
Cómo la modernización de apps legacy impulsa el crecimiento
Descubre cómo modernizar aplicaciones legacy reduce costos, acelera el time-to-market y desbloquea nuevas fuentes de ingresos. Impulsa tu negocio con Q2BSTUDIO.
Descubre cómo modernizar aplicaciones legacy reduce costos, acelera el time-to-market y desbloquea nuevas fuentes de ingresos. Impulsa tu negocio con Q2BSTUDIO.

Descubre cómo modernizar aplicaciones heredadas reduce costos, mejora seguridad y escalabilidad, y posiciona tu negocio para el futuro. ¡Optimiza tu TI!

Descubre cómo el aprendizaje por refuerzo inverso mejora la eficiencia de modelos de comportamiento robótico, logrando tasas de éxito superiores al 90% en tareas complejas de manipulación.

Descubre cómo la modernización de aplicaciones heredadas genera un alto ROI: reducción de costos, aumento de ingresos y ventaja competitiva. Guía completa.

Descubre el ROI de modernizar aplicaciones legacy: reduce costos, aumenta ingresos y mejora la competitividad. Conoce cómo Q2BSTUDIO maximiza tu inversión.

Descubre cómo el modelo bayesiano no negativo (BNRM) mitiga el hackeo de recompensas en RLHF, mejorando la robustez y la interpretabilidad de los modelos de lenguaje.

Descubre las ventajas de modernizar aplicaciones heredadas: mayor agilidad, reducción de costos, escalabilidad y seguridad. Transforma tu negocio con Q2BSTUDIO.

Descubre cómo DrPO optimiza modelos generativos de un paso sin necesidad de gradientes de recompensa, mejorando la alineación y reduciendo el costo computacional.
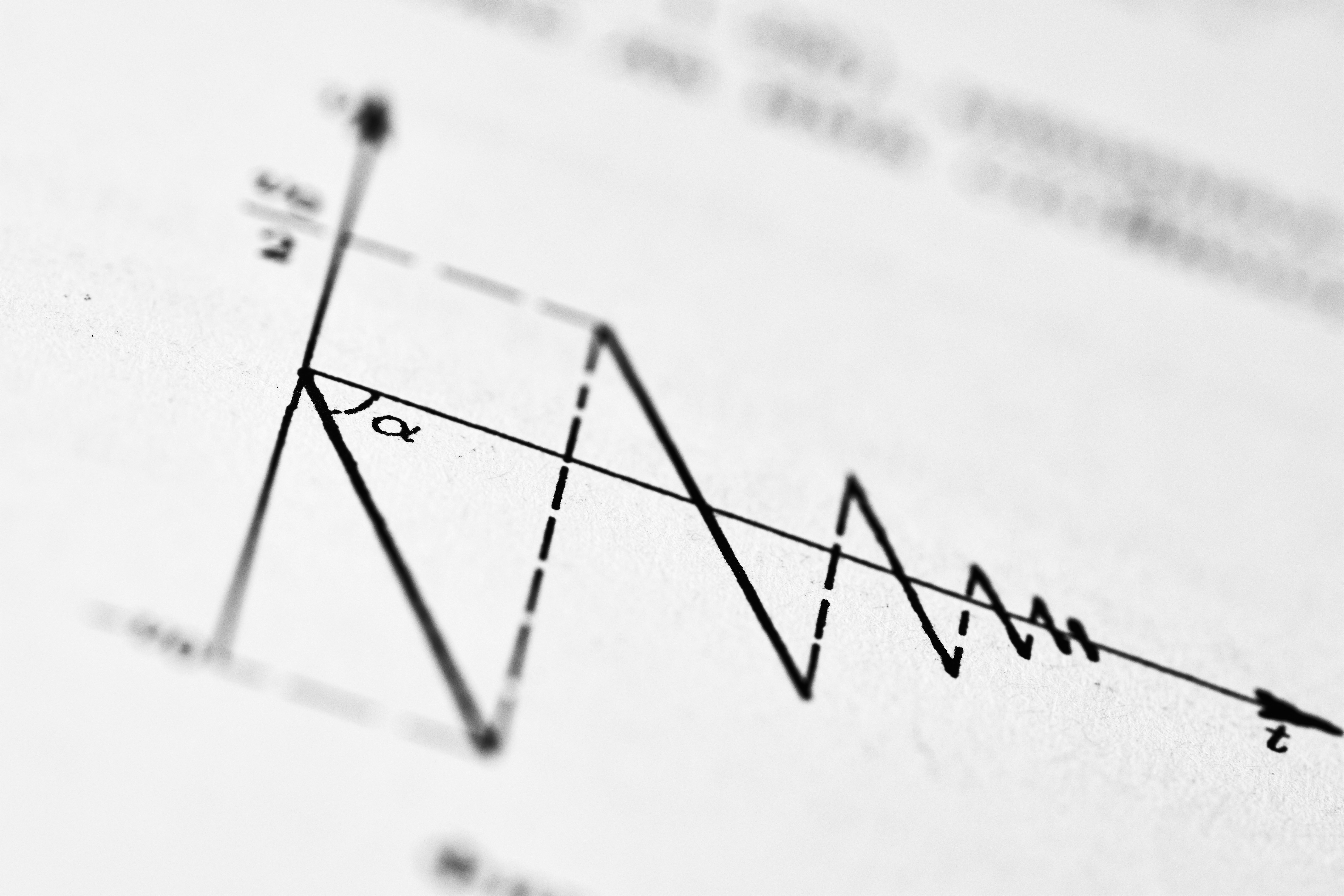
Los modelos de recompensa en IA tienen sesgos. La recompensa mecánica los mitiga con pocos datos. Optimiza la alineación de modelos de lenguaje.

Agente de RL optimiza señales de excitación para identificación de parámetros en sistemas mecatrónicos, superando métodos clásicos con solo 0.75% de violaciones

Aprende cómo los LLMs mejoran el diseño de recompensas en RL cooperativo multiagente, logrando mayor rendimiento en Overcooked.
EST-PRM pone a prueba la estabilidad de los modelos de recompensa de proceso ante transformaciones que distorsionan la calibración de recompensas.

Descubre cómo In2AI revolucionó el entrenamiento multi-agente con atribución retrasada de recompensa, logrando que un modelo de 8B superara a GPT-5 en MindGames Arena.

Descubre PaW: co-entrenamiento de políticas y modelado del mundo para agentes de lenguaje. Mejora el aprendizaje por refuerzo sin modificar la inferencia.

Descubre cómo un nuevo método de perturbación perceptual y modelado de recompensa corrige el sesgo en evaluaciones de LLMs multimodales. Más preciso y alineado con humanos.

Descubre cómo LEMAE usa LLMs para identificar estados clave y acelerar la exploración multiagente, con menos redundancia. Resultados superiores en SMAC y MPE.

CAST optimiza el RLVR con autoenseñanza no privilegiada y asignación de ventajas token en grupos de varianza cero. Mejora el razonamiento.
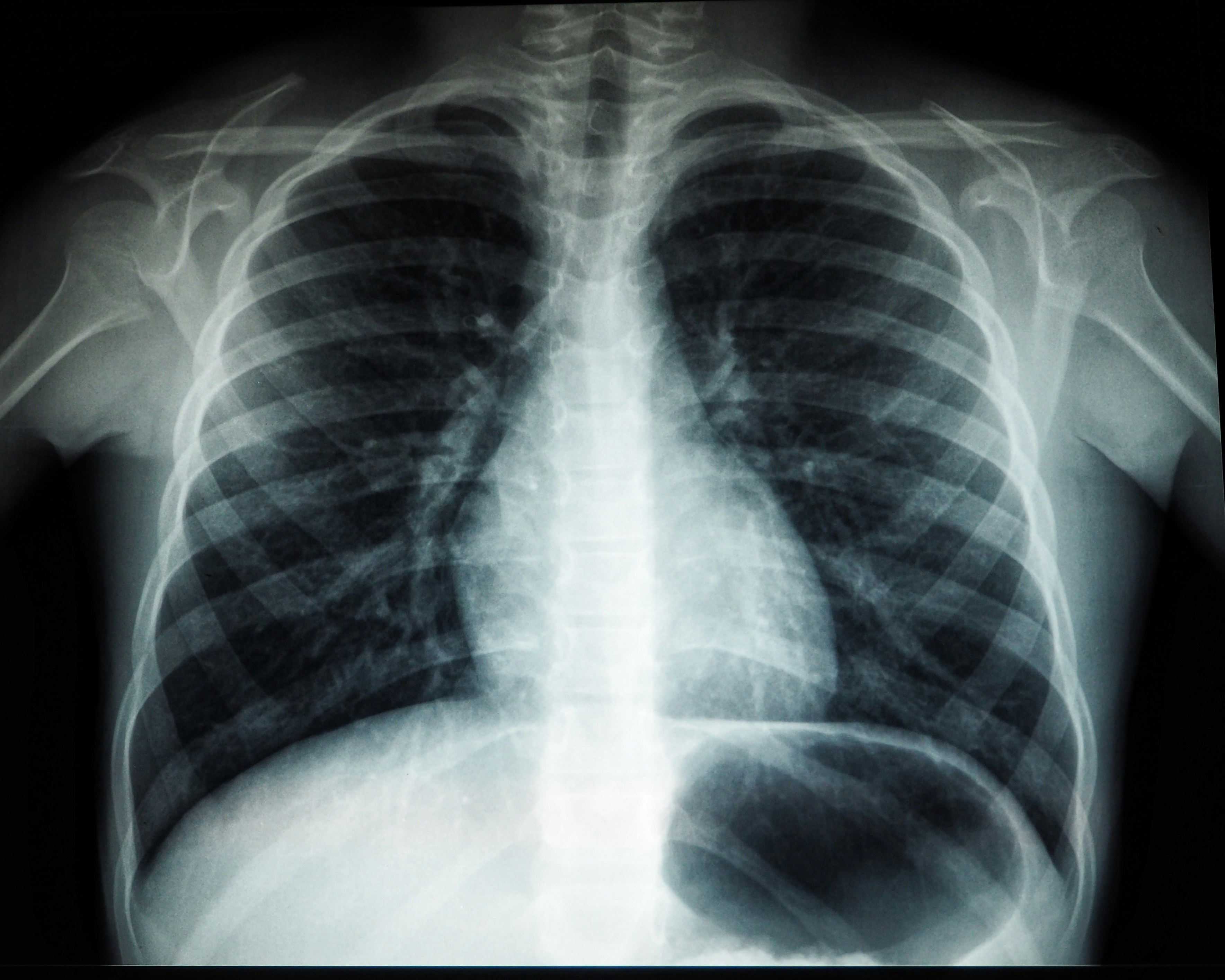
Mejora la generación automática de informes de rayos X de tórax con recompensas Set-Distance. Resultados: +6.8% BERTScore, +7.82% RadGraph, +4.45% CheXbert.

Descubre cómo Latent Reward Steering optimiza el razonamiento de LLMs al promover comportamientos cognitivos implícitos.
Descubre cómo el fuzzing de verificadores RLVR revela bugs antes de que el modelo los aprenda. Mejora la seguridad de tu IA con métricas clave.