Nemotron 3.5 ASR: modelo de reconocimiento de voz en tiempo real con 40 idiomas
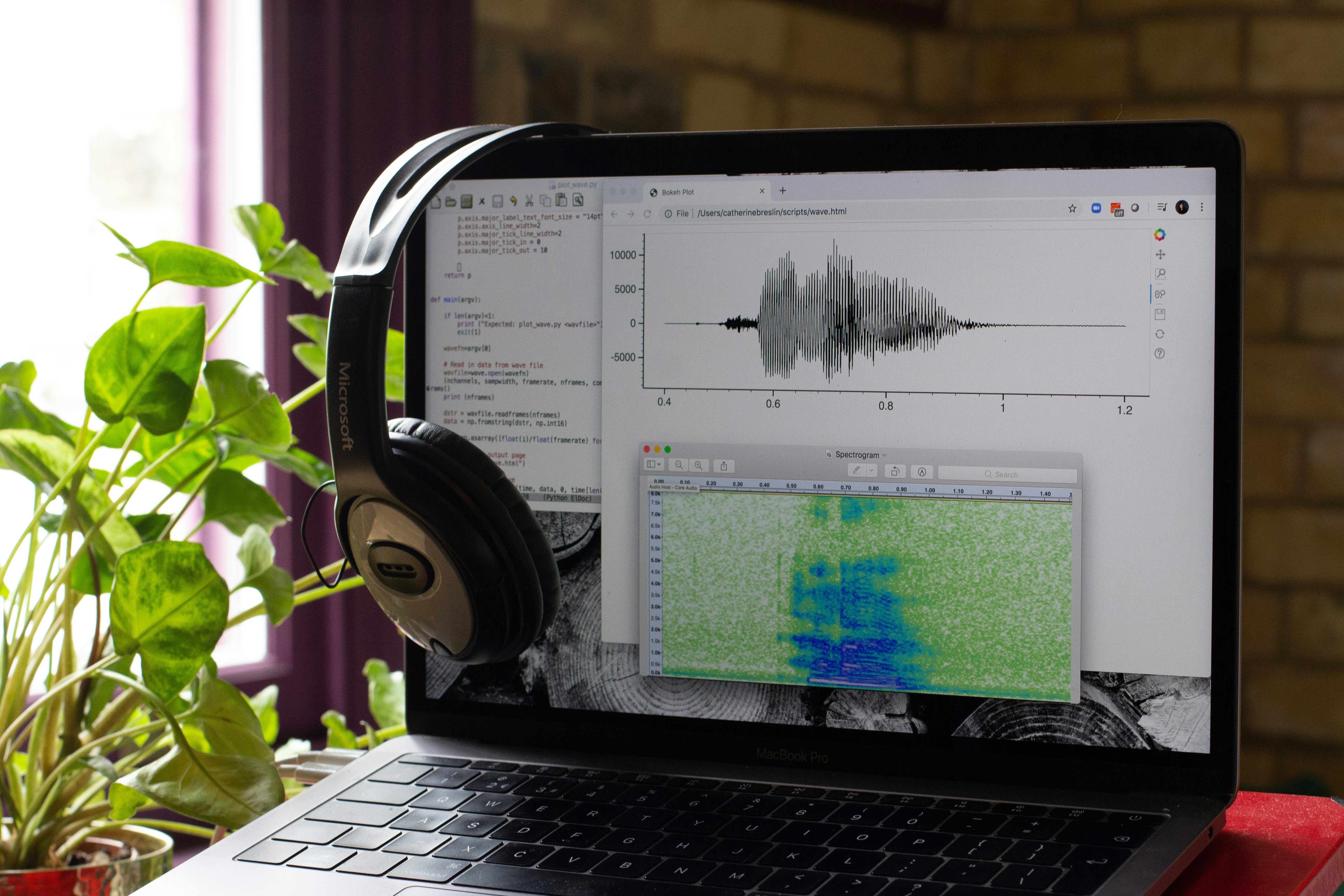
El avance de los modelos de reconocimiento automático del habla (ASR) ha dado un salto significativo con la llegada de Nemotron 3.5 ASR, un modelo de 600 millones de parámetros desarrollado por el equipo de NVIDIA que opera en tiempo real y soporta 40 variantes lingüísticas desde un único punto de control. Este modelo no solo destaca por su arquitectura Cache-Aware FastConformer-RNNT, que optimiza el procesamiento de audio al eliminar la redundancia de ventanas solapadas, sino también por su capacidad de ajustar la latencia entre 80 ms y 1,12 segundos sin necesidad de reentrenamiento, lo que lo convierte en una herramienta versátil para aplicaciones que exigen desde respuestas instantáneas hasta alta precisión en transcripciones por lotes.
Desde una perspectiva empresarial, la disponibilidad de pesos abiertos bajo licencia OpenMDW-1.1 y la posibilidad de autoalojar el modelo representan una ventaja competitiva para organizaciones que buscan mantener el control sobre sus datos y costes operativos. Esta flexibilidad permite integrar el ASR en flujos de trabajo que requieren aplicaciones a medida, adaptadas a sectores como la atención al cliente, la accesibilidad o la monitorización de comunicaciones. Además, la capacidad de detectar automáticamente el idioma mediante el parámetro target_lang=auto facilita la implementación en entornos multilingües sin necesidad de componentes adicionales de identificación lingüística.
La arquitectura subyacente, basada en un codificador FastConformer de 24 capas y un decodificador RNNT, introduce un enfoque cache-aware que reduce la carga computacional al reutilizar estados de atención y convolución. Esto se traduce en un rendimiento hasta 17 veces superior en concurrencia de flujos respecto a enfoques con almacenamiento en búfer, según las pruebas internas de NVIDIA sobre hardware H100. Para las empresas que operan con grandes volúmenes de audio, esta eficiencia se traduce directamente en ahorro de infraestructura y en la posibilidad de desplegar ia para empresas sin comprometer la latencia ni la calidad de la transcripción.
Un aspecto especialmente relevante es la capacidad de personalización mediante fine-tuning. NVIDIA publicó un caso práctico con griego y búlgaro, donde logró reducciones relativas del Word Error Rate (WER) del 32% y 31% respectivamente, utilizando conjuntos de datos públicos como Common Voice y FLEURS. Esto abre la puerta a que equipos de desarrollo entrenen el modelo para dominios específicos, acentos o idiomas minoritarios, integrando estos avances en soluciones de software a medida que requieran un alto grado de especialización lingüística.
En el panorama competitivo, Nemotron 3.5 ASR compite con alternativas como Whisper (offline), Deepgram Nova-3 o AssemblyAI, pero se diferencia por su naturaleza nativa de streaming y su licencia abierta. Mientras que los modelos propietarios ofrecen APIs cerradas con costes por minuto, la opción de autoalojamiento permite a las empresas integrar el ASR en sus propias arquitecturas cloud, ya sea utilizando servicios cloud aws y azure o infraestructura local. Esto resulta crítico para sectores con requisitos de ciberseguridad y cumplimiento normativo, donde los datos de audio no pueden salir del perímetro corporativo.
La integración de puntuación y capitalización de forma nativa elimina la necesidad de procesos posteriores, simplificando el pipeline de procesamiento de lenguaje natural. Esto facilita la creación de agentes IA conversacionales que requieren respuestas formateadas y coherentes. Además, la posibilidad de ajustar el contexto de atención (att_context_size) permite a los desarrolladores afinar el equilibrio entre latencia y exactitud según el caso de uso, ya sea para un asistente virtual en tiempo real o para la transcripción diferida de reuniones.
Para las empresas que buscan capitalizar estas capacidades técnicas, resulta estratégico contar con un socio tecnológico que traduzca modelos de vanguardia en soluciones prácticas. Q2BSTUDIO, como empresa de desarrollo de software y tecnología, ofrece servicios de consultoría e implementación que abarcan desde la puesta en producción de modelos ASR hasta la construcción de aplicaciones a medida que integren inteligencia artificial, servicios inteligencia de negocio y servicios cloud aws y azure. La combinación de modelos abiertos como Nemotron 3.5 ASR con plataformas de análisis como power bi permite extraer insights directamente de conversaciones telefónicas, reuniones o contenidos multimedia, impulsando la toma de decisiones basada en datos.
En definitiva, Nemotron 3.5 ASR representa un hito en la democratización del reconocimiento de voz multilingüe en tiempo real. Su arquitectura eficiente, su flexibilidad de despliegue y su licencia abierta lo convierten en una opción atractiva tanto para startups como para grandes corporaciones. La clave del éxito radica en saber integrar estas capacidades en flujos de trabajo existentes, algo que requiere experiencia en automatización de procesos y en la construcción de sistemas robustos que garanticen escalabilidad, seguridad y rendimiento.
Comentarios