Más allá de lo visual: razonamiento CoT en segmentación médica semi-supervisada
CERS integra razonamiento CoT para superar limitaciones visuales en segmentación médica semi-supervisada, mejorando precisión y consistencia semántica.
CERS integra razonamiento CoT para superar limitaciones visuales en segmentación médica semi-supervisada, mejorando precisión y consistencia semántica.

CreDRO aprende ensambles credales que capturan incertidumbre epistémica real, mejorando la detección de anomalías y clasificación selectiva en aplicaciones

Un agente de IA fusiona modelos LSTM, monitoreo de velocidad y redes para detectar fraudes y lavado de dinero en banca. Logra F1 0.78-0.87 y chatbot con 96.6%

Descubre cómo SuCo reduce tokens y mejora precisión en modelos de IA. Optimización del razonamiento con cadenas de pensamiento suficientes.

Descubre los teoremas No-Free-Fairness: la desigualdad en IA no es solo por datos sesgados, sino por límites intrínsecos. Aprende los trade-offs para construir

¿Los modelos auto-supervisados como wav2vec2.0 compensan el contexto tonal? Un estudio revela que no, a diferencia de modelos ajustados para ASR. Lee más.

El método NNN mejora la recuperación de información seleccionando documentos diversos sin redundancia, superando a la búsqueda densa tradicional.

Aprende a predecir ciberataques desde observaciones del agente rojo con aprendizaje por imitación para fortalecer defensas autónomas con IA neurosimbólica.
Descubre cómo un portal de socios con registro de acuerdos transforma la cultura empresarial, fomentando transparencia, responsabilidad y colaboración.

Descubre cómo la incorporación automatizada de clientes impulsa la transformación digital ecológica, combinando tecnología y sostenibilidad.

La incorporación automatizada de clientes fomenta transparencia, responsabilidad y mejora continua. Descubre cómo transforma la cultura empresarial con
Descubre cómo la optimización de la peor dimensión supera las fallas ocultas en modelos de razonamiento multimodal, mejorando la consistencia lógica y visual.

PAFO optimiza modelos de recompensa personalizados con equidad de Pareto, reduciendo el sesgo hacia grupos minoritarios.

Los MLLMs fallan al detectar respuestas ausentes en video. Este estudio diagnostica el problema y evalúa la cadena de pensamiento como mitigación.
¿Son reproducibles los resultados de trading con LLM? Este artículo analiza los supuestos de ejecución y propone estándares para mejorar la comparabilidad.

GIFT usa LLMs para diseñar estados y recompensas en RL financiero, mejorando el rendimiento de carteras. Descubre cómo optimizar tus inversiones.

PAEC calibra la entropía solo en posiciones clave para evitar el colapso y mejorar el razonamiento de LLMs en problemas matemáticos. ¡Aumenta el rendimiento!

Descubre cómo los LLMs con razonamiento y verificación mejoran la predicción de trayectorias y destino de buques a 30 días, superando a métodos tradicionales.
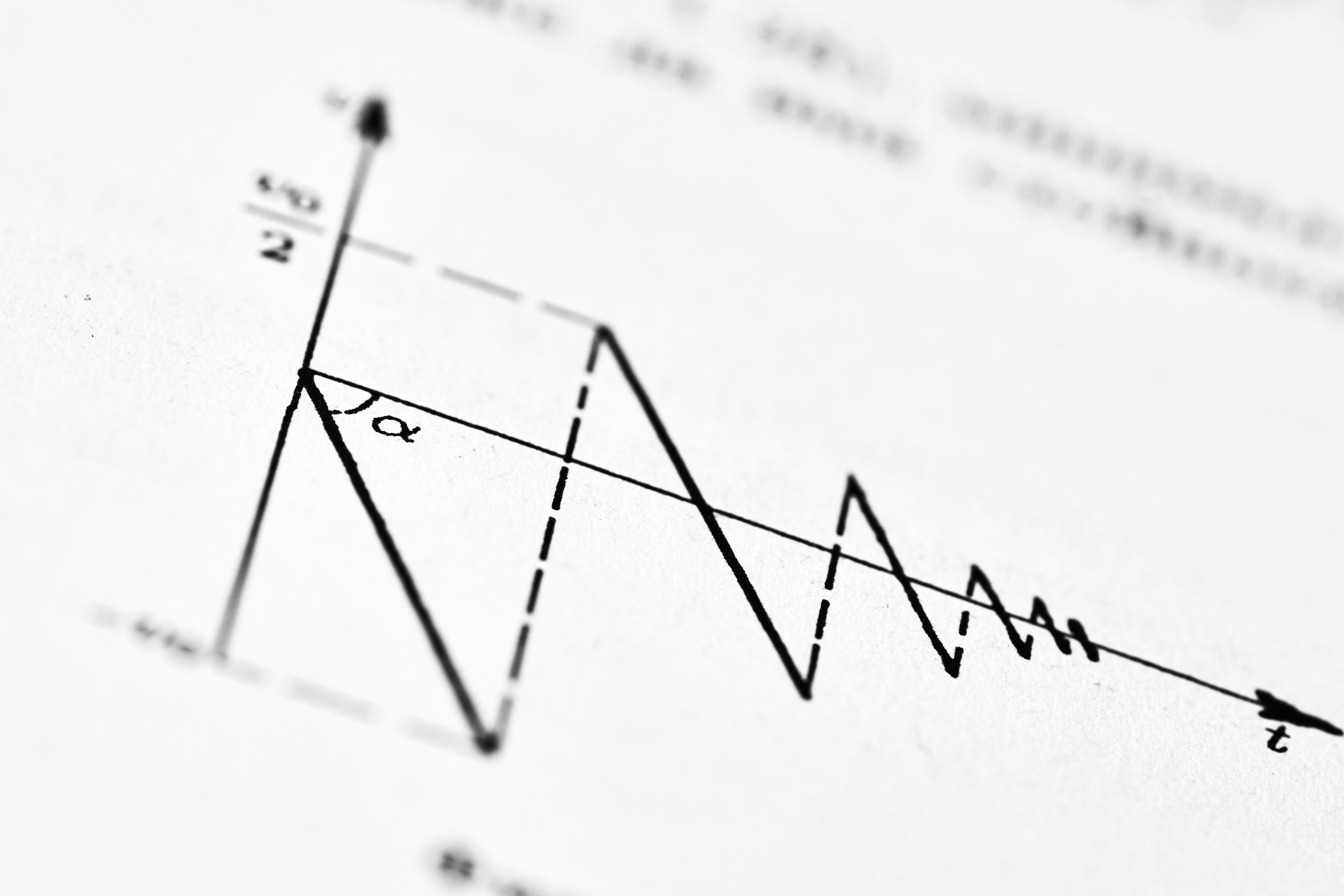
Descubre cómo ISPO mejora el razonamiento en LLMs con señales intrínsecas, superando fallos de GRPO como colapso y certeza alucinada.

Descubre cómo T²-GRPO optimiza agentes cuidadores con recompensas del entorno, mejorando la atención en demencia con seguridad y eficiencia.