
IntraShuffler: Marco de Privacidad para Aprendizaje Federado con DP Heterogéneo
IntraShuffler protege la privacidad en aprendizaje federado con DP heterogéneo, reduciendo ataques de inferencia sin perder utilidad.
IntraShuffler protege la privacidad en aprendizaje federado con DP heterogéneo, reduciendo ataques de inferencia sin perder utilidad.

Agente de RL optimiza señales de excitación para identificación de parámetros en sistemas mecatrónicos, superando métodos clásicos con solo 0.75% de violaciones
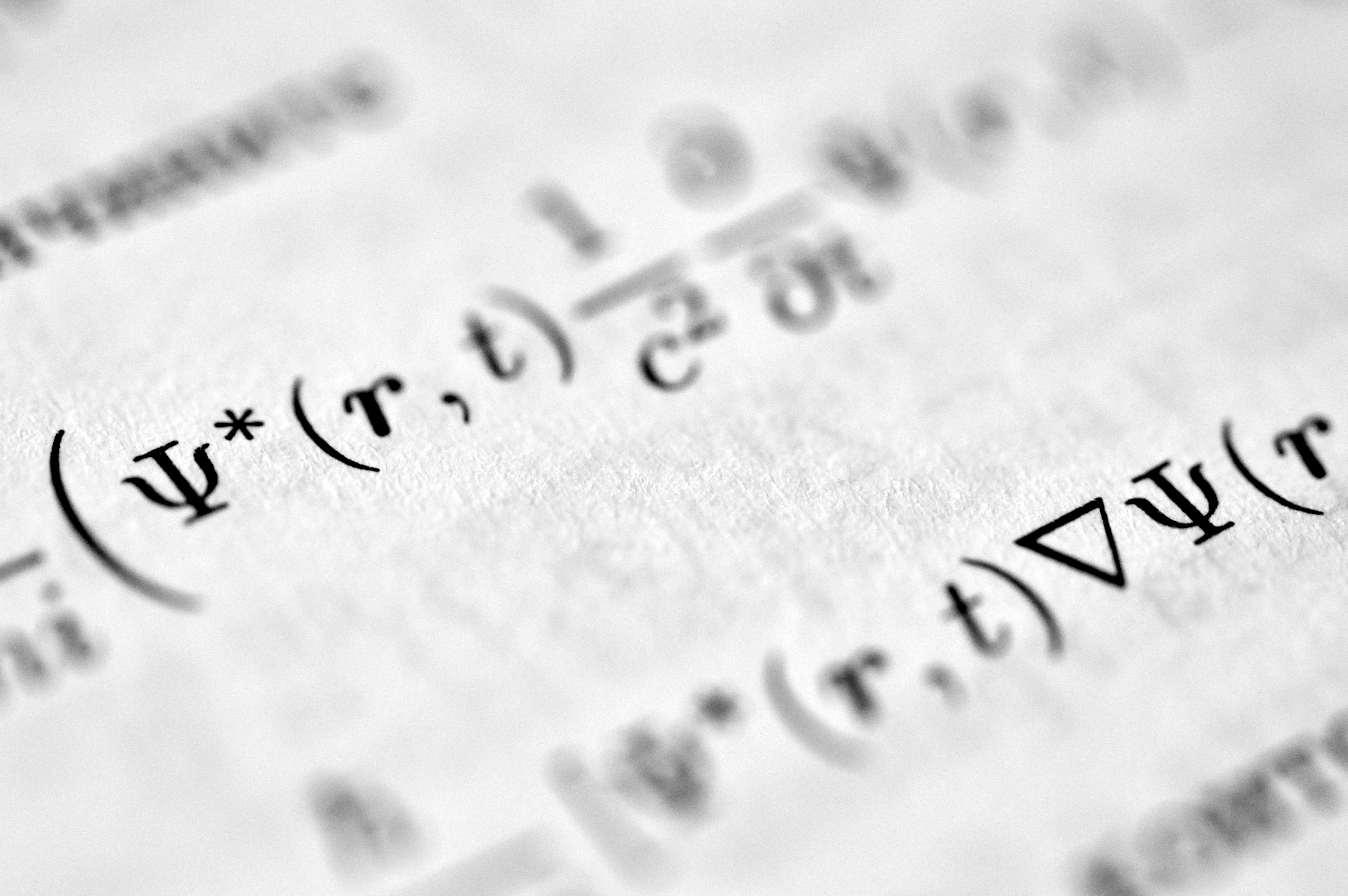
Identifica parámetros físicos desde video con datos mínimos. Sistemas subamortiguados requieren solo un clip. Sin reconstrucción de píxeles.

Descubre ContextSim: un marco de simulación con agentes LLM que integra tiempo, ubicación y necesidades para evaluar sistemas de recomendación con mayor precisi

Descubre cómo equilibrar las tasas de aprendizaje entre capas en redes lineales mejora el rendimiento temprano. Resultados teóricos y experimentales.

Descubre cómo SA-Merging fusiona modelos de IA usando saliencia para evitar interferencias y mejorar el rendimiento multitarea. Optimiza tus modelos sin datos adicionales.

Nuevo método SAMN elimina hiperparámetros en reescalado adaptativo monótono para colas largas. Resultados SOTA en benchmarks.

Aprende cómo la complejidad de los datos define el presupuesto mínimo de parámetros para el razonamiento implícito en modelos de lenguaje.

Descubre por qué el software de laminado es más determinante que tu impresora 3D para lograr piezas perfectas. Consejos clave para optimizar tus impresiones.

DSL-LLaDA adapta LLaDA para denoising continuo, evitando el compromiso longitud/calidad. Obtiene el mejor ROUGE-1 en resumen con pocos pasos.

Descubre cómo las fronteras de Pareto y la optimización automatizada revelan rendimientos superiores en entrenamiento certificado.

Aprende a comprimir redes neuronales agrupando neuronas por equivalencia diferencial. Reduce parámetros sin perder precisión, alternativa eficaz.

Descubre cómo ProbeScale optimiza SLMs mediante análisis de sondas, seleccionando subredes que reducen hasta 10 veces los parámetros sin perder rendimiento.

Descubre cómo el ajuste fino eficiente con adaptadores y LoRA logra segmentar instancias con solo 1-6% de parámetros, manteniendo rendimiento. ¡Optimiza!

Descubre por qué las métricas de ranking como AP y FPR-95 fallan en evaluar la asignación correcta de objetos en múltiples vistas. La normalización Sinkhorn como solución.
Los adaptadores CP ofrecen pasos de parámetros 21 veces más finos que LoRA. ¿Mejoran la precisión? Estudio controlado en OPT-1.3B revela resultados según la tarea.

Optimiza el diseño de robots multi-cuerpo con gradientes de valor e IA. Ahorra tiempo y mejora el rendimiento sin reentrenar cada morfología.
Descubre cómo la optimización bayesiana causal transfiere información entre intervenciones, reduciendo costos y mejorando estimaciones en sistemas.
Descubre cómo SMET mejora el entrenamiento disperso dinámico de LLMs, eliminando picos de pérdida y reduciendo el uso de memoria. ¡Optimiza tu modelo!
¿Crees que RAG es solo ML? Descubre por qué el toolkit clásico (hiperparámetros, splits, explicabilidad) falla y qué alternativas usar en inteligencia documental.