Pronóstico robusto de la curva de rendimientos del Tesoro con ML
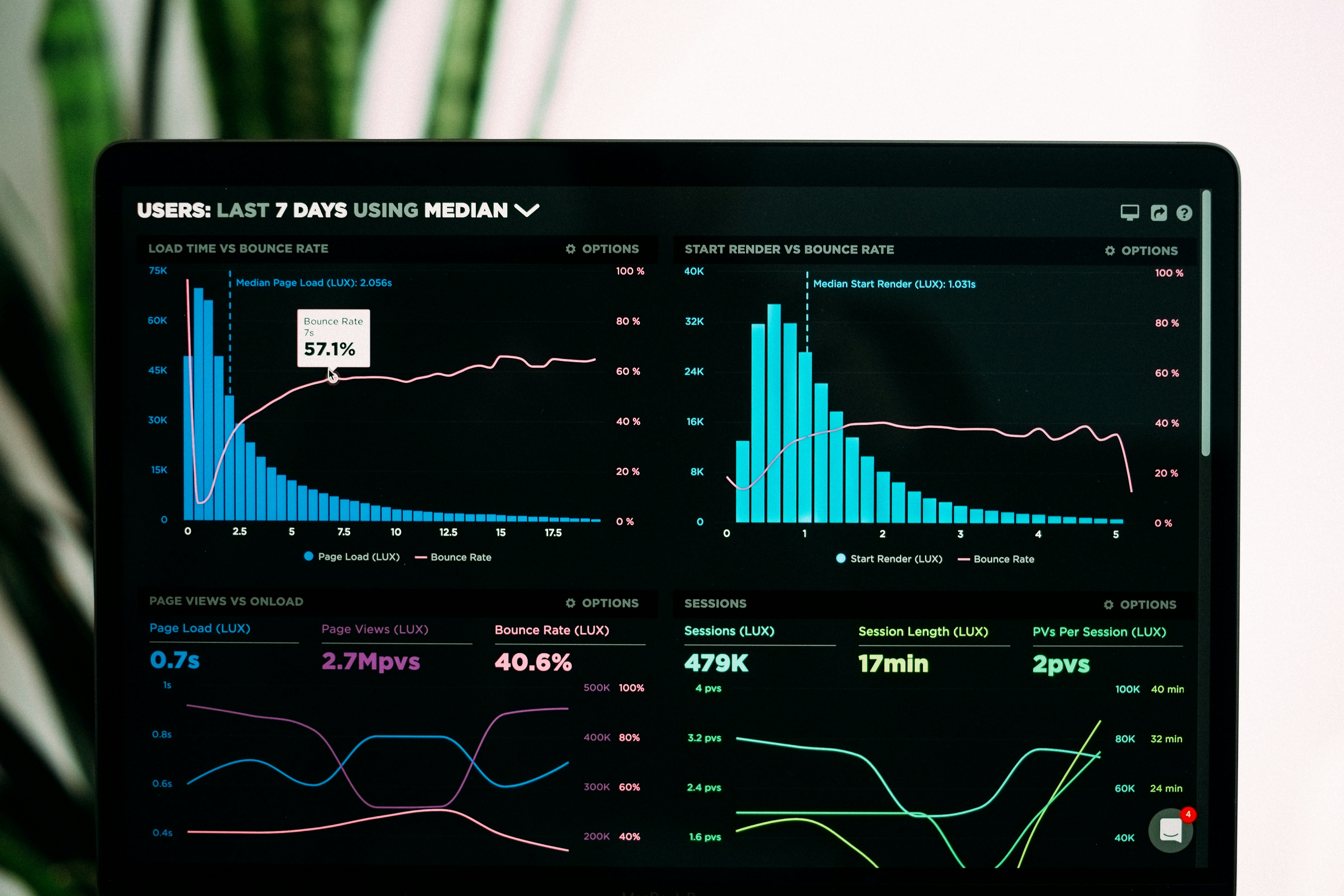
Descubre cómo un enfoque de machine learning robusto mejora el pronóstico de la curva de rendimientos del Tesoro y minimiza el riesgo de tipos de interés para
Descubre cómo un enfoque de machine learning robusto mejora el pronóstico de la curva de rendimientos del Tesoro y minimiza el riesgo de tipos de interés para

Descubre cómo Isira Adithya pasó de construir bombillas LED a graduarse y comprar una casa gracias a las recompensas por bugs. Una conversación exclusiva.

La IA está transformando la ciberseguridad: protege redes pero también habilita ataques. Conoce lo que los expertos recomiendan a los líderes de seguridad.

¿Por qué tu mejor vendedor renunciaría a un salario de $600,000? Descubre las razones detrás de este fenómeno y cómo retener a tus top performers en startups

Descubre HABC: mejora el fine-tuning de políticas VLA con recompensas binarias, alcanzando hasta un 92% de éxito en manipulación bimanual.

Descubre por qué el aprendizaje en grafos necesita ir más allá de las visiones restrictivas de las GNN espectrales y MPNN. Nuevo marco teórico unificado.

Descubre cómo un nuevo método de RL con supervisión CoT mejora la detección explicable de memes de odio y propaganda, superando benchmarks en inglés y árabe.

Descubre CoAgent: un sistema de control de concurrencia que permite a agentes LLM operar en paralelo sin conflictos, logrando corrección serializable con un

Descubre T-Mem, la primera memoria conversacional que anticipa. Combina recuperación descriptiva y asociativa para asistentes IA.

Descubre cómo los LLMs se evalúan entre sí con razonamiento multiagente para mejorar la precisión en preguntas médicas. Un enfoque de revisión por pares.

RETA reduce la tasa de éxito de ataques de inyección adaptativa a menos del 10% usando alineación de tareas con razonamiento. ¡Protege tus modelos!

El sobreentrenamiento en RLVR mejora Pass@1 pero reduce la diversidad en Pass@k. Conoce el colapso de diversidad y la solución BBG para mantener el
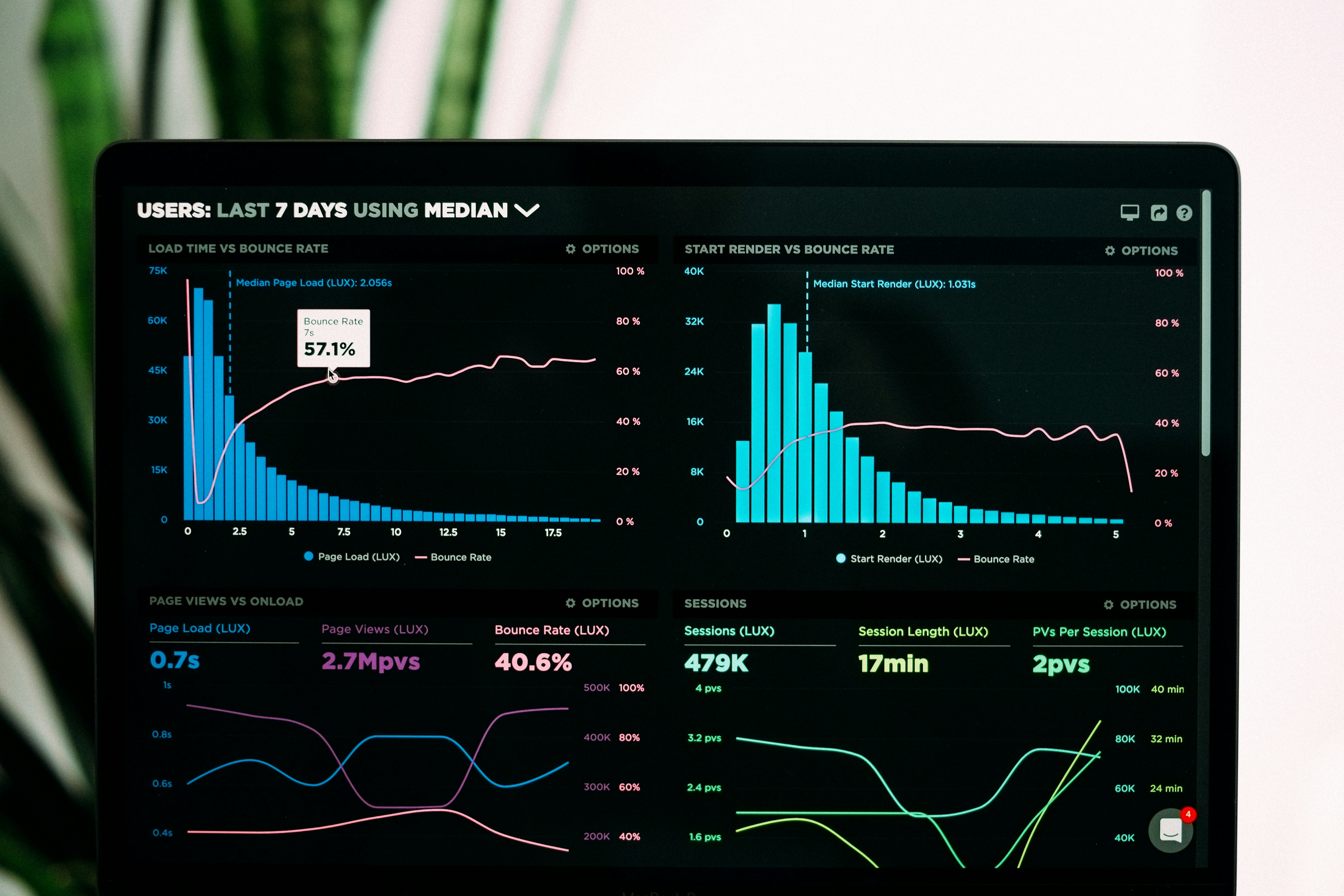
PRO y PRO-MAX reemplazan el replay sintético por memorias proyectadas, mejorando la retención en aprendizaje federado incremental heterogéneo.

Descubre cómo la meta-incertidumbre explica por qué el exceso de razonamiento en IA puede empeorar los resultados. Estudio con 7 modelos y 7.875 respuestas.

La precisión no basta: descubre cómo medir el reconocimiento de sesgos en cadenas de pensamiento. Datos reveladores: Claude 75% vs GPT-4o 13%.
Descubre cómo los bandidos contextuales aprenden las probabilidades de contagio en redes sociales para maximizar las recompensas del boca a boca estimulado.

Descubre las mejores herramientas de clienteling para retail en 2026. Conecta datos e-commerce con ventas en tienda y mejora la atribución.

Descubre cómo Knowledge Trap usa un Honeypot de Conocimiento para atrapar extracción de LLMs sin afectar usuarios legítimos. Defensa innovadora.

TIE: nuevo método para combinar modelos de difusión enmascarados usando trayectorias de decodificación seguras. Mejora razonamiento y generación.

Descubre Tyler, un marco de razonamiento latente tipado que mejora la precisión de los LLMs hasta 14 puntos sobre CoT. Aprende cuándo y cómo pensar.