
Afrispeech Semantics: Evaluación del razonamiento semántico en audio
Descubre cómo los modelos de lenguaje de audio manejan el razonamiento semántico en distintos acentos y dominios. Evaluación de Afrispeech Semantics.
Descubre cómo los modelos de lenguaje de audio manejan el razonamiento semántico en distintos acentos y dominios. Evaluación de Afrispeech Semantics.

RAIL es un benchmark cognitivo CHC para evaluar inteligencia auditiva en modelos de audio-lenguaje. Revela diferencias en percepción, razonamiento y memoria.

Los ingenieros de Apple y Google revelan cómo la IA y el cloud impulsan la evolución de los sistemas embebidos. Descubre su visión.

Descubre cómo AuRA internaliza la comprensión del audio en LLMs mediante LoRA, superando a sistemas en cascada con mayor eficiencia y precisión.

Descubre cómo la combinación de diarización de voz y aprendizaje autosupervisado logra un 78% de precisión en la evaluación de pronunciación de niños coreanos de 2 a 5 años.

Descubre cómo la arquitectura CNN-Transformer logra un 98.1% de precisión en el reconocimiento de emociones en habla árabe, superando a modelos como wav2vec 2.0.

Mejora el reconocimiento de voz en entornos ruidosos con un nuevo método sin entrenamiento que fusiona señales de forma inteligente. Aumenta la precisión y robustez.

Descubre MisoTTS, el modelo de 8B parámetros que genera voz continua a partir de texto. Conoce su arquitectura, usos y cómo desplegarlo.

Descubre GlobeAudio, el primer benchmark multilingüe y multicultural para evaluar modelos de audio-lenguaje en condiciones realistas. Resultados sorprendentes.
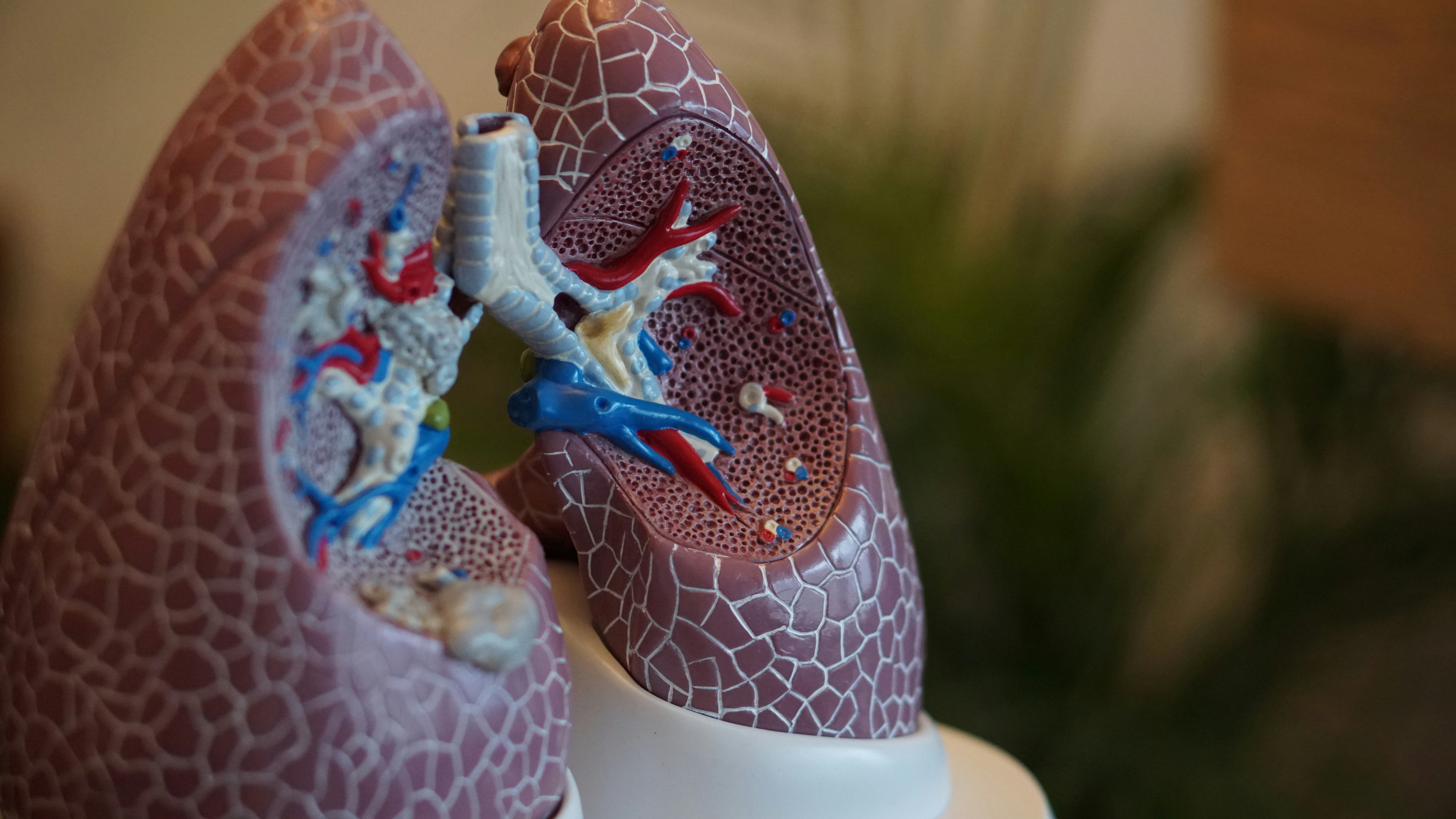
Descubre AeroSpectra Sentinel, un prototipo que combina STFT, ML y LLM para evaluar riesgo de asma a partir de sonidos respiratorios y señales clínicas. Auditoría segura.

Clasificación de audio con clases variables y pocos ejemplos usando adaptación de prototipos y entrenamiento pseudo-variable. ¡Alta precisión!

Nuevo método HSCHG mejora la localización de eventos audiovisuales usando grafos heterogéneos jerárquicos con restricciones semánticas.

Mejora la robustez de asistentes de voz con IRAF: un módulo que adapta la fusión de audio para filtrar interferencias y optimizar diálogos full-dúplex.
TargetSEC: conversión de emociones en voz con difusión latente. Preserva identidad y supera a otros sistemas en precisión.
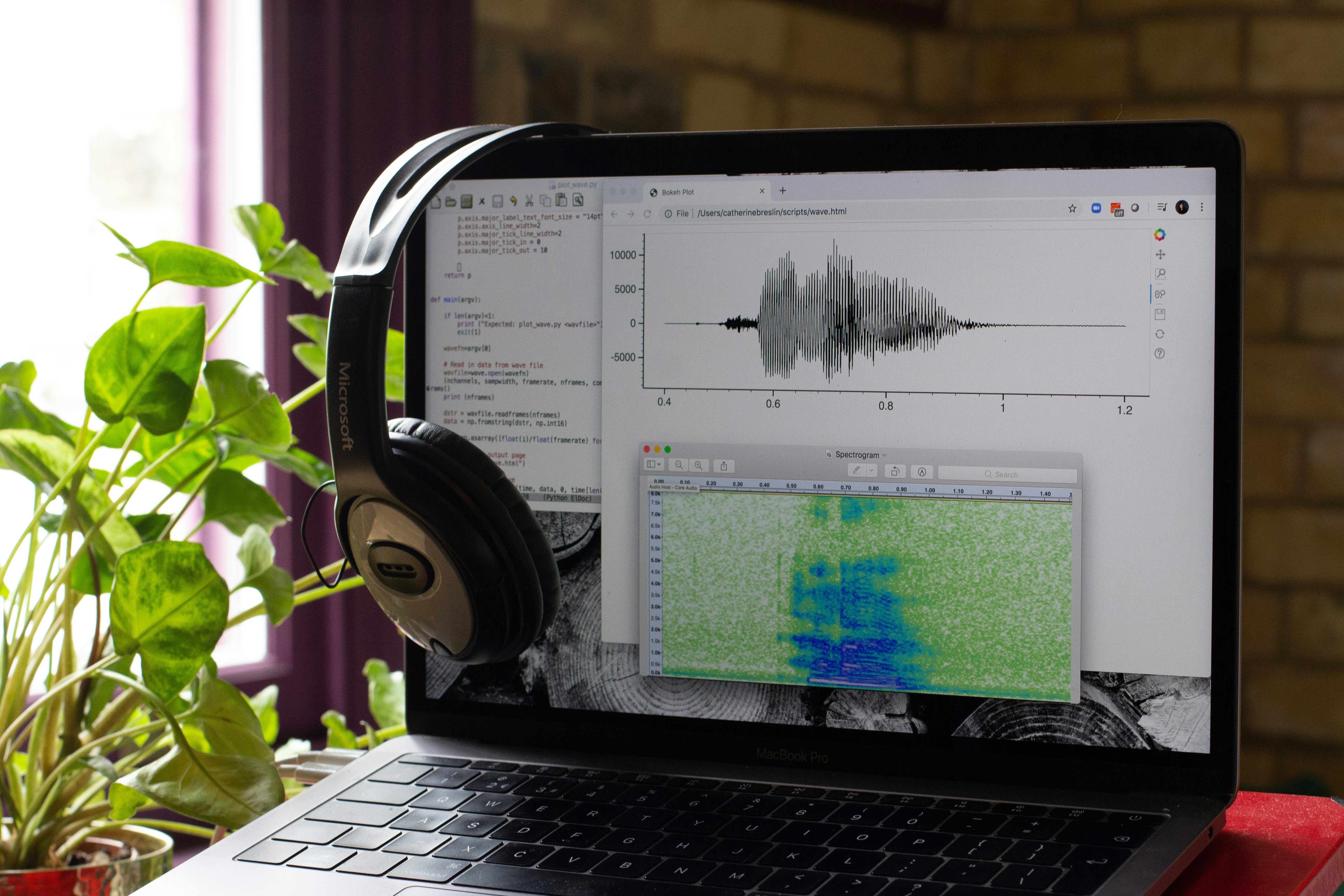
Descubre Nemotron 3.5 ASR de NVIDIA: modelo de 600M parámetros que transcribe 40 idiomas en tiempo real con latencia ajustable. Código abierto en Hugging Face.

¡Descubre DBHN-Net! La red híbrida que reduce 7.5x la complejidad computacional en mejora de voz sin perder rendimiento.

Analizamos el impacto de la relación señal-distorsión invariante a escala en la separación de voz con referencias ruidosas. Descubre cómo mejorar la calidad con NISQA.

Descubre cómo el ruido en las referencias afecta al SI-SDR en separación de voz y un método para mejorar la calidad del audio separado.

Descubre cómo FSA-GRPO entrena modelos auditivos con aprendizaje por refuerzo para mejorar el reconocimiento de voz usando pocos ejemplos.

Descubre FastSLM: comprime audio largo al 1.67 tok/s, reduce 97% tokens sin perder contexto. Optimiza tus MLLMs.