
Una Dieta Mixta Hace de DINO un Codificador Visual Omnívoro
Descubre cómo el nuevo codificador omnívoro alinea características entre RGB, profundidad y segmentación para una visión robusta y coherente.
Descubre cómo el nuevo codificador omnívoro alinea características entre RGB, profundidad y segmentación para una visión robusta y coherente.
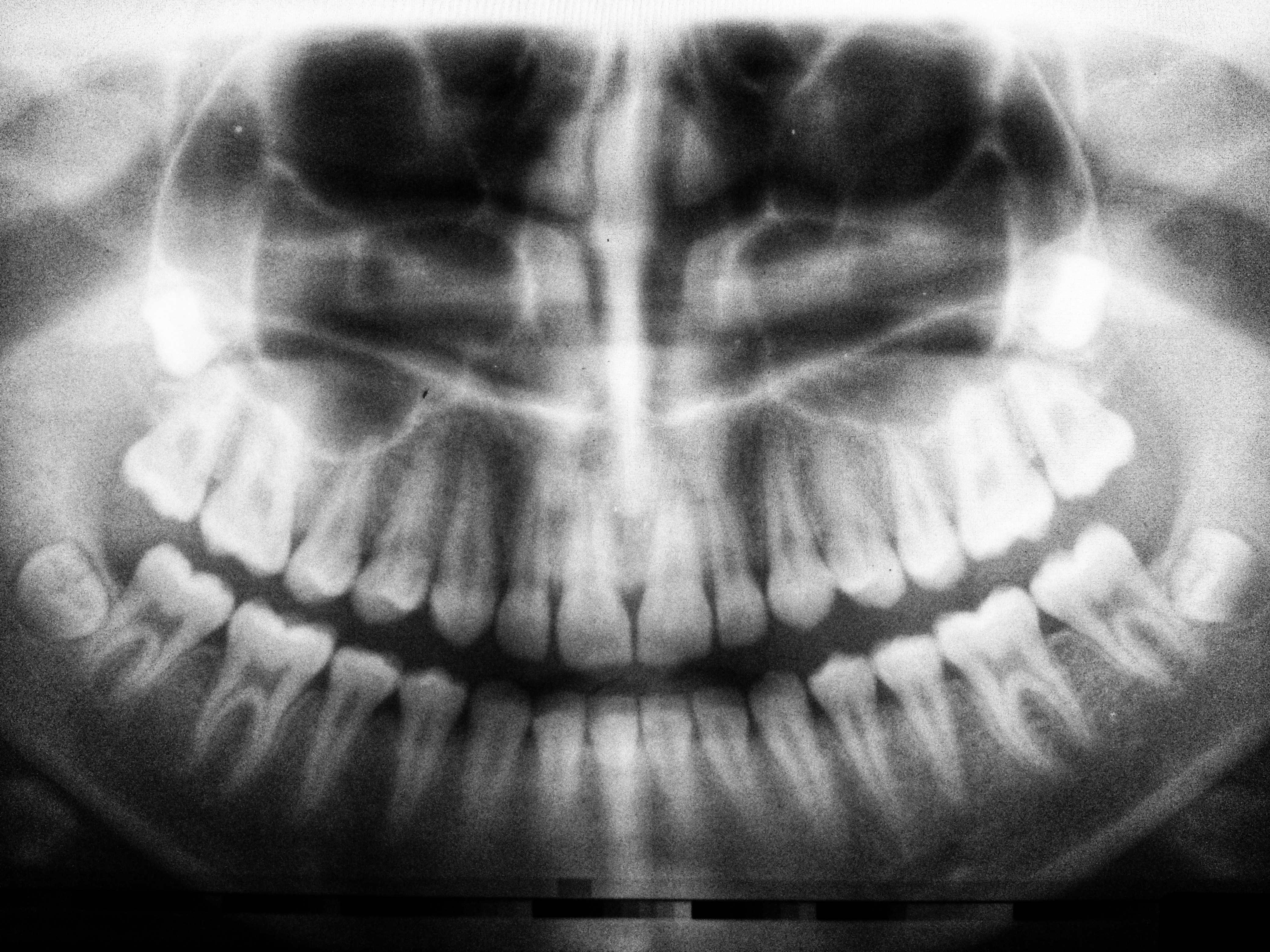
Descubre cómo adaptar modelos DINO de visión autosupervisada para detectar osteoartritis de la ATM en CBCT con alta precisión, incluso con pocos datos.

Nuevo estudio revela un espacio geométrico que alinea Transformers con redes cerebrales humanas. Descubre hallazgos sorprendentes como DINOv2 y escala inversa en DeiT.

Un nuevo modelo de IA con atención factorizada por partes alcanza un 70% de precisión de apuntado, casi igualando a la supervisión completa. Mejora la interpretabilidad en visión por computadora.
Descubre DINOSAUR: mejora la recuperación al incorporar incertidumbre en embeddings, logrando mayor cobertura sin perder recall.

El model stitching ya no es solo un diagnóstico: descubre cómo unir modelos de visión heterogéneos para mejorar precisión y eficiencia en LLMs multimodales.
FlatVPR corrige la curvatura de manifolds en modelos fundacionales, permitiendo reconstrucción lineal precisa con pocos anclajes. Mejora el VPR incluso con cambios estacionales extremos.