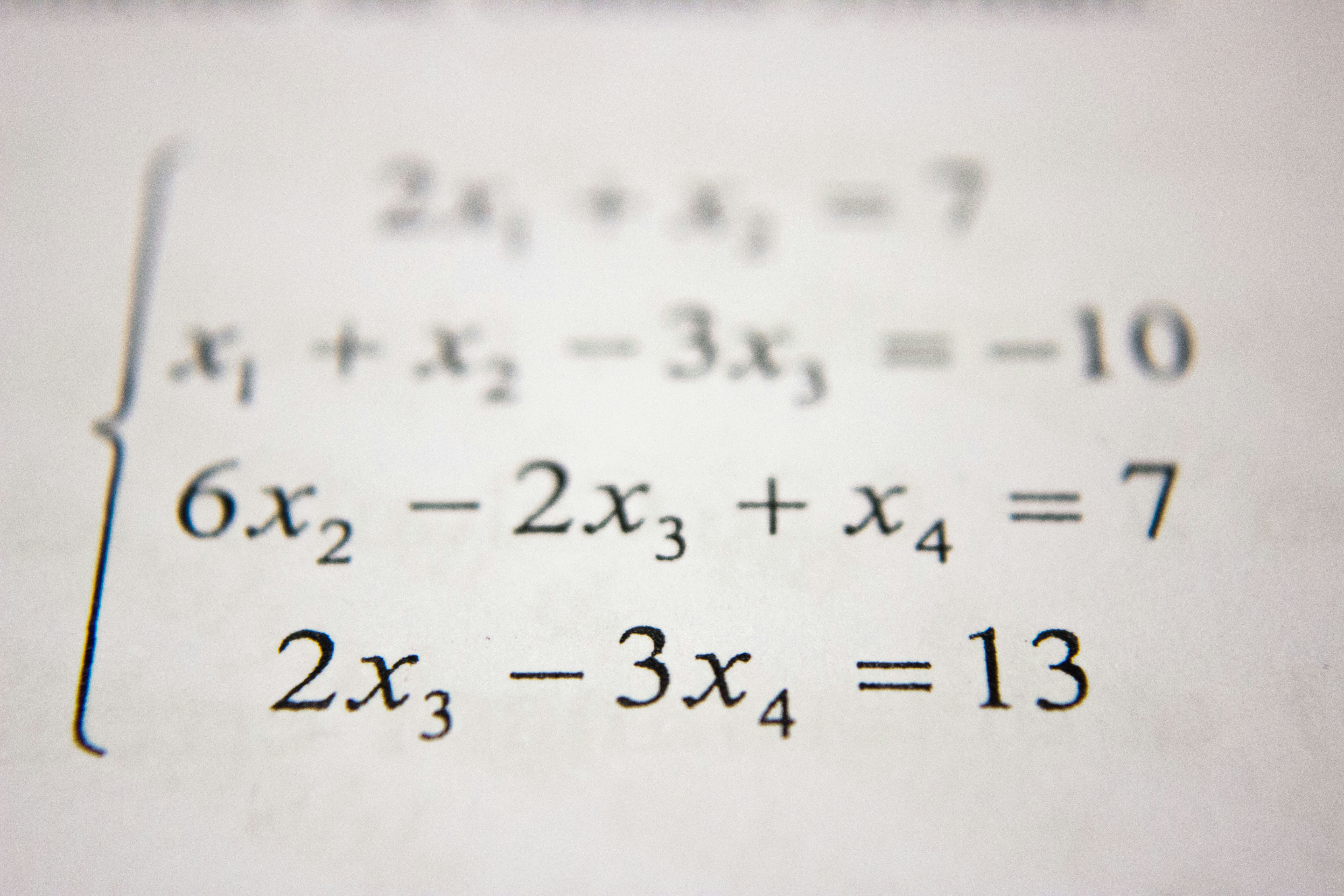
Descubre PyraMathBench: evalúa y mejora la capacidad matemática de los LLMs con 32,505 preguntas y técnicas como SOLVE e IRPO.

Un nuevo benchmark de acertijos lógicos revela la estructura oculta del razonamiento en modelos de IA, más allá de la precisión.
Hedge-Bench: solo el 16% de éxito en tareas financieras complejas para agentes de IA. ¿Qué tan lejos estamos del analista humano?

La entropía falla en RL visual: VEPO selecciona tokens visual-informativos y supera en hasta 3.15 puntos. Descubre cómo.

Los Tokens de Percepción Imaginativa (IPT) mejoran el razonamiento espacial en modelos multimodales sin generar imágenes. Aumento del 3.4% en precisión en conteo multivista.

Descubre cómo TRAP usa parches adversariales para secuestrar razonamiento CoT en robots VLA y provocar comportamientos peligrosos. Vulnerabilidad crítica en IA.