
¿Quién derivó: el sistema o el juez? Atribución válida en evaluación de LLM
Descubre cómo distinguir si la deriva en las evaluaciones de LLM se debe al sistema o al juez automático con un método de atribución válido en todo momento.
Descubre cómo distinguir si la deriva en las evaluaciones de LLM se debe al sistema o al juez automático con un método de atribución válido en todo momento.
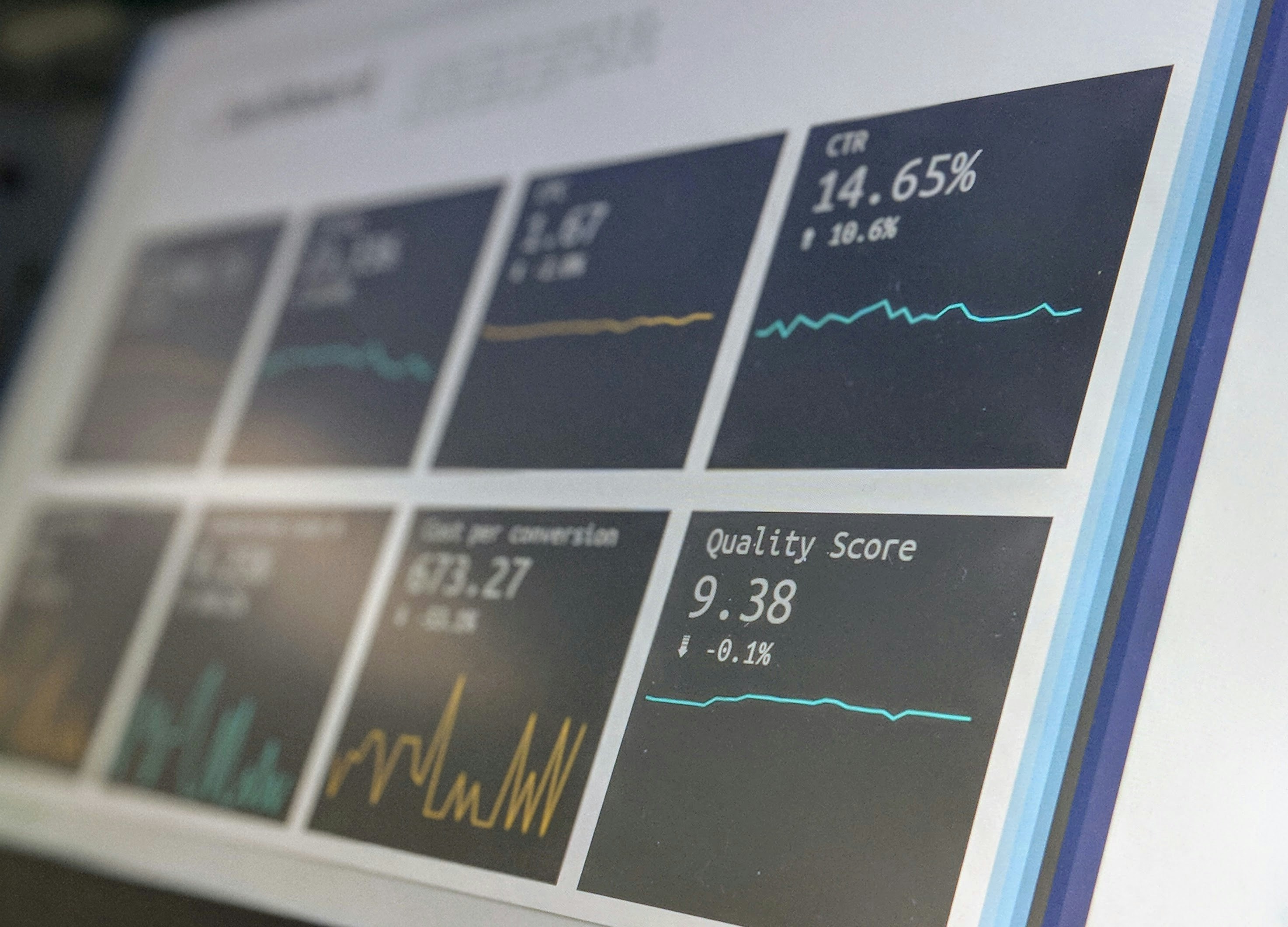
Evaluación de procesos con seguimiento semántico revela diferencias ocultas entre agentes web. Aprende a mejorar su rendimiento.

¿Los LLM identifican unidades de información en afasia? Con pocos ejemplos logran alta efectividad pero requieren supervisión. Ideal para evaluación asistida.

El noveno informe del Índice de IA revela una brecha crítica: ¿estamos preparados? Nuevos capítulos en ciencia, medicina, economía y trabajo.

Los benchmarks asumen que los estudiantes seguirán el andamiaje, pero en la práctica lo evaden. Descubre el desajuste entre teoría y realidad en tutores de IA.
¿Buscas orientación profesional? Un sistema con redes neuronales predice tu mejor carrera en IT basado en tu rendimiento.

Descubre cómo RetailBench pone a prueba la toma de decisiones de agentes LLM en supermercados simulados durante 180 días.

UrbanWell: benchmark para evaluar modelos multimodales en análisis de bienestar urbano espacio-temporal. Descubre sus resultados y rendimiento.

Explora el estudio SciText2Eq: cómo los LLMs generan ecuaciones explicables desde textos científicos, los desafíos en semántica y la alineación con juicios

Mind-Studio crea modelos de mundo ejecutables de juegos, con 48.7% de precisión en predicción de estados, superando métodos anteriores. Perfecto para IA y

RecourseBench: marco modular y reproducible para evaluar recursos algorítmicos. Integra 28 métodos con tests automáticos. ¡Prueba su interfaz web!

TimeVista utiliza VLM como jueces para evaluar pronósticos de series temporales, logrando una alineación humana superior a métricas tradicionales.

¿Tu tutor de IA resuelve problemas pero no enseña? Descubre por qué el rendimiento en resolución no equivale a apoyo educativo y cómo medirlo.

CoffeeBench: ¿Pueden los agentes LLM gestionar una empresa de café por 90 días? Este benchmark revela diferencias clave entre modelos. ¡Descubre los resultados!

LabOSBench: un benchmark realista y de bajo costo para evaluar agentes multimodales en el control de instrumentos científicos. Ideal para IA y automatización
Combina clasificación multi-etiqueta e IA generativa para analizar comentarios de usuarios y obtener insights accionables para mejorar tu producto
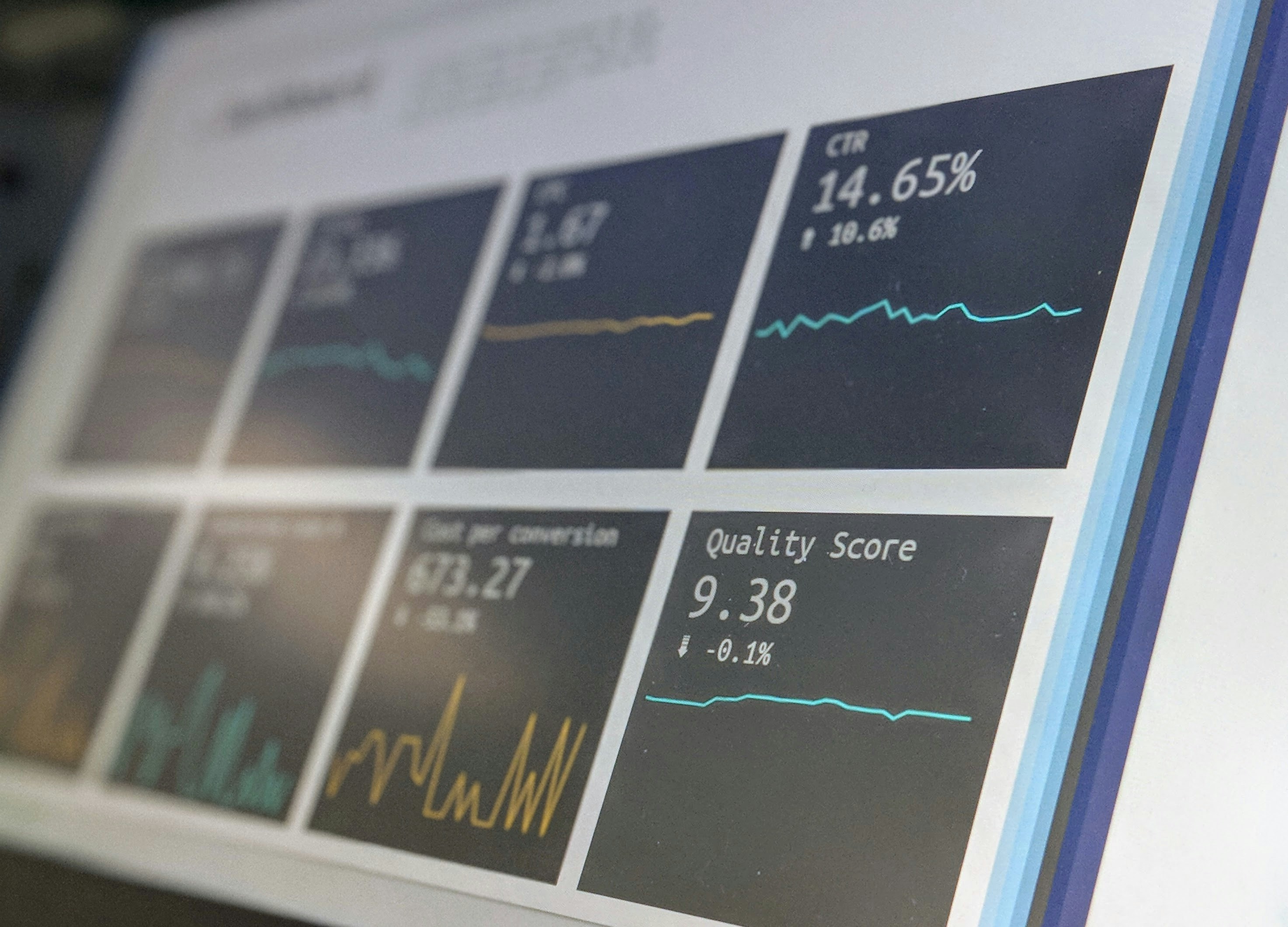
Los LLMs avanzados apenas mejoran la puntuación ESG frente a modelos más baratos. Un estudio muestra que el consenso de modelos ligeros es igual de efectivo.

Descubre MiroBench, un benchmark que evalúa si los agentes de IA replican fielmente las dinámicas de discusiones reales en Reddit. ¿Son realmente realistas?

MMLongEmbed: el primer benchmark para evaluar modelos de embeddings multimodales en escenarios de contexto largo. Descubre sus hallazgos clave.

Descubre cómo regulaciones ambientales redujeron el PM2.5 en Londres un 12.35% (1.88 μg/m³) según IA causal. Clave para políticas.