Variables Canónicas en el Espacio Métrico de Wasserstein
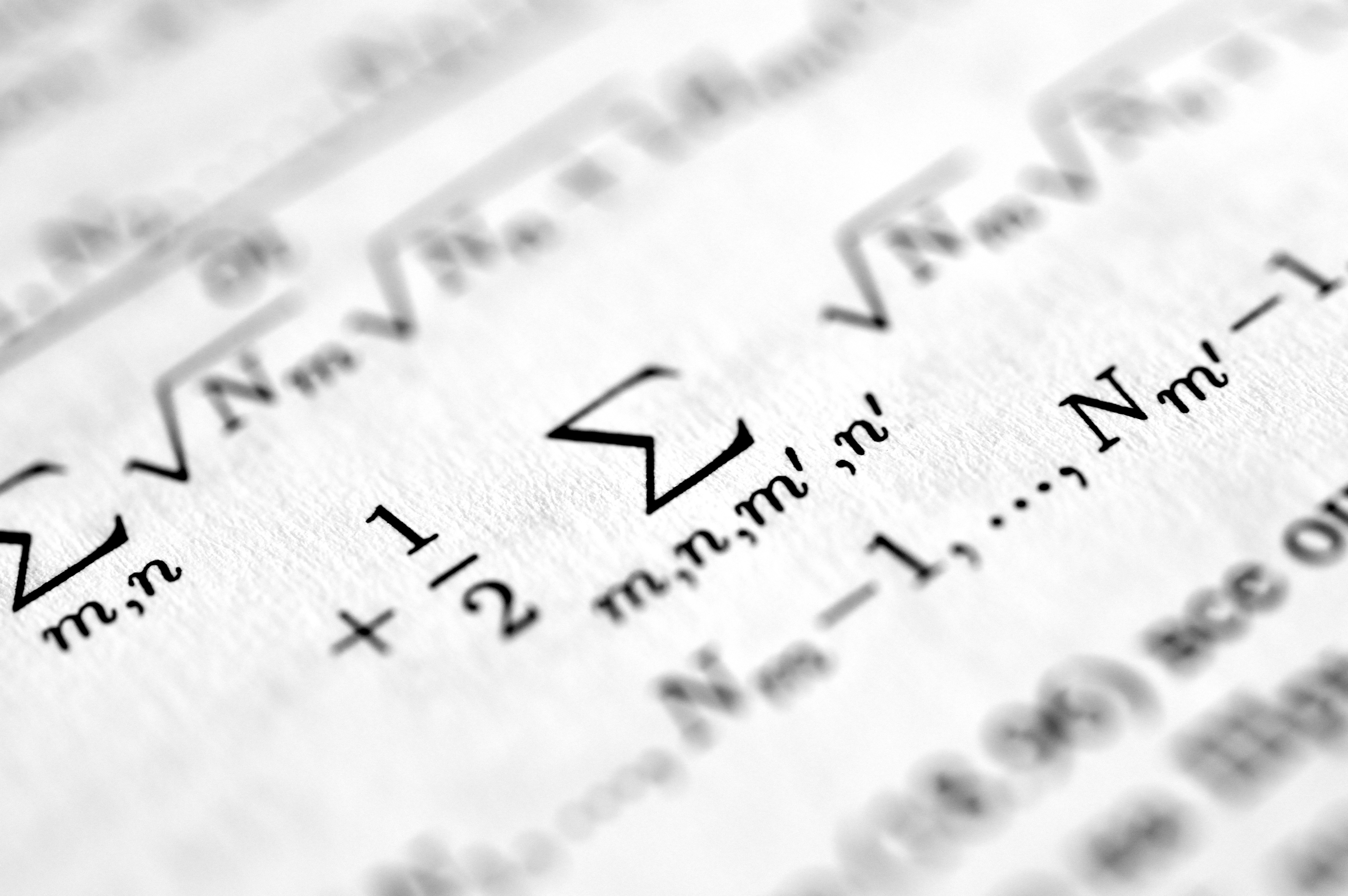
En el ámbito del aprendizaje automático y la minería de datos, una de las fronteras más desafiantes es la clasificación de instancias que no pueden representarse como puntos en un espacio vectorial tradicional, sino como distribuciones de probabilidad. Esta situación es habitual en áreas como el análisis de imágenes hiperespectrales, la bioinformática o la segmentación de clientes basada en patrones de comportamiento. Para abordarla, la distancia de Wasserstein se ha consolidado como una métrica robusta que captura la geometría subyacente entre distribuciones, permitiendo comparar de forma significativa conjuntos de datos complejos. Sin embargo, trabajar directamente en el espacio métrico de Wasserstein puede resultar computacionalmente costoso y propenso a la maldición de la dimensionalidad. Es aquí donde las variables canónicas —o coordenadas discriminantes— ofrecen una solución elegante: encontrar proyecciones que maximicen la separación entre clases mientras minimizan la variabilidad interna. Este principio, inspirado en el análisis discriminante de Fisher, se adapta al contexto de distribuciones mediante un proceso iterativo que combina transporte óptimo y optimización en el espacio vectorial. El resultado es una reducción de dimensionalidad que no solo acelera los algoritmos de clasificación, sino que mejora significativamente su precisión, como han demostrado estudios empíricos recientes. La implementación práctica de estas técnicas, sin embargo, exige infraestructura tecnológica sólida y experiencia en inteligencia artificial. En Q2BSTUDIO ofrecemos soluciones de IA para empresas que integran modelos avanzados de clasificación sobre datos distribuidos, ya sea en entornos cloud o on-premise. Nuestro equipo de desarrollo crea aplicaciones a medida y software a medida que incorporan algoritmos de última generación, como los basados en métricas de Wasserstein, y los despliega sobre servicios cloud AWS y Azure para garantizar escalabilidad y rendimiento. Además, combinamos estas capacidades con servicios inteligencia de negocio y Power BI para visualizar los resultados de clasificación en dashboards interactivos, facilitando la toma de decisiones. También abordamos la ciberseguridad de los datos y modelos, protegiendo la información sensible en cada etapa del pipeline. La integración de agentes IA permite automatizar procesos de análisis continuo, mientras que nuestras soluciones de inteligencia artificial se adaptan a sectores tan diversos como la banca, la salud o la logística. Así, la teoría de variables canónicas en el espacio de Wasserstein deja de ser un concepto abstracto para convertirse en una herramienta práctica y diferenciadora dentro de una estrategia de datos bien diseñada.
Comentarios