
AdaGrad++ y Adam++: métodos adaptativos simples sin parámetros
Descubre AdaGrad++ y Adam++: algoritmos adaptativos sin parámetros que ofrecen convergencia garantizada. Optimiza deep learning sin ajustes manuales.
Descubre AdaGrad++ y Adam++: algoritmos adaptativos sin parámetros que ofrecen convergencia garantizada. Optimiza deep learning sin ajustes manuales.

Nuevo análisis muestra que el sensado adaptativo comprimido alcanza convergencia global con solo dos medidas por iteración, revelando límites insuperables frente a métodos no adaptativos.
Descubre RefLoRA, una nueva técnica de fine-tuning que acelera la convergencia y mejora el rendimiento de modelos grandes con mínimo costo computacional.

Descubre cómo el enfoque Multigrade Deep Learning permite entrenar redes profundas por grados, reduciendo errores residuales y garantizando convergencia uniforme en arquitecturas ReLU.

El entrenamiento de LLMs converge lentamente por una razón fundamental: softmax y entropía cruzada generan un escalado de pérdida universal 1/3. Descubre las implicaciones.

Aprende cómo la distribución de fuente condicional optimizada en Flow Matching acelera la convergencia hasta 3x y mejora la calidad en generación texto-imagen.

Certificación no vacía de MCMC de transporte: nuevos límites de brecha espectral con flujos normalizadores. Ideal para muestreo bayesiano.
Descubre cómo VRPO mejora el alineamiento de representaciones en difusores mediante optimización por refuerzo, logrando +1.8 FID y 2.3x más rápido que REPA.

Descubre LiMuon, el optimizador ligero y rápido que reduce memoria y complejidad muestral para entrenar modelos grandes. ¡Mejor rendimiento!

Descubre cómo el aprendizaje multigrid jerárquico acelera simulaciones CFD de aeronaves 3D, reduciendo costos computacionales sin perder precisión.

Descubre un marco teórico que unifica los algoritmos de agregación de gradientes para optimización multiobjetivo, con nuevas garantías de convergencia y aplicac

Descubre cómo los métodos de gradiente logran convergencia lineal en mezclas gaussianas sobreparametrizadas, superando la lentitud tradicional. Leer más.
Descubre cómo la identificación del mejor brazo (BAI) mejora la optimización bayesiana en funciones multimodales, acelerando la convergencia al óptimo global.

Descubre cómo se demuestra la convergencia de algoritmos bi-escala bajo ruido markoviano, un avance clave para el aprendizaje por refuerzo off-policy.
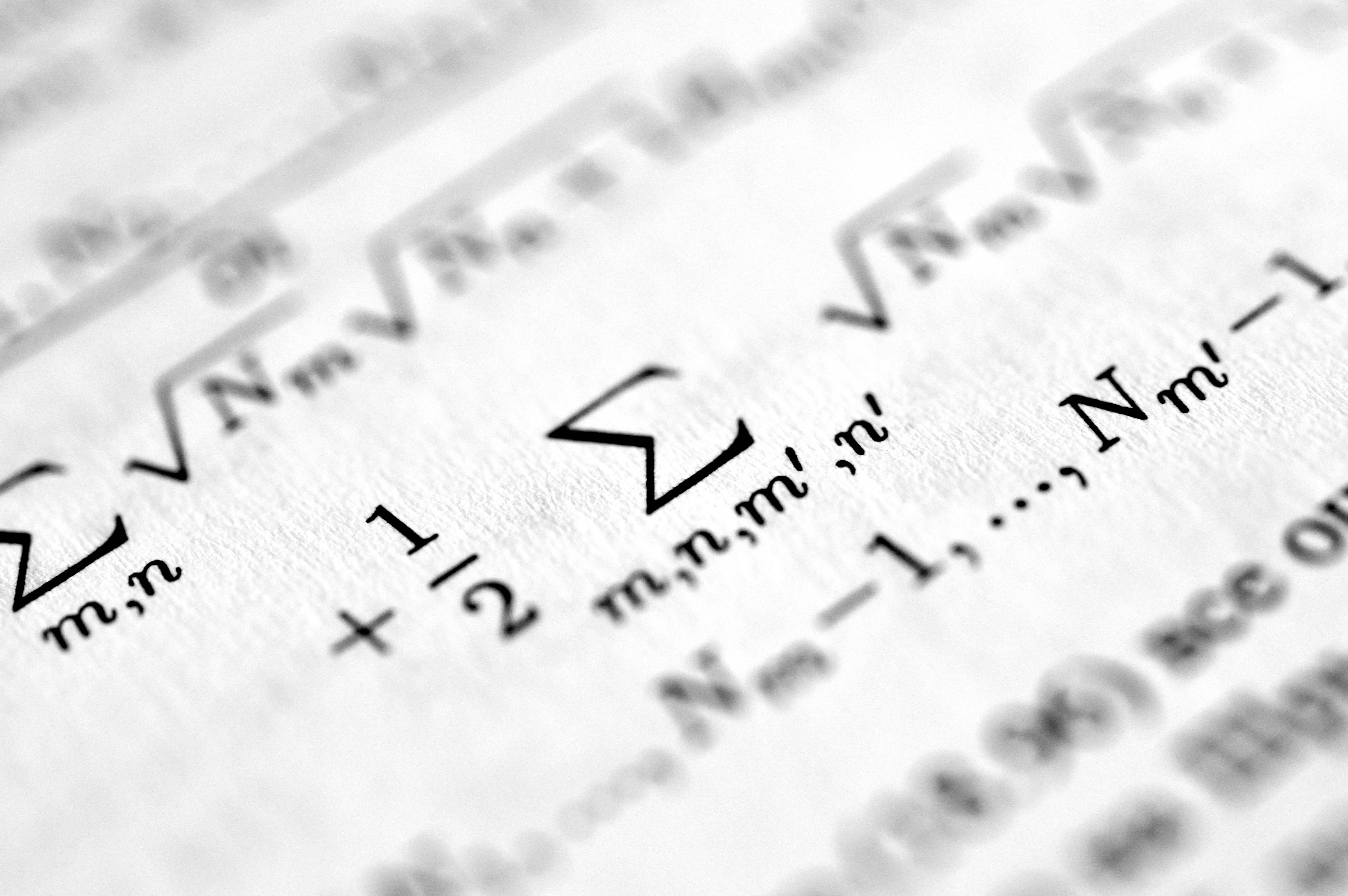
Descubre cómo el marco de Lyapunov permite analizar la convergencia en tiempo finito de algoritmos estocásticos como Q-learning y SGD. Ideal para IA y RL.
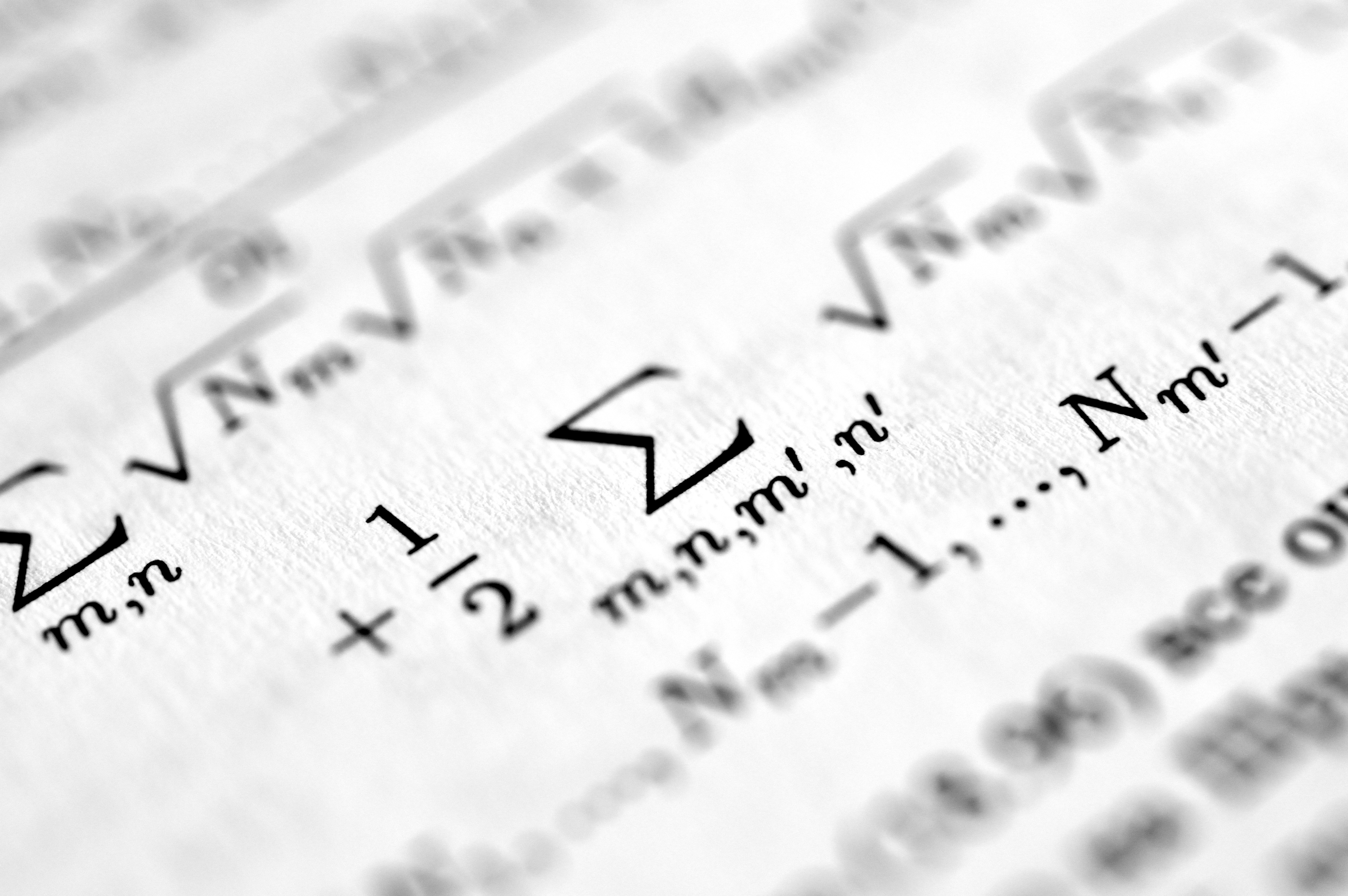
Descubre cómo las funciones de Lyapunov permiten analizar la convergencia finita de algoritmos estocásticos en aprendizaje automático y refuerzo.

Descubre cómo el nuevo marco MORL con criterio max-min logra equidad y cumple restricciones en control térmico, locomoción y tráfico. ¡Optimiza decisiones multiobjetivo!
Acelera tu fine-tuning con BaLoRA: elimina invariancia de parámetros para convergencia más rápida y mejor rendimiento.
Aprende cómo los algoritmos de error feedback logran convergencia óptima en optimización distribuida con compresión de gradientes. Análisis para EF y EF21.

La CES logra convergencia global en optimización estocástica mediante límites de campo medio y concentración semiclásica, superando colapsos de varianza.