
MLUBench: Evaluación del desaprendizaje continuo en MLLMs
MLUBench: benchmark para desaprendizaje continuo en MLLMs. Revela grave degradación acumulativa. LUMoE mitiga el problema preservando la alineación multimodal.
MLUBench: benchmark para desaprendizaje continuo en MLLMs. Revela grave degradación acumulativa. LUMoE mitiga el problema preservando la alineación multimodal.
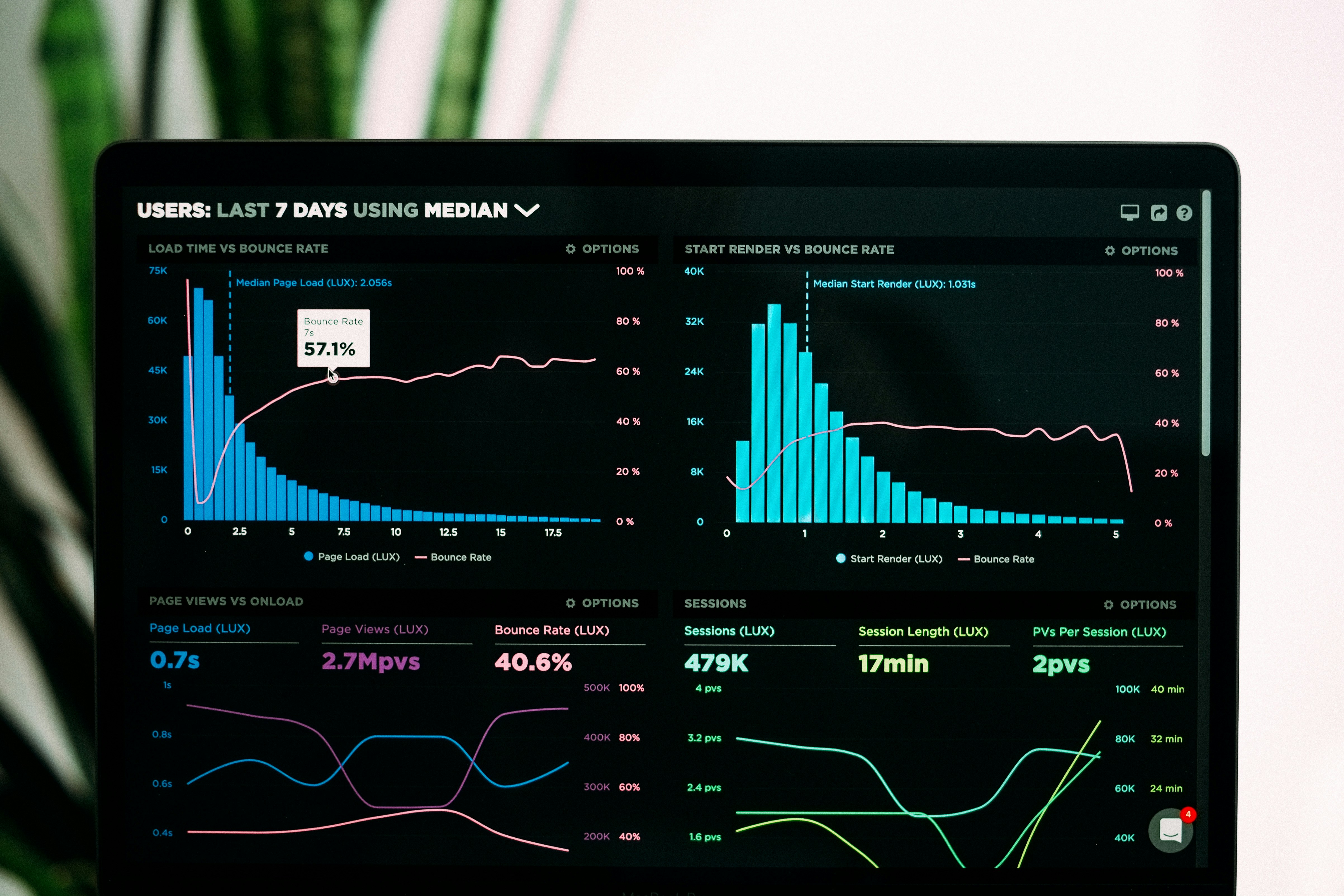
El colapso de parseo limita el ranking multimodal. PRISMR usa hiperred y LoRA para internalizar listas, mejorando rendimiento y reduciendo errores. ¡Descúbrelo!

Evaluamos modelos fundacionales multimodales para detectar defectos en redes eléctricas. Percepción, razonamiento y automatización en un solo marco.
Descubre cómo V-RAGBench y CARVE revolucionan la recuperación en videos largos, combinando múltiples modalidades y granularidades. Mejora la precisión de tu RAG.
Descubre UXBench, un nuevo benchmark con 2000 muestras para evaluar el razonamiento UX en modelos multimodales. UI-UX alcanza un 79.63% de precisión.

Ahorra hasta 22x en costes cloud con Brick, el router multimodal que enruta cada consulta al modelo ideal. Precisión del 76.98%.

Descubre MOSAIC, un framework de aprendizaje continuo que supera los desafíos de nuevos sensores en la evaluación del Parkinson.

Descubre IterCAD, un agente multimodal que revoluciona la generación y edición de CAD con cierre de bucle, precisión geométrica y ejecución de código.

Descubre IterCAD, un agente multimodal que revoluciona la generación y edición de CAD con IA iterativa. Benchmark y precisión sin sesgo.
Descubre cómo MiniMax Sparse Attention (MSA) reduce 28.4 veces el cómputo de atención en contextos de 1M tokens, logrando aceleraciones de hasta 14.2x en prefill y 7.6x en decoding en GPUs H800.

Atención dispersa para contextos de 1M tokens: MiniMax Sparse Attention reduce cómputo 28x y acelera prefill 14x y decoding 7x en GPUs H800.
Comparativa de arquitecturas flexibles para modelos multimodales geoespaciales. Analizamos trade-offs en flexibilidad, alineamiento y rendimiento en clasificación y segmentación.

Descubre M*, el sistema de serving que reduce la latencia hasta un 20% en modelos multimodales, superando a vLLM-Omni. Ideal para arquitecturas compuestas de IA.

Descubre DIMOS, el nuevo método que combina eventos e imágenes para segmentar objetos en movimiento con gran precisión, incluso en baja luz y movimiento rápido.

Aislamiento modal en razonamiento intercalado reduce coherencia. MoTiF supervisa transiciones con refuerzo paso a paso para mejorar precisión en tareas.

scLLM-DSC: un novedoso marco de clustering multimodal que aprovecha grandes modelos de lenguaje para mejorar la precisión en el análisis de células individuales.
CausalMoE, un modelo multimodal, revoluciona la detección causal de Granger usando expertos heterogéneos y patrones temporales, integrando LLMs y VLMs.

scLLM-DSC mejora el clustering de scRNA-seq integrando conocimiento de LLM y supera 11 métodos. Conoce este avance en bioinformática.

Descubre CausalMoE, el primer modelo fundacional multimodal que integra LLMs y VLMs para descubrimiento causal Granger preciso en series temporales complejas.
Descubre cómo ReFoCUS utiliza aprendizaje por refuerzo para seleccionar fotogramas clave en video, mejorando la precisión en tareas de comprensión contextual.