
Primer sobre datos de razonamiento post-entrenamiento: cómo funciona
Descubre cómo los datos de razonamiento post-entrenamiento impulsan el avance de los modelos de IA. Una guía completa basada en más de 150 estudios.
Descubre cómo los datos de razonamiento post-entrenamiento impulsan el avance de los modelos de IA. Una guía completa basada en más de 150 estudios.

Descubre cómo combinar modelos pequeños y grandes permite detectar errores raros y sutiles en videos de primera persona, equilibrando velocidad y precisión.

CodeCytos automatiza el análisis espacial molecular con IA. Descubre cómo este agente de código acelera la búsqueda de biomarcadores.

V-LynX alinea tokens en modelos de video para integrar nuevas modalidades (audio, 3D) con eficiencia y rendimiento SOTA. ¡Código abierto!

Mejora el razonamiento algorítmico neuronal con reconstrucción auxiliar: representaciones más ricas que potencian el rendimiento de arquitecturas existentes.
Descubre por qué la edición de parámetros en LLMs daña capacidades clave. Evidencia empírica muestra que la recuperación supera a la edición paramétrica.

Descubre Critic-R: un marco que cierra el ciclo de retroalimentación entre agente y retriever, mejorando la precisión en búsquedas complejas sin anotaciones manuales. Resultados superiores en QA.

Los LLMs optimizados por resultados alcanzan altos benchmarks pero colapsan en razonamiento. Te explicamos la paradoja y cómo los modelos de recompensa de procesos la resuelven.
La dinámica de entropía revela la fragilidad de los orquestadores y la trampa del razonamiento en sistemas multiagente. Identifica el colapso del rendimiento.

Descubre por qué los modelos de razonamiento (LRM) fallan al evaluar soluciones, pese a generarlas. Analizamos el sesgo de confirmación y el dataset VAIR.
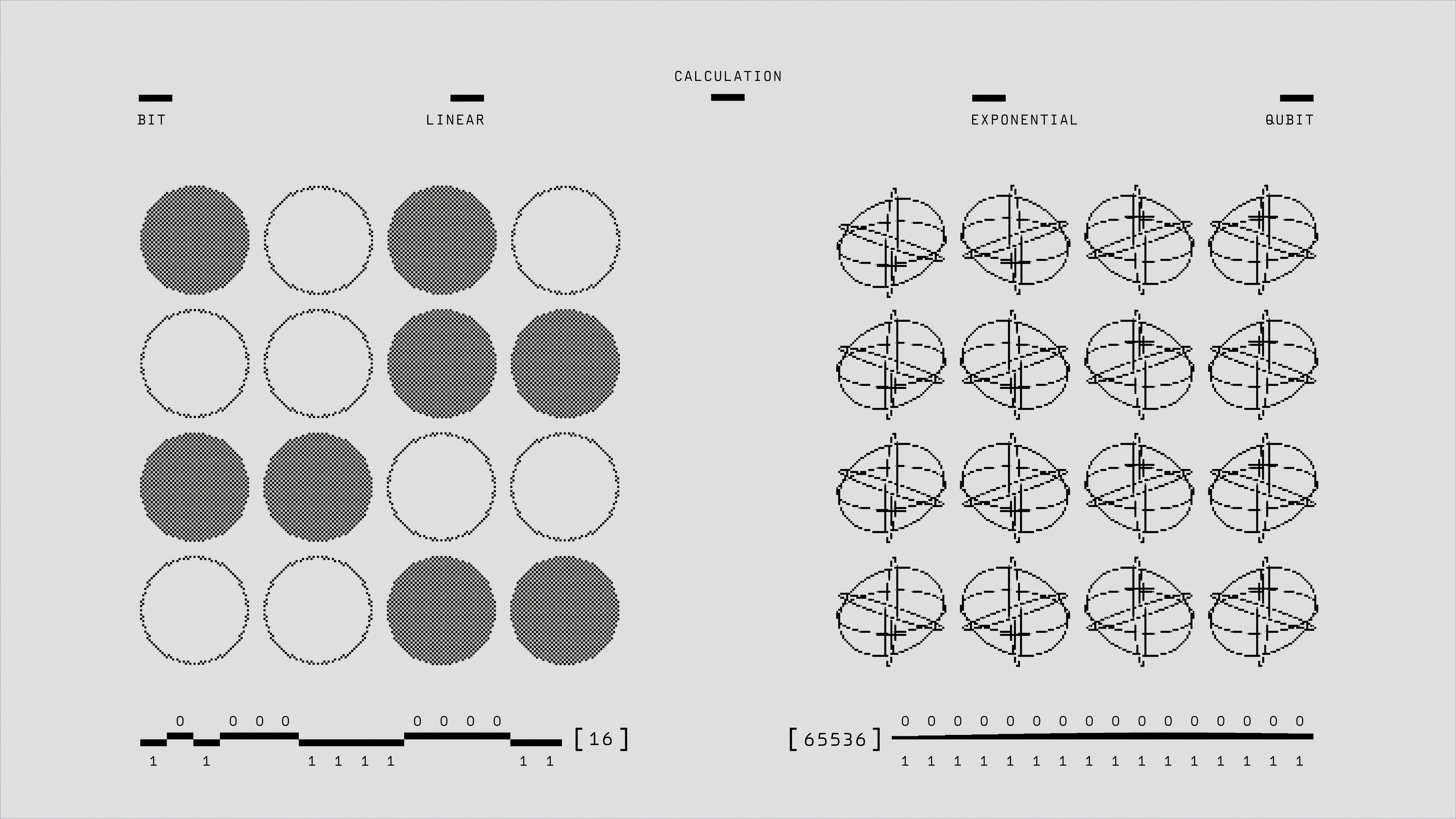
TRON genera instancias verificables bajo demanda para entrenar modelos de razonamiento visual con RL, mejorando benchmarks multimodales.

SMH-Bench evalúa agentes LLM en hogares inteligentes con 1100 tareas. ¿Son capaces de razonar y automatizar? Descúbrelo.

Descubre cómo la inferencia 2-bit en modelos de razonamiento genera fallos como bucles y cómo la planificación y rescate recuperan precisión hasta 87%.

eMoT: marco que estabiliza el razonamiento en LLMs con memoria evolutiva, anclaje simbólico y corrosión. Logra 100% en Juego de 24.

Descubre cómo EAPO mejora la precisión en modelos de IA reduciendo el abuso de herramientas. Aprende cuándo no actuar y optimiza el rendimiento.
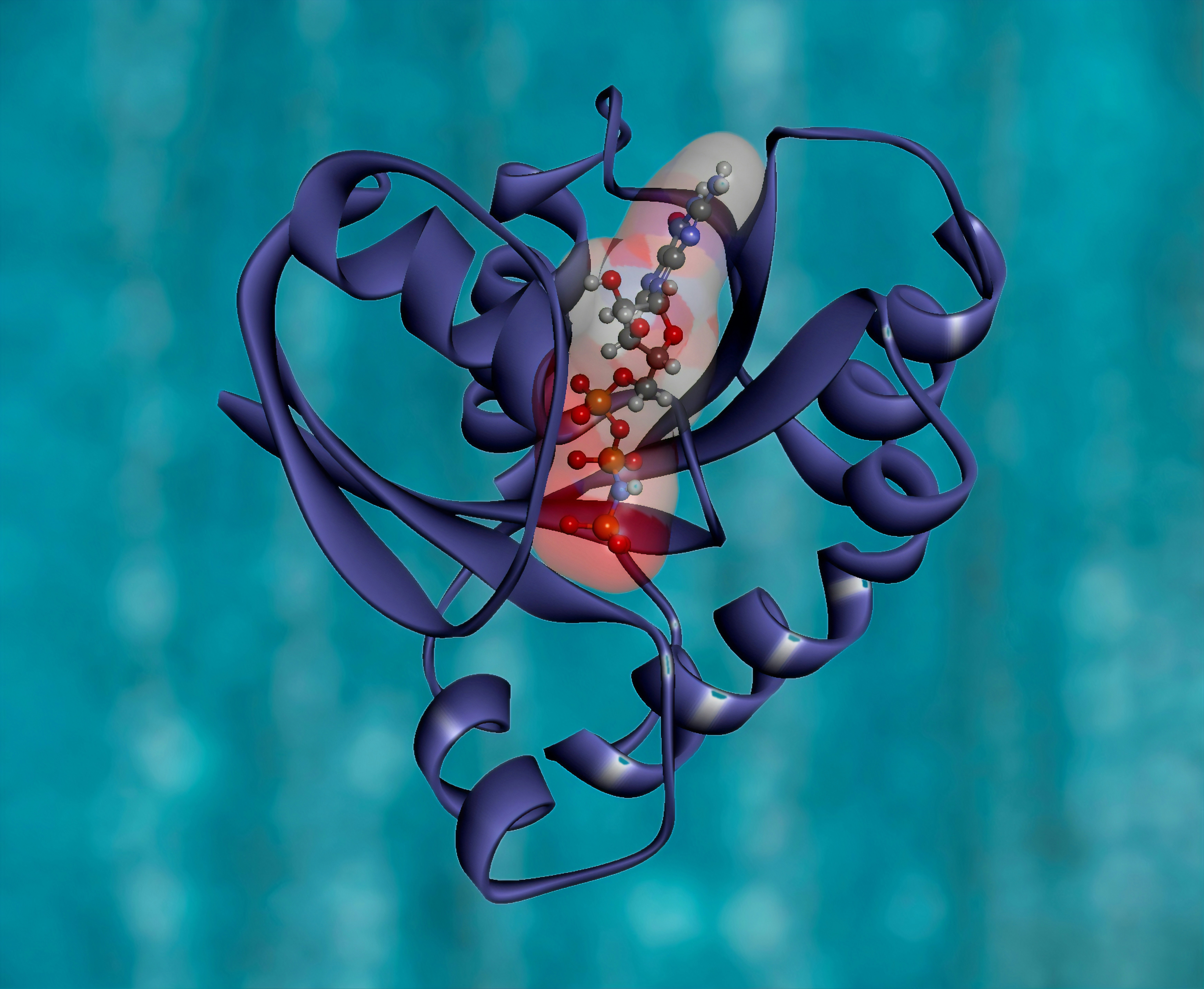
Descubre AgentPLM: integra razonamiento aumentado y herramientas biofísicas para diseñar proteínas. Logra mejoras del 10% en anticuerpos.

BenHalluEval: un marco innovador para detectar alucinaciones en LLMs en bengalí. Evalúa 7 modelos en 4 tareas. ¡Descubre los resultados!

CSRP combina razonamiento en cadena y RL para corregir texto chino con precisión récord, reduciendo sobrecorrección. ¡Optimiza tu proceso de corrección!
Descubre TCAR-Gen, un nuevo marco que combina redes neuronales de grafos, fusión temporal y razonamiento en árbol para responder preguntas complejas sobre casos criminales históricos.

Descubre GraphARC, benchmark de razonamiento abstracto en grafos. Revelamos la brecha entre comprensión y ejecución en modelos de IA.