
Internalizar la temperatura: autodestilación para recalentar políticas en RL
Descubre cómo TS-OPSD recalienta políticas en RL sin profesor externo, restaurando entropía colapsada para mejorar el razonamiento de LLMs.
Descubre cómo TS-OPSD recalienta políticas en RL sin profesor externo, restaurando entropía colapsada para mejorar el razonamiento de LLMs.

Nuevo marco logra robustez óptima en paginación asistida por aprendizaje, cerrando brecha al ratio H_k. Resultados experimentales demuestran su eficacia.

Descubre cómo las redes neuronales gráficas reconstruyen mapas de temperatura urbana con incertidumbre a partir de sensores limitados. Ideal para monitoreo climático y riesgo de calor.

¿Cómo retener a tus empleados estrella? Estrategias prácticas para evitar que se vayan antes de 4 años. Consejos de expertos.
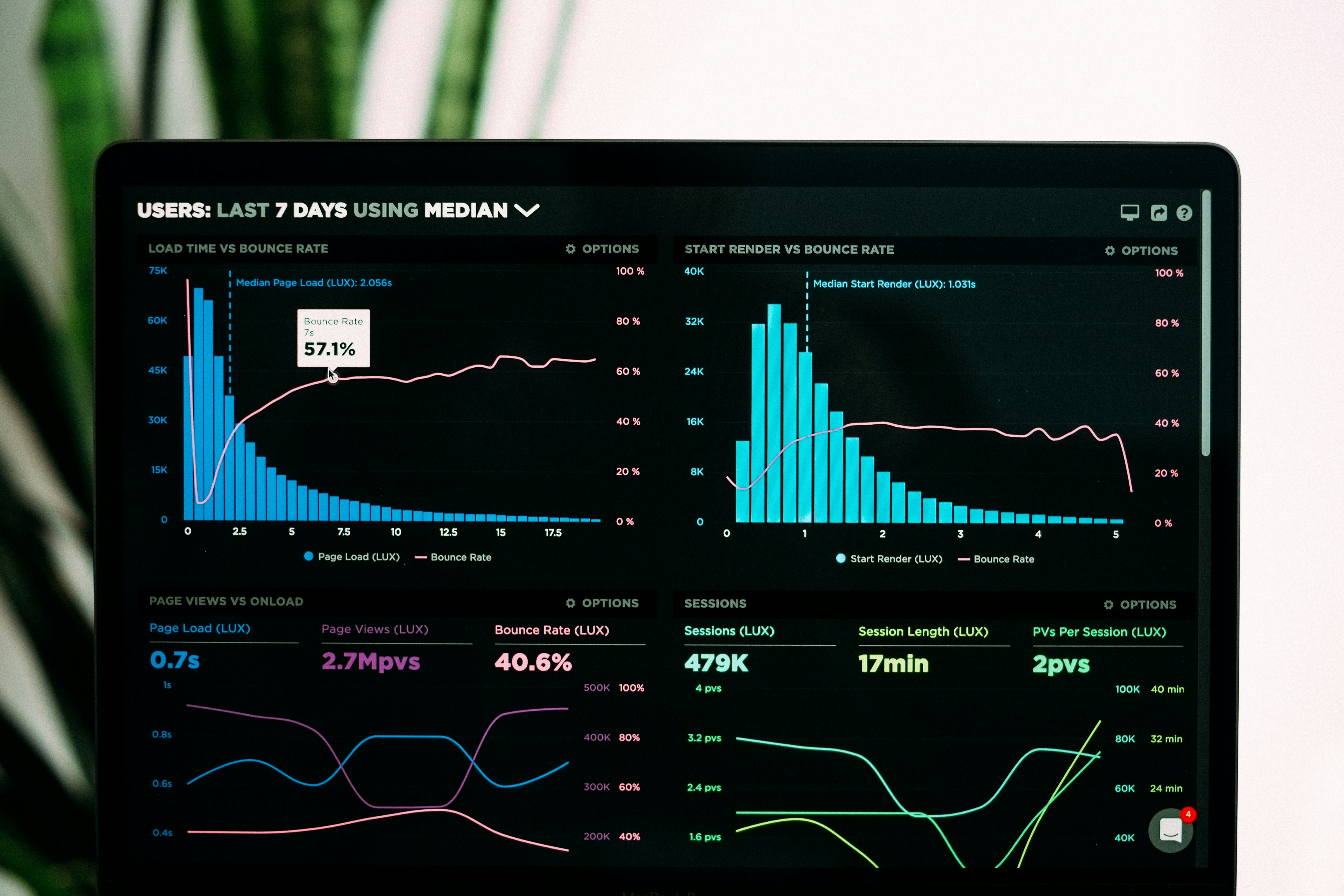
Descubre cómo un enfoque multi-tarea optimiza precisión y diversidad al combinar modelos de pronóstico mediante deep learning. Resultados superiores en M4 y tráfico real.

Descubre cómo los modelos de juego potencial revelan transiciones críticas en el aprendizaje federado, optimizando el equilibrio entre esfuerzo y recompensa.

Descubre dilema en predicción conforme transductiva: mayor confianza implica conjuntos exponencialmente grandes. Nuevo algoritmo supera métodos tradicionales.
Descubre cómo FM-IRL combina Flow-Matching con RL para mejorar la exploración y generalización en políticas de aprendizaje por refuerzo.
Descubre cómo Tempora evalúa la adaptación en tiempo de prueba bajo presión temporal. Conoce métricas para elegir el mejor método según latencia y precisión.

Aprende cómo la teoría centrada en tareas y currículos fáciles a difíciles permiten la auto-mejora iterativa de LLMs con garantías de rendimiento.

Un método innovador con autoencoders revela brechas ocultas en LLMs y benchmarks. Mejora la evaluación de modelos de IA identificando conceptos débiles.

Compite por más de $51K en el Hackathon Decentralize AI. Construye IA descentralizada con GPU y almacenamiento permanente. ¡Inscríbete!

El plan federal de IA incluye un nuevo fondo para impulsar empresas nacionales. Conoce las claves para aprovechar esta inversión en tu negocio.

Los modelos de dinámica inversa predictiva superan a la clonación de comportamiento en eficiencia de muestras. Explicación teórica y validación empírica.

Descubre lo que más sorprendió a un maratonista en su primera competencia Hyrox. ¿Es más duro que un maratón? Lee la comparativa.

Aprende cómo LiDAR acelera 9.5x la guía de recompensa en modelos de difusión, mejorando la alineación con intenciones humanas.
El nuevo método CPT mejora el equilibrio entre razonamiento y metacognición en LLMs, logrando +2.2 puntos en matemáticas y +5.2 en F1 de abstención. Descubre cómo.

Nuevo marco de aprendizaje por refuerzo offline que aprende representaciones sin recompensa y las afina con preferencias humanas, superando a métodos tradicionales en eficiencia.

Descubre por qué la modernización de aplicaciones legacy es el sistema nervioso digital: integración, automatización y resiliencia para tu ventaja competitiva.

Descubre RDA, un agente basado en VLM que diseña recompensas semánticas para robots. Logra políticas alineadas con instrucciones humanas en manipulación.