
FusionRS: Dataset de teledetección RGB-Infrarrojo para modelos visión-lenguaje
Descubre FusionRS, el primer dataset RGB-Infrarrojo-texto para teledetección. Mejora alineación y descripciones multimodales.
Descubre FusionRS, el primer dataset RGB-Infrarrojo-texto para teledetección. Mejora alineación y descripciones multimodales.

Descubre cómo la atención selectiva, no la escala del modelo, mejora la alineación entre humanos e IA en la predicción del lenguaje multimodal. Estudio con 600

Aprende cómo un mecanismo de atención ligero mejora la robustez en sistemas multimodales usando un selector top-down. Resultados en MM-IMDb.
Mejora la robustez de sistemas multimodales con un selector de modalidad ligero. Basado en la Teoría del Espacio Global, ofrece resultados superiores incluso

Descubre AIQI, el primer agente de IA universal sin modelo que demuestra optimalidad asintótica en aprendizaje por refuerzo general. ¡Revoluciona la IA!
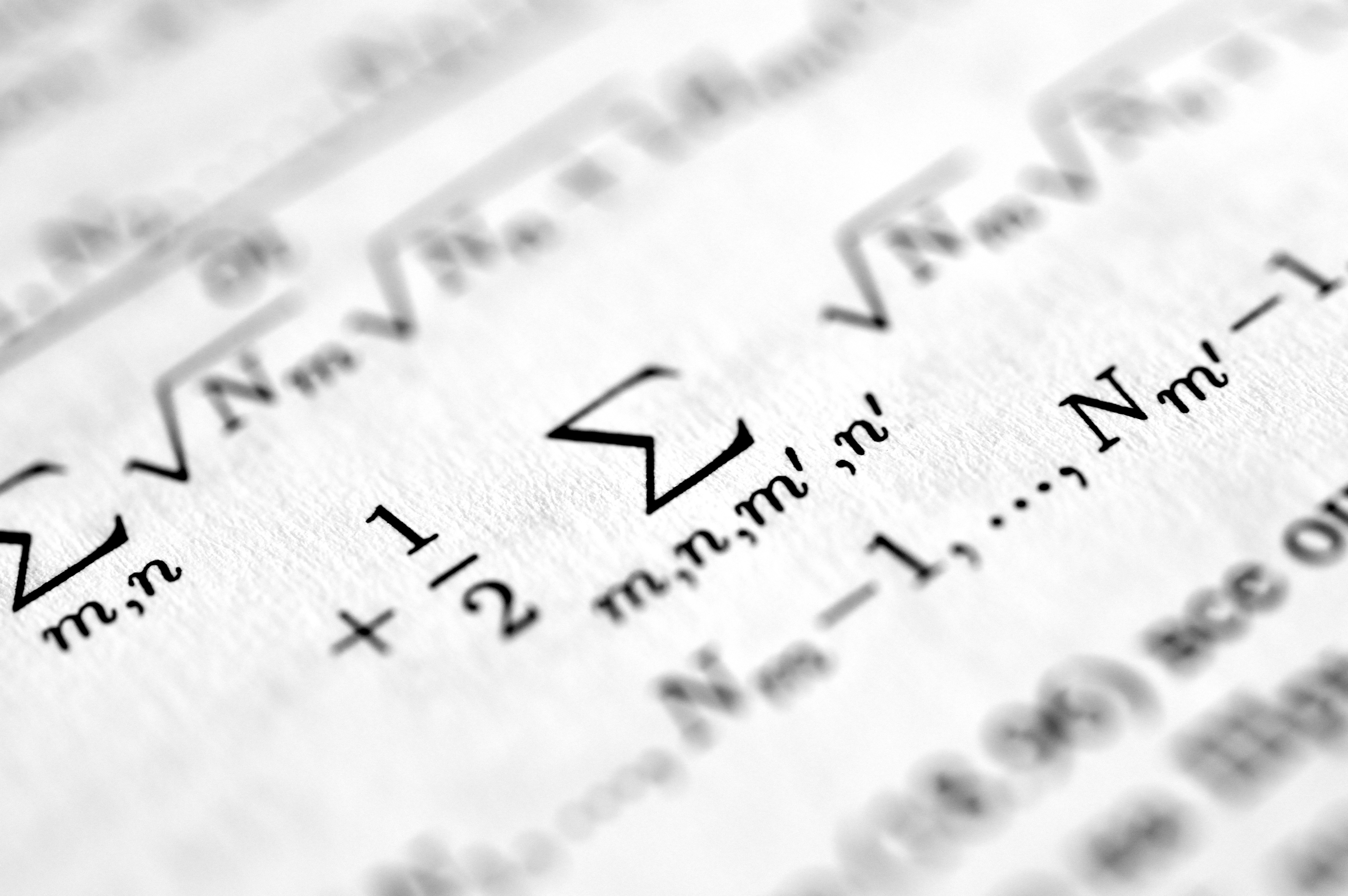
Descubre cómo las variables canónicas en el espacio métrico de Wasserstein mejoran la clasificación de distribuciones mediante la maximización de la razón de

Descubre cómo MIMONet utiliza operadores neuronales para monitorizar en tiempo real zonas inaccesibles en sistemas energéticos, con errores menores al 5% y

Descubre Latent-CFM, un modelo que usa variables latentes para un flujo eficiente en generación de imágenes. Mayor calidad, menos entrenamiento y recursos.

Descubre cómo el transporte óptimo revoluciona el machine learning: desde distancias de Wasserstein hasta modelos generativos. Una guía completa para

Descubre cómo la reducción de tokens va más allá de la eficiencia en IA generativa: mejora integración multimodal, reduce alucinaciones y optimiza rendimiento.

Descubre cómo las redes LSTM muestran múltiples ciclos de rendimiento tras el sobreentrenamiento, vinculados a transiciones entre orden y caos. El punto óptimo

Descubre cómo los modelos neuroinspirados de visión-lenguaje reducen un 24% los ataques de inferencia de membresía sin comprometer su utilidad. ¡Lee más!

Akasha 2: arquitectura IA con espacio de estado Hamiltoniano para predicción de video ultrarrápida y coherencia espacio-temporal.

UniT permite a modelos unificados razonar, verificar y refinar en múltiples rondas, mejorando tareas complejas de composición visual y comprensión.
MAND: detección de novedades multimodal en actividades egocéntricas. Mejora precisión usando RGB e IMU con puntuaciones adaptativas.

Descubre MuVAP, el modelo que predice quién hablará usando solo audio y una cámara. Ideal para robots sociales. Más preciso que los modelos actuales.

Aprende cómo MatchLM2Lite identifica contenido reproducido en tiempo real con destilación MLLM. Reduce vistas duplicadas un 2.5% sin afectar engagement.
NeurMLLM unifica acústica y texto con LLM multimodales para detectar Alzheimer y Parkinson. Resultados superiores en clasificación de etapas.

Descubre cómo la difusión discreta reduce un 26.9% el cómputo en razonamiento visual-textual y la recompensa factorizada mejora un 11.2% el rendimiento.

Descubre un nuevo método de segmentación de imágenes basado en votación de máscaras geodésicas que supera las limitaciones de inicialización y logra precisión