
Escalando datasets multi-sensor, multi-agente, multi-dominio sistemas autónomos
Escala datasets multi-sensor, multi-agente, multi-dominio para sistemas autónomos pipeline modular genera terabytes de datos etiquetados usando CARLA y AVstack.
Escala datasets multi-sensor, multi-agente, multi-dominio para sistemas autónomos pipeline modular genera terabytes de datos etiquetados usando CARLA y AVstack.

Genera datasets etiquetados a escala para entrenar sistemas autónomos multisensor y multiagente con CARLA y AVstack.

Descubre cómo generar datasets de sonidos de motor con anotaciones precisas. Ideal para entrenar modelos de IA en diseño de sonido automotriz.

StandardE2E unifica múltiples datasets E2E, facilitando preprocesamiento y entrenamiento cross-dataset. ¡Optimiza tu investigación!

Explora RIDE, el dataset abierto para predicción de retrasos ferroviarios. Compara redes neuronales, estadísticos y más. ¡Optimiza tus modelos!

Descubre MemoryDocDataSet: un benchmark que desafía a la IA a combinar memoria conversacional y razonamiento en documentos largos. ¿Tu modelo supera la brecha?

Descubre cómo VISTA combina visión y validación física para adaptar datos UMI y entrenar modelos VLA, mejorando el rendimiento en manipulación robótica real.

Nuevo benchmark EgoProactive y arquitectura desacoplada para asistencia proactiva. La IA guía en tiempo real y corrige desviaciones en tareas procedurales.

Descubre DeliChess, un dataset innovador de diálogos grupales para resolver puzzles de ajedrez. Mejora la precisión mediante deliberación colaborativa.

Descubre el dataset DeepSpeak-Agentic: 37 horas de conversaciones humano-IA para identificar agentes mediante audio, video y texto.
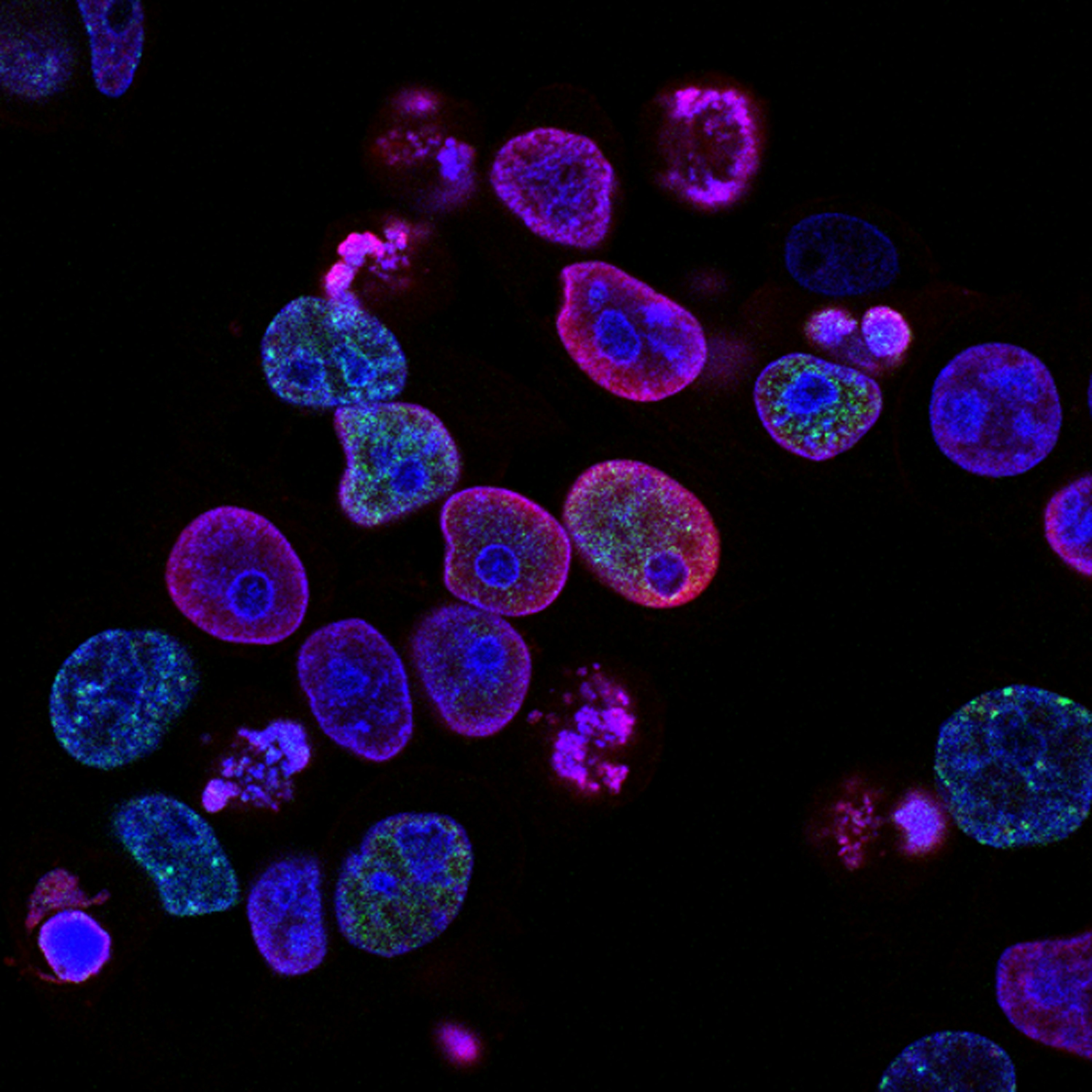
scTranslation: benchmark integral para traducción multiómica unicelular. Evalúa modelos con datasets y métricas, analizando selección de características y pocos ejemplos. ¡Descubre insights clave!
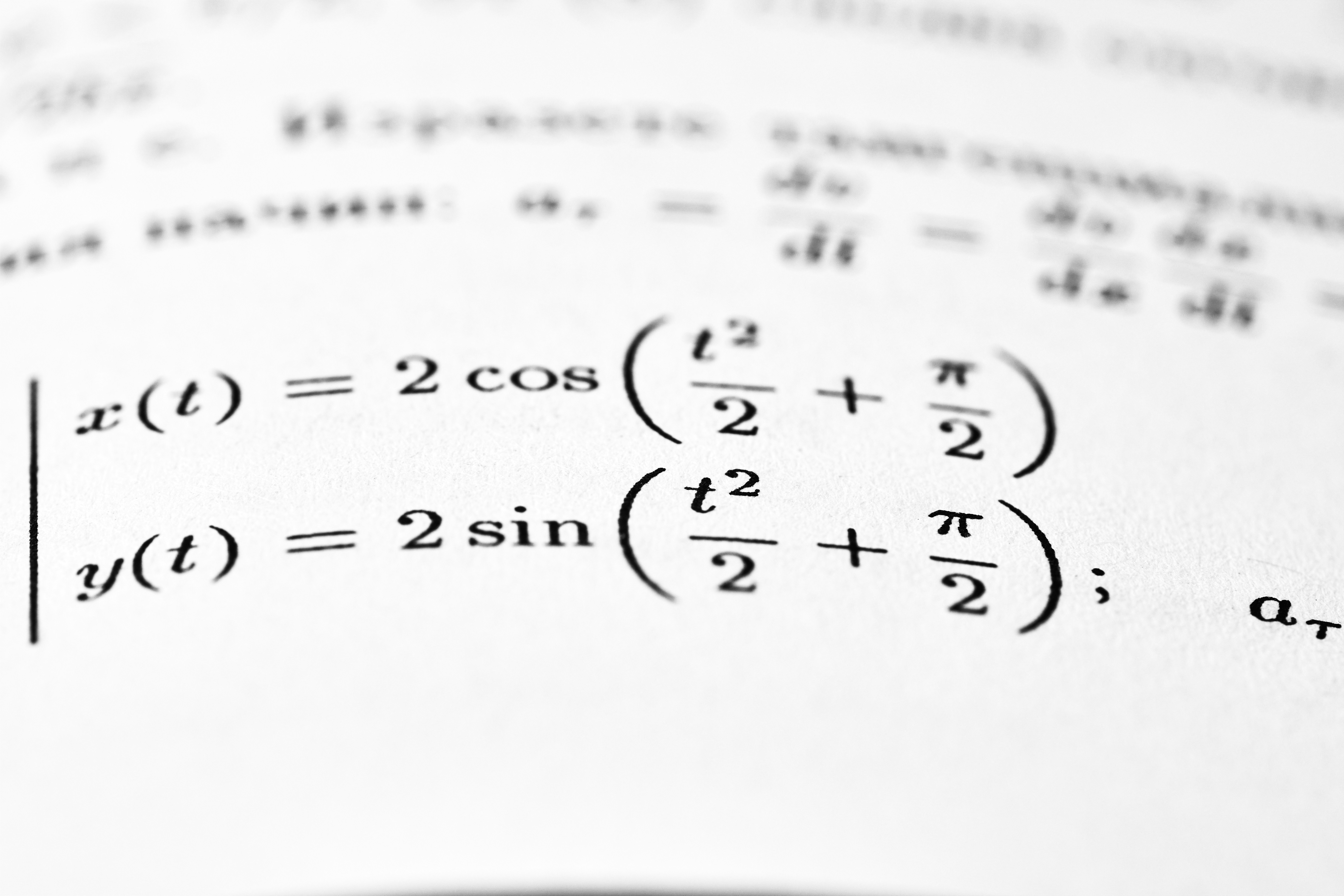
Descubre Lean-GAP: 430 problemas de álgebra formalizados en Lean 4. Pipeline automatizado con verificación humana. Desafíos y metodología.

Descubre SPADE, el nuevo método que combina bocetos y difusión para planificar rutas de robots móviles con un 39% menos de error y un 93% menos parámetros.

Descubre CoMPAS3D, el dataset de captura de movimiento de salsa que permite evaluar robots humanoides en interacciones sociales con métricas objetivas.

Dataset RESCAST-100K: 100,000 hogares simulados para predicción de carga y temperatura. Ideal para transferencia de aprendizaje y adaptación de dominio.

Descubre cómo el speedrun de nanoTabPFN logró un speedup de 81x en preentrenamiento de modelos tabulares. Participa y contribuye al benchmark abierto en GitHub.

Descubre cómo medir la equidad en deep reinforcement learning para descubrimiento de fármacos en salud, evaluando sesgos en datos, recompensas y diversidad química.

Descubre KITScenes, el dataset europeo con sensores de alta fidelidad y mapas HD completos para conducción autónoma. Incluye benchmarks para mapas, profundidad,

Descubre FRED: el primer dataset multimodal para vehículos autónomos en carreteras inundadas, con datos de cámara, LiDAR e IMU para detectar riesgos acuáticos.

Conoce AVTrack, el dataset que desafía los métodos actuales de seguimiento audiovisual en escenas humanas complejas con oclusiones y movimiento.