
Derivación de optimización de políticas LLM: de recompensa a GRPO
Explora la derivación de optimización de políticas en LLM: de la recompensa esperada a GRPO. Un marco unificado que diagnostica fallos y guía el diseño de
Explora la derivación de optimización de políticas en LLM: de la recompensa esperada a GRPO. Un marco unificado que diagnostica fallos y guía el diseño de

La codicia se aprende: los incentivos visibles pueden hacer que la IA sacrifique su tarea por recompensas. Un peligro para la seguridad y alineación.

Descubre cómo GERS mejora la generalización en RL usando solo métricas escalares, superando a métodos tradicionales en entornos no vistos.

Aprende a obtener una política óptima desde una sola trayectoria en MDP promedio. Garantías de complejidad de muestra finitas con métodos libres de modelo.

Descubre cómo la máxima entropía permite recuperar políticas óptimas en juegos de campo medio a partir de demostraciones expertas. Algoritmos eficientes con

Descubre GD²PO, un nuevo método que resuelve conflictos multi-recompensa en RL, mejorando la eficiencia del entrenamiento de LLMs con filtrado dinámico de
ExpRL usa recompensas densas para potenciar el razonamiento de LLMs en entrenamiento intermedio, superando a SFT y GRPO.

¿La privacidad diferencial realmente protege contra ataques backdoor? Este estudio revela que puede enmascararlos, con el ataque RING alcanzando un 90% de
Descubre las 5 plataformas más confiables para vender skins de CS2 al instante. Comparativa de velocidad, comisiones y seguridad. ¡Maximiza tus ganancias!

Descubre cómo Evolution API revoluciona la automatización de WhatsApp. Integración sencilla, sin límites de Meta, y casos prácticos con n8n. ¡Optimiza tu

La gobernanza de IA se vuelve crítica en Australia. Descubre las preguntas clave que los líderes deben responder para escalar la IA de forma segura y cumplir

Acelera tus pagos online con una pasarela PayPal verificada. Seguridad, rapidez y confianza para tu negocio. ¡Descubre cómo!

Descubre cómo la IA en la automatización de pedidos impulsa una cultura de transparencia, responsabilidad y mejora continua en tu empresa.
¿Recibes Warning: Message parser reports malformed message packet? Aprende a solucionarlo limpiando caché DNS o reseteando resolver. Guía paso a paso.

Descubre cómo los condensados de polaritones a temperatura ambiente revolucionan el modelado generativo, superando métodos digitales en precisión y diversidad.
Descubre GRACE-DS, un entorno de evaluación para agentes AutoML basados en LLM que mide rendimiento, corrección y alineación con recompensas guiadas.

Descubre el control data-driven con compensación en tiempo real que optimiza la combustión en motores multicombustible, superando incertidumbres.

Descubre cómo DRA-GRPO mejora el razonamiento matemático en LLMs al diversificar caminos de recompensa, logrando 58.2% de precisión con solo 7000 muestras y

Descubre cómo el aprendizaje autosupervisado se transforma en un proceso de comunicación discreta entre redes, mejorando la estructura de las representaciones
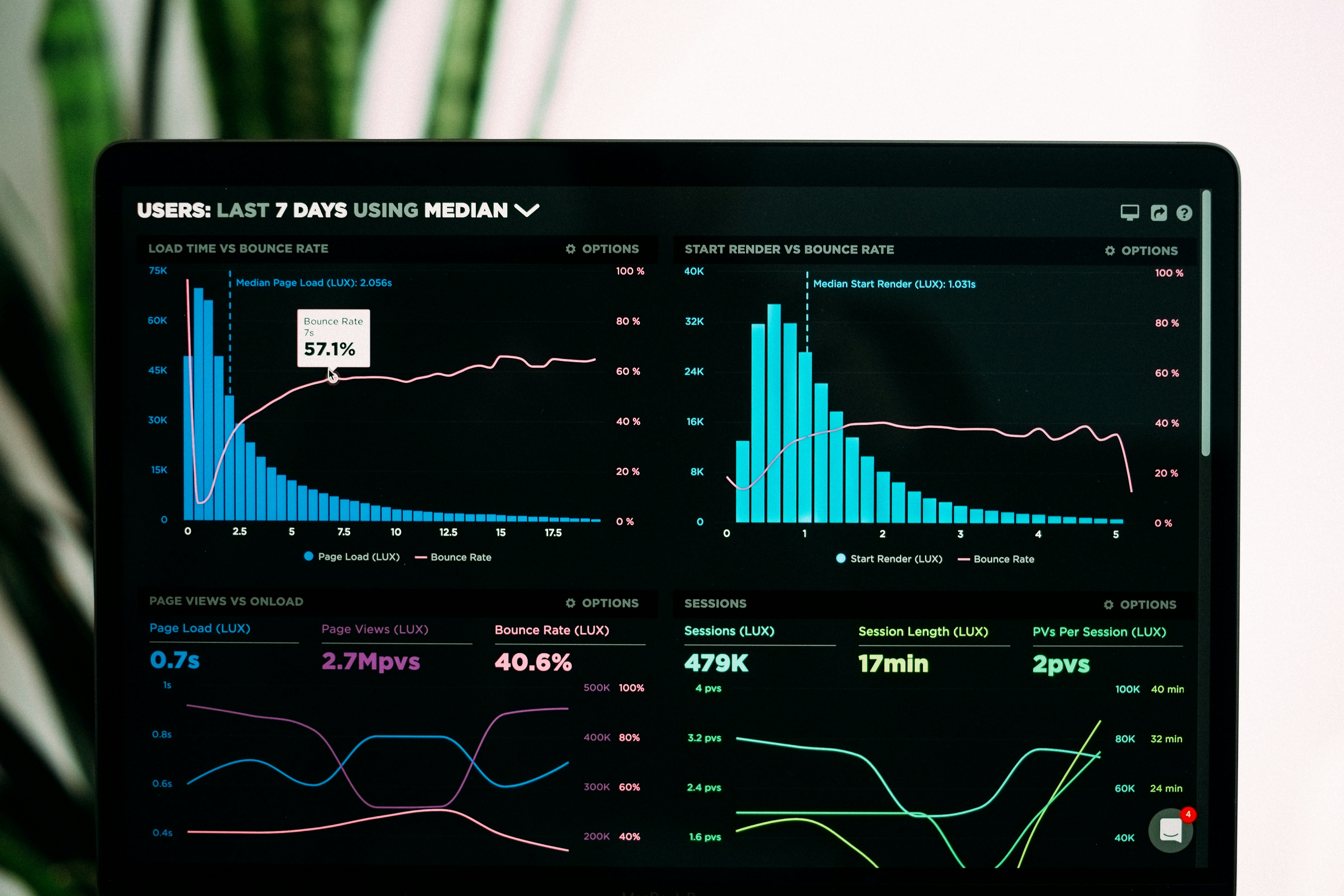
Descubre cómo un enfoque de machine learning robusto mejora el pronóstico de la curva de rendimientos del Tesoro y minimiza el riesgo de tipos de interés para