
KnapSpec: Decodificación Especulativa con Selección Adaptativa de Capas
KnapSpec acelera inferencia LLMs hasta 1.47x sin entrenamiento. Selecciona capas adaptativas como problema mochila. Optimiza rendimiento en secuencias.
KnapSpec acelera inferencia LLMs hasta 1.47x sin entrenamiento. Selecciona capas adaptativas como problema mochila. Optimiza rendimiento en secuencias.

DriftSched optimiza la programación GPU multi-inquilino con compensación adaptativa de deriva de tokens, reduciendo latencia un 42% y mejorando QoS.

Descubre cómo MTPC acelera LLMs con circuitos probabilísticos, logrando rapidez y expresividad sin pérdida de calidad.
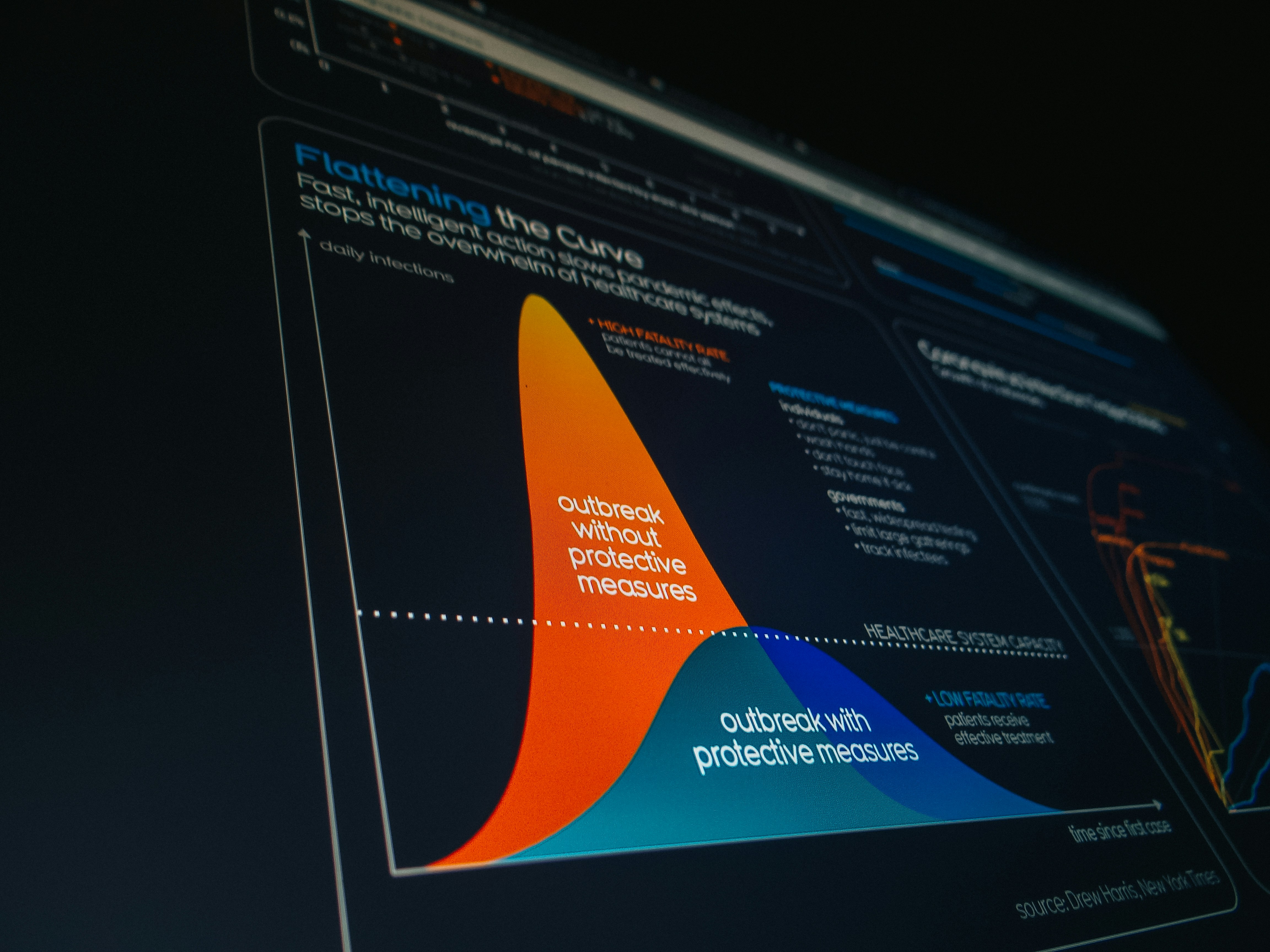
Aprende cómo c-TPE optimiza hiperparámetros bajo restricciones de memoria y latencia, superando métodos tradicionales en problemas costosos.

Evaluamos el rendimiento de seis apps de videollamada con IA. ¿Qué importa más: latencia o capacidad del modelo? Resultados sorprendentes.

ViBE reduce el desequilibrio en la ejecución de MoE hasta un 45% en P90 TTFT, mejorando el cumplimiento de SLO en un 14%. Optimiza colocación de expertos según rendimiento GPU.

Conoce ConServe: programación por conversación para agentes LLM, reduce latencia 51% y mejora eficiencia energética en servidores IA.

DuetServe armoniza prefill y decode en LLMs con multiplexación adaptativa de GPU. Mejora el throughput 1.3x manteniendo baja latencia. Descúbrelo.
Descubre cómo Tempora evalúa la adaptación en tiempo de prueba bajo presión temporal. Conoce métricas para elegir el mejor método según latencia y precisión.
Descubre cómo Avatar Forcing permite generar avatares interactivos en tiempo real que reaccionan a tu voz y gestos, con baja latencia y sin etiquetado. ¡Más del 80% de preferencia!

Descubre ASKD-Whisper, una técnica de destilación adaptativa que acelera 5x el reconocimiento de voz y supera al profesor en precisión.

¿Tu agente de voz falla en producción? Descubre las 7 mejores plataformas de testing de audio, simulación y observabilidad. Elige la correcta.
Guía para evaluar RAG con agentes en producción: métricas, herramientas y consejos para medir fidelidad, recuperación, latencia y costo.
RTSP sigue vivo: descubre por qué este protocolo de 1998 es clave en videovigilancia y robótica con baja latencia y simplicidad.
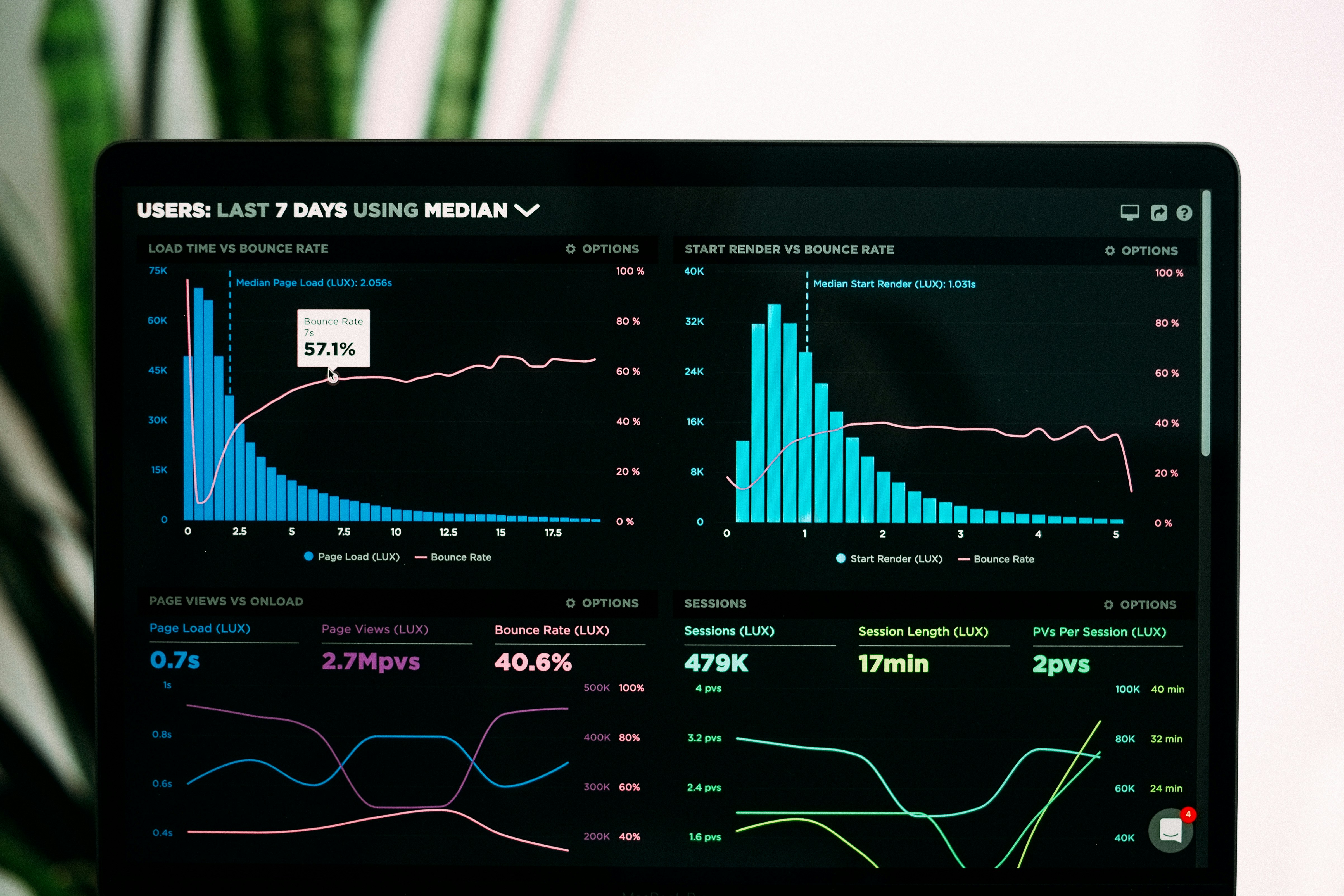
Descubre cómo las consultas pushdown reducen la latencia de API hasta 5x y el consumo de memoria 160x frente al filtrado en memoria. Resultados de benchmark.
Comparamos 4 transformers ligeros contra ML tradicional en 3 datasets reales. Solo TinyBERT-4L sobrevivió a la cuantización y latencia. Descubre qué modelo usar en edge.

Reemplacé una costosa API de LLM por un motor NLP offline en JavaScript: latencia 0ms, costo cero y privacidad total. ¡Pruébalo!

Leyline introduce directivas para editar la caché KV sin re-prefill completo. Reduce latencia hasta 241 ms y mejora tasa de resolución en +14.3 pp.

Descubre cómo una arquitectura 6G-LLM reduce la latencia un 75% y aumenta el éxito de misiones un 68% en redes de vehículos autónomos tácticos.

Las SNNs con codificación de latencia alcanzan un 92% de precisión en detección de intrusiones, ideales para entornos de bajo consumo.