
Funciones de Confianza: Generalización Débil a Fuerte sin Pérdidas
Aprende cómo las funciones de confianza filtran etiquetas débiles para lograr generalización casi sin pérdidas. Mejora tu IA.
Aprende cómo las funciones de confianza filtran etiquetas débiles para lograr generalización casi sin pérdidas. Mejora tu IA.

TrOPD estabiliza la destilación on-policy de LLMs usando regiones de confianza, superando la divergencia profesor-alumno. Mejora razonamiento, código y benchmarks.
TrOPD estabiliza la destilación on-policy en LLMs con regiones de confianza. Supera a OPD, EOPD y REOPOLD en razonamiento y código. ¡Descubre cómo!
Descubre FSA: método que transforma características en dinámicas para predecir series temporales nunca vistas, superando a Transformers con menos datos.

GPTQ-intrinsic LoRA: mejora la cuantización de baja precisión con corrección de bajo rango. Algoritmo casi óptimo para modelos grandes.

GPTQ-intrinsic LoRA combina cuantización de baja precisión y adaptación de bajo rango para comprimir redes neuronales. Algoritmo sin entrenamiento mejora modelos como Qwen3 y DeiT.

Descubre OmniOPD: destilación on-policy sin logits que mejora matemáticas +28% y supera a modelos propietarios.

Descubre CRePE, método de poda post-entrenamiento para LLMs que reduce costos sin perder precisión, y PHO que acelera la búsqueda de hiperparámetros.
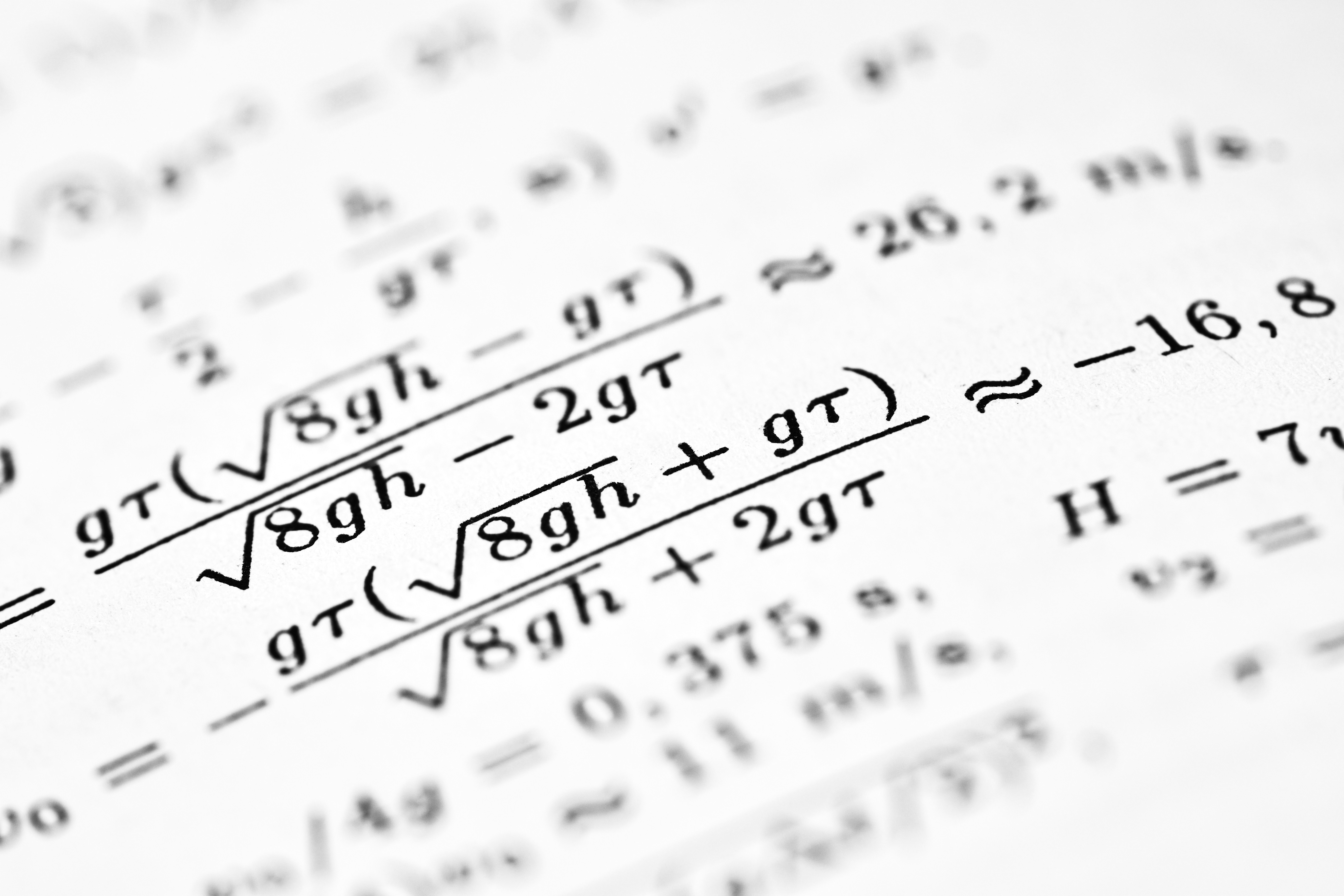
Descubre el marco teórico para algoritmos de auto-play que logran crecimiento exponencial de teoremas probados, con mejora de diversidad usando similitud de difusión.

SceneSmith: genera escenas interiores realistas con IA para simulación robótica. Hasta 6x más objetos, <2% colisiones, 96% estables.

Descubre cómo usar aprendizaje por refuerzo para aprender tokenización end-to-end, mejorando el rendimiento de modelos de lenguaje a gran escala.
Descubre cómo los picos masivos en LLMs son vectores de sesgo y cómo la cuantización sin picos revoluciona la eficiencia de los modelos de IA. ¡Optimiza tu AI!

Descubre cómo la teoría de perturbación local explica la interferencia entre dominios en RL multi-dominio y cómo un breve refresco recupera el rendimiento sin dañar otros.

LookWise mejora el razonamiento visual detallado en modelos multimodales sin entrenamiento, logrando 4x más velocidad y mayor precisión en benchmarks. ¡Descúbrelo!

Edición perceptual de bajo nivel en difusión incondicional. Mejora imágenes sin reentrenar con parcheo de cuello de botella y guía libre de clasificador.
Aprende a entrenar modelos de difusión descentralizados con objetivos heterogéneos, reduciendo 16x cómputo y 14x datos con una sola GPU. ¡Acelera tu IA!

La cuantización agresiva reduce la precisión y alarga el razonamiento de los modelos de IA. Descubre cómo una penalización simple en tokens de 'overthinking' mejora la eficiencia.

Descubre cómo el fenómeno Grokking aparece en el preentrenamiento de LLMs, revelando una generalización gramatical retardada. Análisis de conceptos y atención en cabezas.

Políticas de orden adaptativo mejoran generación de secuencias en difusión enmascarada, superando heurísticas en tareas sensibles al orden como proteínas.

Descubre cómo equilibrar las tasas de aprendizaje entre capas en redes lineales mejora el rendimiento temprano. Resultados teóricos y experimentales.