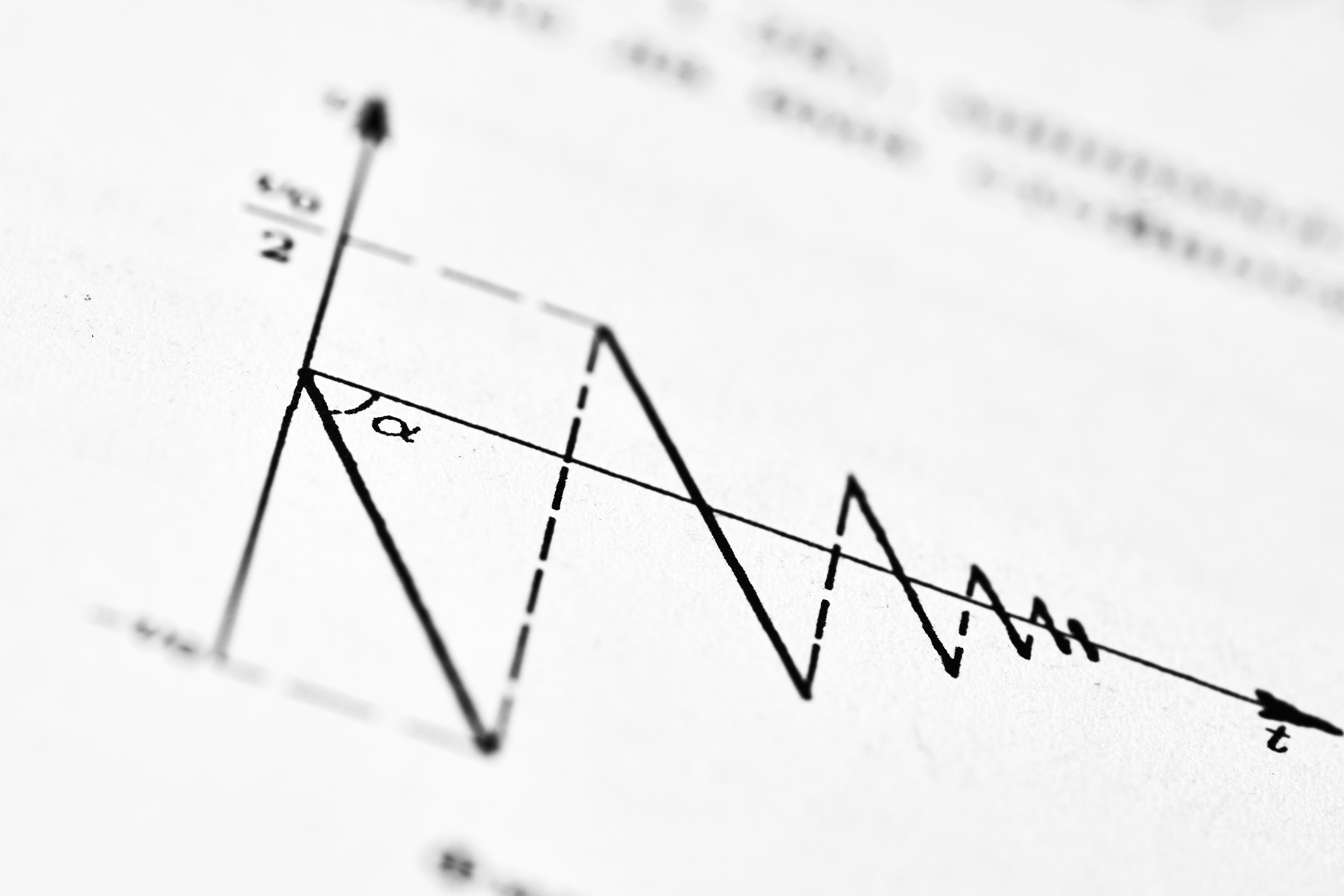
Minimización adaptativa de nitidez con paso Polyak: planificador teórico
Descubre cómo el algoritmo SAM con paso Polyak mejora la generalización y reduce el ajuste de hiperparámetros, con garantías de convergencia teórica.
Descubre cómo el algoritmo SAM con paso Polyak mejora la generalización y reduce el ajuste de hiperparámetros, con garantías de convergencia teórica.

Analizamos las cotas de error teóricas de un estimador de deriva basado en modelos de difusión, descomponiendo el riesgo en discretización, aproximación de score, inicialización y varianza.

Mejora la precisión al estimar valores Shapley con pocas evaluaciones. ShaplEIG usa diseño bayesiano para selección adaptativa de coaliciones. Ideal para costos.

Descubre cómo la nueva arquitectura dual-encoder con fusión Choquet mejora la clasificación acústica submarina, ofreciendo precisión e interpretabilidad.

Descubre cómo afinar modelos de atención lineal sin perder el aprendizaje en contexto. Consejos teóricos para mejorar el rendimiento zero-shot.

Aprende a resolver ecuaciones diferenciales con deep learning: redes neuronales, retropropagación y método Deep Galerkin. Sin GPU.

OP-LoRA mejora el rendimiento de LoRA al añadir MLP temporal que se descarta. Logra hasta 15 puntos más en generación de imágenes.

Descubre AdaGrad++ y Adam++: algoritmos adaptativos sin parámetros que ofrecen convergencia garantizada. Optimiza deep learning sin ajustes manuales.

Mejora la precisión en predicción de demanda eléctrica con VMDNet, evitando fuga temporal mediante descomposición variacional y TCN.

Descubre IPBT, un nuevo algoritmo que optimiza hiperparámetros automáticamente en redes neuronales sin aumentar el presupuesto. ¡Mejora tus modelos!
Descubre cómo las ESN se comparan con ARIMA y ETS en pronóstico de series temporales. Análisis de hiperparámetros y benchmark M4.

Aprendizaje híbrido con minimización de nitidez (SAM) para estimar parámetros científicos de forma robusta y precisa, basado en Occam. ¡Descubre cómo!

Descubre un enfoque directo para manejar bandidos contextuales con estados latentes. Aprende cómo reducir el problema a bandidos lineales y mejorar las decisiones en entornos inciertos.

Descubre MoPE, un nuevo marco de codificación posicional con wavelets Morlet que unifica sinusoides y RoPE, mejorando atención y rendimiento en lenguaje.

Descubre SABER: refinamiento selectivo para transferencia positiva en aprendizaje continuo sin olvidar.

Descubre CRePE, método de poda post-entrenamiento para LLMs que reduce costos sin perder precisión, y PHO que acelera la búsqueda de hiperparámetros.

Descubre cómo la síntesis realista de ruido en MRI de difusión reduce el sesgo y mejora la estimación de microestructura tisular con machine learning supervisado.

Descubre cómo el tamaño de lote es el factor oculto que sesga la evaluación de LoRA. Optimízalo para mejores resultados.

Descubre cómo la teoría de perturbación local explica la interferencia entre dominios en RL multi-dominio y cómo un breve refresco recupera el rendimiento sin dañar otros.
Descubre cómo el escalado de PEFT permite crear millones de modelos personales persistentes sobre modelos base compartidos, transformando el fine-tuning en un sustrato compacto y eficiente.