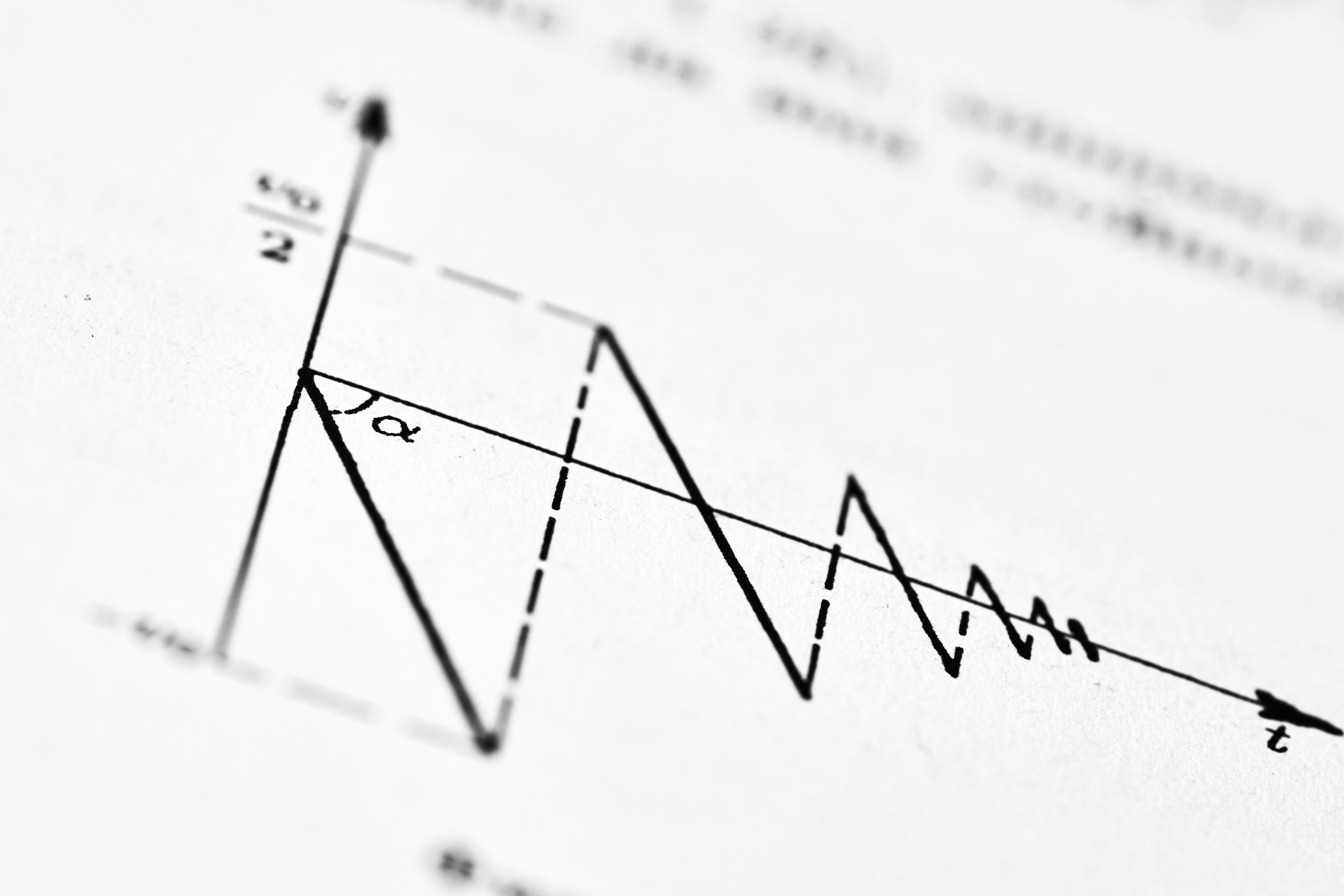
Momentum para razonamiento: Señales intrínsecas densas en optimización
Descubre cómo ISPO mejora el razonamiento en LLMs con señales intrínsecas, superando fallos de GRPO como colapso y certeza alucinada.
Descubre cómo ISPO mejora el razonamiento en LLMs con señales intrínsecas, superando fallos de GRPO como colapso y certeza alucinada.

Descubre cómo T²-GRPO optimiza agentes cuidadores con recompensas del entorno, mejorando la atención en demencia con seguridad y eficiencia.

Descubre cómo la diversidad en esquemas de pensamiento mejora el razonamiento de los LLMs. DiScO optimiza políticas para resultados más precisos y recuperación

OpenAI y Visa se alían para que ChatGPT realice compras con tu tarjeta. Descubre cómo los agentes de IA revolucionarán el comercio online.

LATTEArena: el primer marco competitivo para evaluar ingeniería de características con LLM. Analiza coste-efectividad, rendimiento y robustez con más de 4000

Descubre el primer análisis completo de seguridad en LLMs personalizados: mecanismos, riesgos, mitigaciones y evaluación. ¡Protege tus modelos!
Descubre cómo un oráculo de atención reduce el coste de prefill en modelos híbridos de contexto largo, manteniendo calidad y acelerando inferencia hasta 1.93x.

Mejora el alineamiento de LLMs con SAW, ponderación dinámica que optimiza el aprendizaje multiobjetivo sin apenas coste computacional.
Rosetta Memory adapta la memoria entre modelos de lenguaje como GPT y Claude. Optimiza la escritura y lectura para mejorar tareas complejas. ¡Descubre su

Descubre SHIELD-IDS, el nuevo enfoque basado en XGBoost y LightGBM que detecta intrusiones con más del 99% de precisión incluso bajo ataques adversarios.

Descubre SHIELD-IDS: el ensemble heterogéneo con defensa en capas que logra >99% de precisión en IDS frente a ataques adversariales.

Descubre cómo el Process Mining revela patrones ocultos de resistencia y vulnerabilidad en LLMs ante ataques de Red Team, más allá de la simple tasa de éxito.

Aprende cómo la multiplicidad de modelos detecta ataques de envenenamiento en SLM en dispositivos edge, mejorando la seguridad antes que defensas clásicas.

Descubre cómo la coherencia tensa revela fallos inminentes en agentes de IA. Un detector con 94% de precisión identifica cuándo un agente ignora sus propias

La multiplicidad de modelos detecta ataques de envenenamiento en dispositivos edge, mejorando la seguridad en entrenamiento distribuido de SLM.

Investigación revela que agentes de IA alertan de fallos antes de cometerlos. Conoce el patrón de coherencia forzada y su detección con un 94% de precisión.

Descubre cómo Patcher protege los modelos de lenguaje contra ataques de fine-tuning malicioso escalando ataques adversariales. Mejora la robustez de tus LLMs.

CausShield protege tu modelo de aprendizaje federado vertical contra ataques de reconstrucción de muestras usando representación causal. Logra el mejor

Descubre cómo el bucle hacker-fixer protege benchmarks de agentes contra reward hacking, eliminando el 100% de exploits en KernelBench. Una solución

Descubre cómo la incertidumbre en RLHF se unifica con un modelo distribucional, mitigando el reward hacking. Clave para optimización robusta.