
Aprendizaje Variacional Global para Corrección de Errores Cuánticos
Aprendizaje variacional global para corrección de errores cuánticos: reduce 97% tiempo de entrenamiento, mejora 25% tasa de éxito y logra 100% de precisión.
Aprendizaje variacional global para corrección de errores cuánticos: reduce 97% tiempo de entrenamiento, mejora 25% tasa de éxito y logra 100% de precisión.

DCMDP reformula el RL para LLM corrigiendo la discrepancia train-inference. Mejora el rendimiento en modelos como Qwen-3 incluso con recursos limitados.

Descubre C³ache, un método sin entrenamiento que acelera hasta 2.5x los Modelos de Acción Mundial (WAM) mediante caché de inferencia cruzada, manteniendo la precisión.

Descubre cómo las redes neuronales organizan representaciones en aritmética modular, revelando una geometría cíclica que supera el colapso neuronal tradicional.

Descubre cómo PRISM elimina el sesgo oculto en los PRM, mejorando la precisión del razonamiento y reduciendo falsos positivos en un 22%.

El nuevo enfoque Thinking-RFT supera atajos en ToM: mejora un 6% frente a SFT mediante razonamiento y refuerzo.

Descubre Claw-R1, el middleware que transforma las interacciones agente-entorno en datos gestionables para mejorar el RL agentivo. Optimiza el entrenamiento de LLMs con datos paso a paso.
Nuevo método KAT detecta trampas de acuerdo KL en destilación on-policy, mejorando precisión 2.66% y reduciendo tiempo de entrenamiento 59.73%.

Descubre cómo la descomposición bulk-boundary revela dinámica intrínseca y estocástica de redes neuronales, con ecuación de continuidad de energía.

Descubre cómo el autoaprendizaje de LLM es en realidad un imitador adversarial. Un nuevo algoritmo mejora la estabilidad y el rendimiento del ajuste fino sin datos de preferencia.

FIM-ODE predice campos vectoriales de EDOs con una pasada. Ofrece rendimiento cero-disparo y supera métodos tradicionales sin experticia en ML.

La Hipótesis de Alineación Superficial cuantificada: el post-entrenamiento colapsa la complejidad de tareas en LLMs. Resultados sorprendentes en razonamiento y traducción.
Descubre RLVE: una técnica que escala el aprendizaje por refuerzo para LLMs con entornos adaptativos, logrando un 3.37% de mejora en razonamiento con menos cómputo.

Descubre cómo MPC-Flow resuelve problemas inversos con modelos generativos de flujo sin entrenamiento, aplicable a restauración de imágenes como in-painting y super-resolución.

Acelera el entrenamiento de LLMs con paralelismo de contexto flexible. Logra hasta 2.24x de velocidad incluso con datos heterogéneos.

Descubre cómo combinar datos sintéticos con solo un 20% de datos reales iguala y mejora la detección de grietas en mampostería con CNN. ¡Resultados sorprendentes!
Mejora la segmentación y profundidad con marginalización de fase en Vision Transformers. Sin entrenamiento, más precisión.
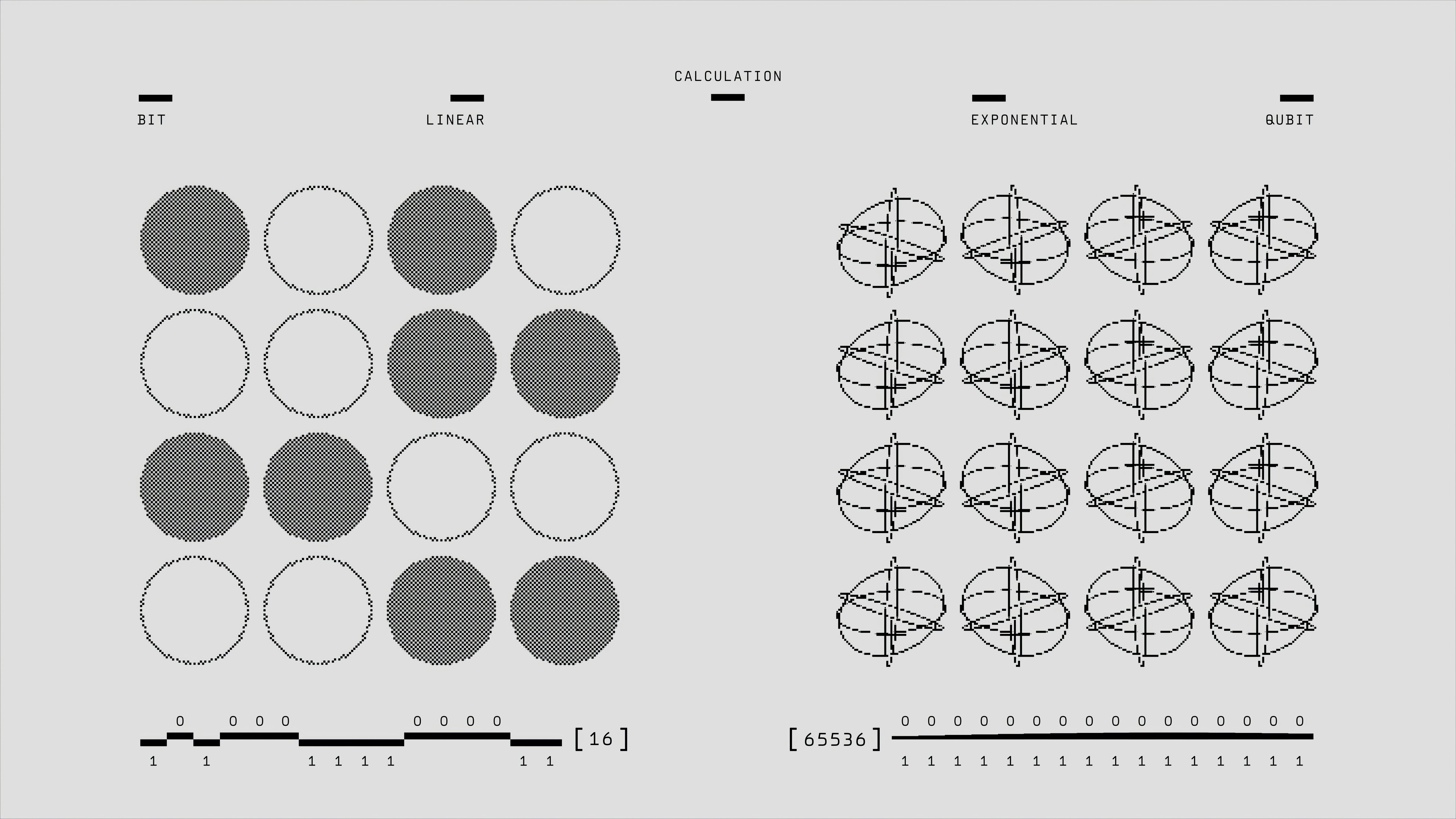
SAEExplainer optimiza la interpretación de características SAE usando preferencias guiadas por activación, reduciendo alucinaciones y mejorando causalidad.

SG-OPD introduce un verificador binario para mejorar la destilación on-policy, superando a métodos anteriores en problemas de razonamiento matemático.
Descubre por qué el simple intervalo ConformalNaive, sin entrenamiento, supera a métodos complejos en pronósticos de series temporales probabilísticas.