
El último píxel visible: sondeando percepción fina en VLMs
Nuevo benchmark FineSightBench revela que la percepción fina en VLMs satura a 12px y el razonamiento visual es limitado.
Nuevo benchmark FineSightBench revela que la percepción fina en VLMs satura a 12px y el razonamiento visual es limitado.

Descubre cómo la coherencia tensa revela fallos inminentes en agentes de IA. Un detector con 94% de precisión identifica cuándo un agente ignora sus propias
ClinicalBr, el primer benchmark bilingüe para evaluar LLM clínicos en portugués. Analizamos la brecha entre inglés y portugués en diagnóstico y tratamiento.
¿Qué tan pequeño puede percibir un VLM? FineSightBench revela que la percepción se satura a 12px, pero el razonamiento sigue limitado.

Descubre cómo un análisis masivo de 2,084 papers revela las ilusiones del estándar de oro en evaluación humana de texto generado.
¿Los resúmenes de IA son mejores que los humanos? Un estudio revela que los humanos aún ganan en fidelidad y veracidad. Descubre por qué el resumen no ha

¿Qué tan robustos son los VLMs ante problemas STEM en varios idiomas? Sci-Rho te lo muestra con un benchmark simbólico multilingüe y visual.

Descubre cómo el bucle hacker-fixer protege benchmarks de agentes contra reward hacking, eliminando el 100% de exploits en KernelBench. Una solución
ATM te permite diagnosticar y mejorar modelos del mundo latente con una matriz de transferencia que acelera la evaluación más de 100x, sin necesidad de

Descubre cómo SEF-CLGC combina notación lógica y SLMs para evaluar razonamiento en IA, reduciendo sesgo y logrando 27.80% de contenido.

La traducción directa subestima riesgos en LLMs. Este análisis en 4 idiomas asiáticos muestra cómo el red-teaming culturalmente adaptado revela amenazas reales.
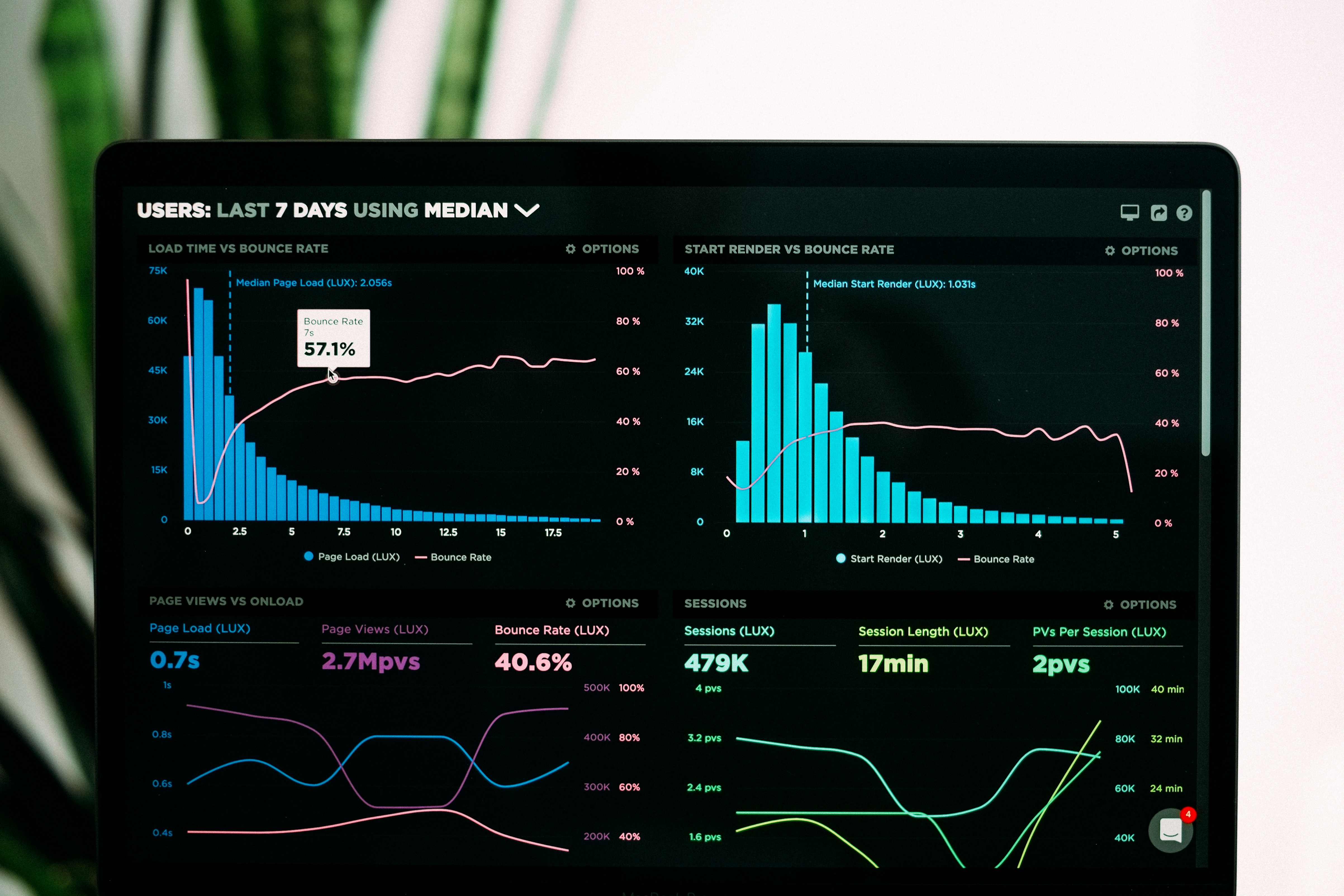
Metric Match: método de selección de subconjuntos que reduce un 32.5% las anotaciones humanas al evaluar fiabilidad de jueces LLM. Ahorra miles en casos

Descubre OSGuard, el benchmark que evalúa la seguridad de agentes de IA en tareas de computación, detectando acciones inseguras incluso si cumplen el objetivo.
Metric Match reduce un 32% las anotaciones humanas para evaluar fiabilidad de jueces LLM, mejorando precisión y ahorrando costos.

Descubre OSGuard, el nuevo benchmark que evalúa la seguridad de los agentes de IA en tareas informáticas. ¿Logran evitar atajos inseguros? Lee más.

Aprende cómo los agentes LLM con conciencia de riesgo recuperan datos geoespaciales y se defienden de ataques adversariales.

Agentes LLM conscientes del riesgo recuperan datos geoespaciales usando consultas en lenguaje natural. Evaluación adversarial.

Descubre IRTS-ToolBench: 1700 preguntas para evaluar LLMs en series temporales irregulares. Razonamiento con herramientas para ciencia de datos agentica.

Descubre Mask-Proof, un pipeline que evalúa el razonamiento paso a paso en pruebas matemáticas con LLM. Incluye 292 problemas para benchmarking.
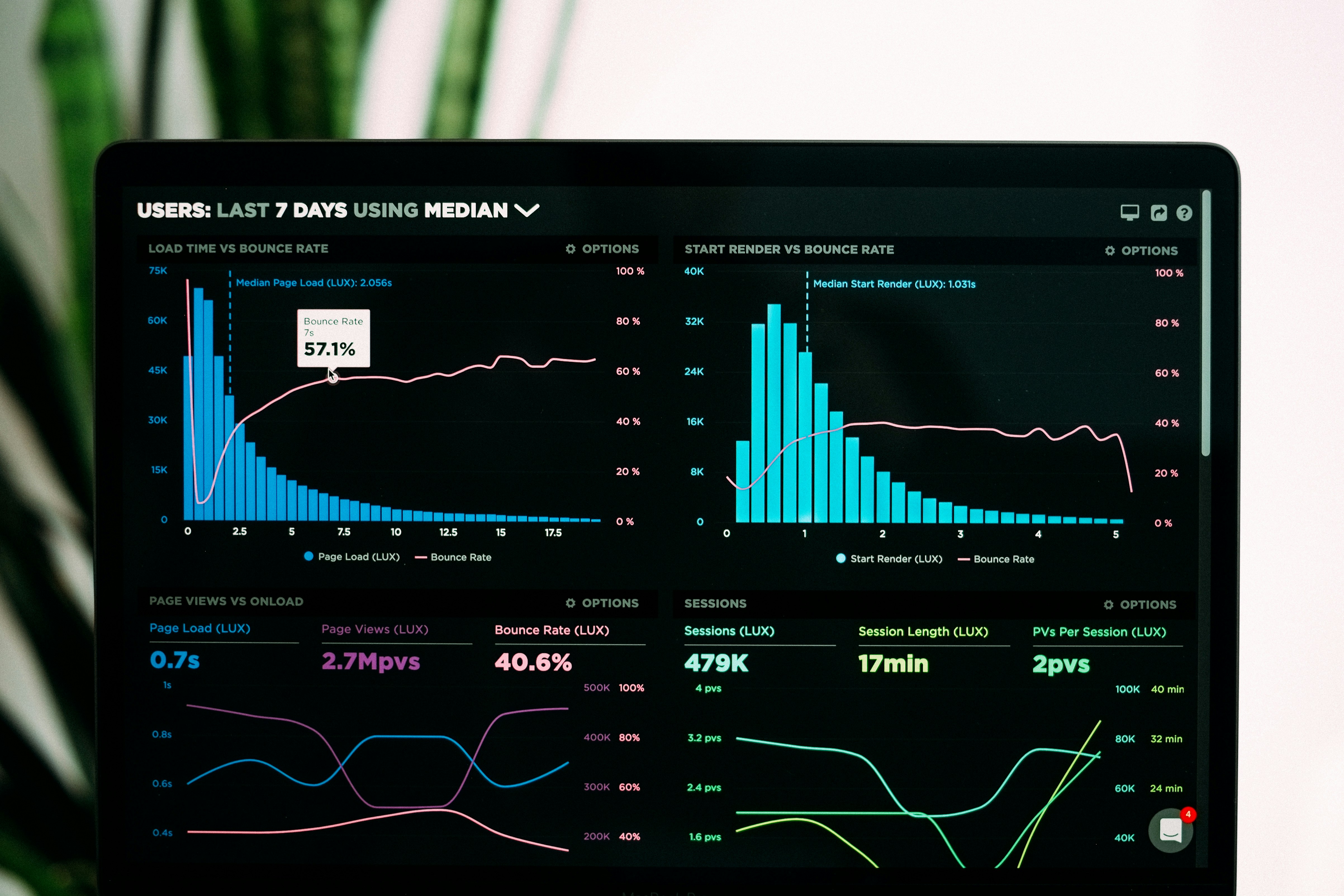
Evalúa agentes de código con CODA-BENCH: 1009 tareas en entornos de datos masivos. Solo el 61% de éxito actual. Descubre las brechas en inteligencia artificial.