Optimización de políticas con recompensas híbridas eficientes en energía
Descubre cómo H-EARS mejora eficiencia energética y estabilidad en RL con recompensas híbridas guiadas por física. Resultados en benchmarks y simulaciones.
Descubre cómo H-EARS mejora eficiencia energética y estabilidad en RL con recompensas híbridas guiadas por física. Resultados en benchmarks y simulaciones.
Descubre cómo una regularización débil mejora el entrenamiento de Wasserstein GANs, superando problemas de convergencia y optimizando la restricción Lipschitz.

Cómo los gradientes estocásticos convergen con parámetros nuisance. Ortogonalidad de Neyman y actualizaciones ortogonalizadas para optimización robusta.
Descubre cómo el método SLSE-FRS combina Sketch-and-Solve e Iterative-Sketching para obtener estimadores de alta precisión en modelos lineales a gran escala.
Descubre cómo los métodos aleatorios de factibilidad con pasos adaptativos resuelven optimización con restricciones en SVM y regresión logística, logrando convergencia rápida y eficiente.

Descubre un algoritmo Actor-Critic que converge globalmente en juegos multiagente incorporando aversión al riesgo. Garantías de muestra finita y superioridad sobre métodos neutrales al riesgo.

Nuevos acoplamientos no markovianos revelan cotas exactas de convergencia para difusiones de Langevin cinéticas, superando limitaciones previas en muestreo.

Clasificación binaria con Proto-NN: consistencia universal y privacidad diferencial local con ruido de Laplace.

Descubre cómo el algoritmo SAM puede quedarse atrapado en puntos de silla y cómo el momentum y el tamaño de lote ayudan a mejorar su estabilidad y generalización.

Descubre GRANITE: un framework que protege el aprendizaje descentralizado de ataques bizantinos, logrando convergencia rápida y 9x menos comunicación.

Exploramos cómo la geometría dócil proporciona un marco matemático para garantizar la convergencia del descenso de gradiente en deep learning, incluso en entornos no lisos y no convexos.

Descubre cómo SGD y SMD convergen en expectativa bajo ruido de cola pesada sin modificaciones. Nuevos resultados revelan su potencial.

Descubre cómo los pasos dinámicos de ley de potencia aceleran la convergencia en optimización min-max, alcanzando tasas casi óptimas. Un avance clave para EG y OG.
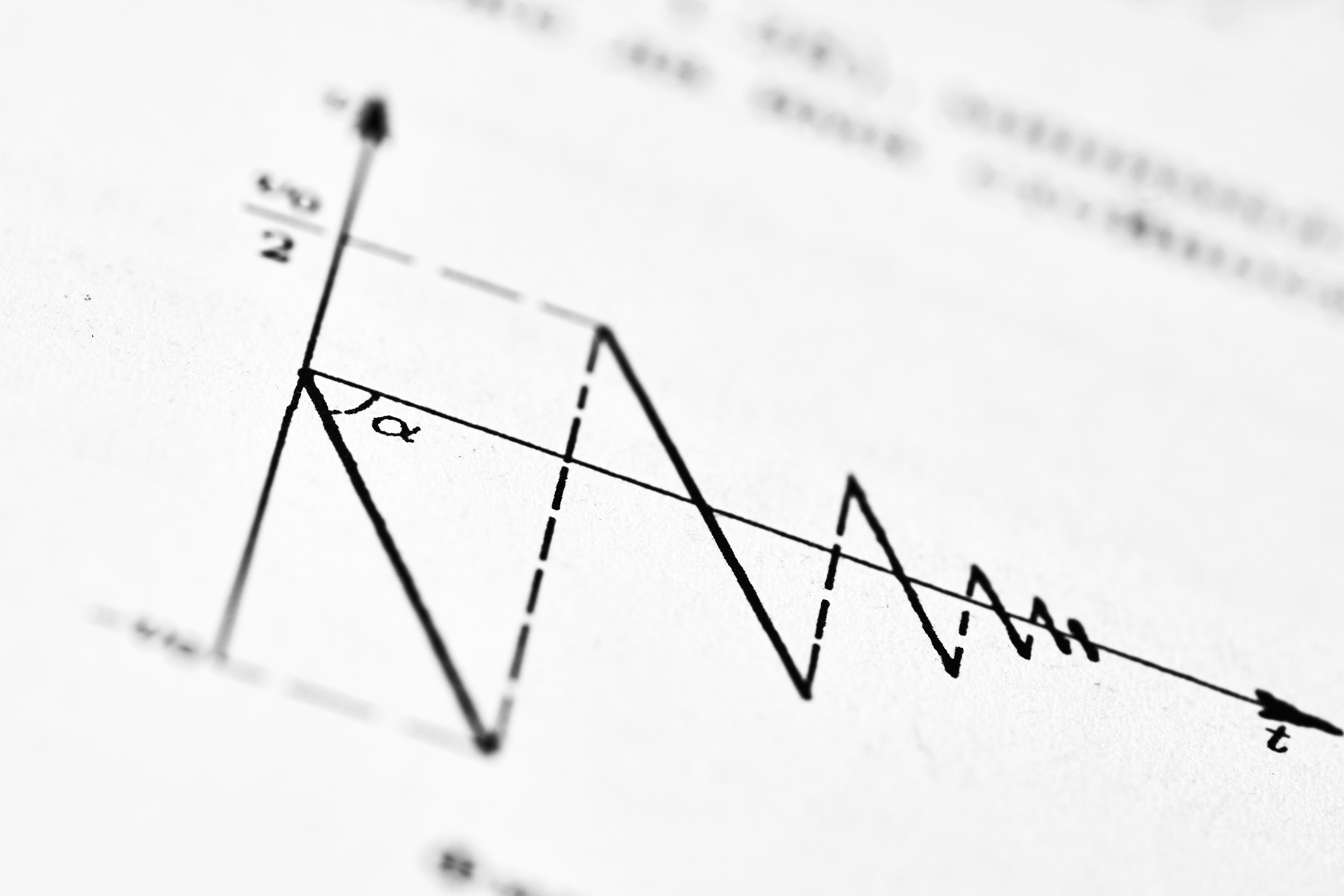
Descubre cómo el algoritmo SAM con paso Polyak mejora la generalización y reduce el ajuste de hiperparámetros, con garantías de convergencia teórica.

Descubre cómo el descenso espejo se adapta a suavidad generalizada para optimizar objetivos no suaves, con aplicaciones en entrenamiento de LLMs. ¡Conoce las nuevas garantías de convergencia!
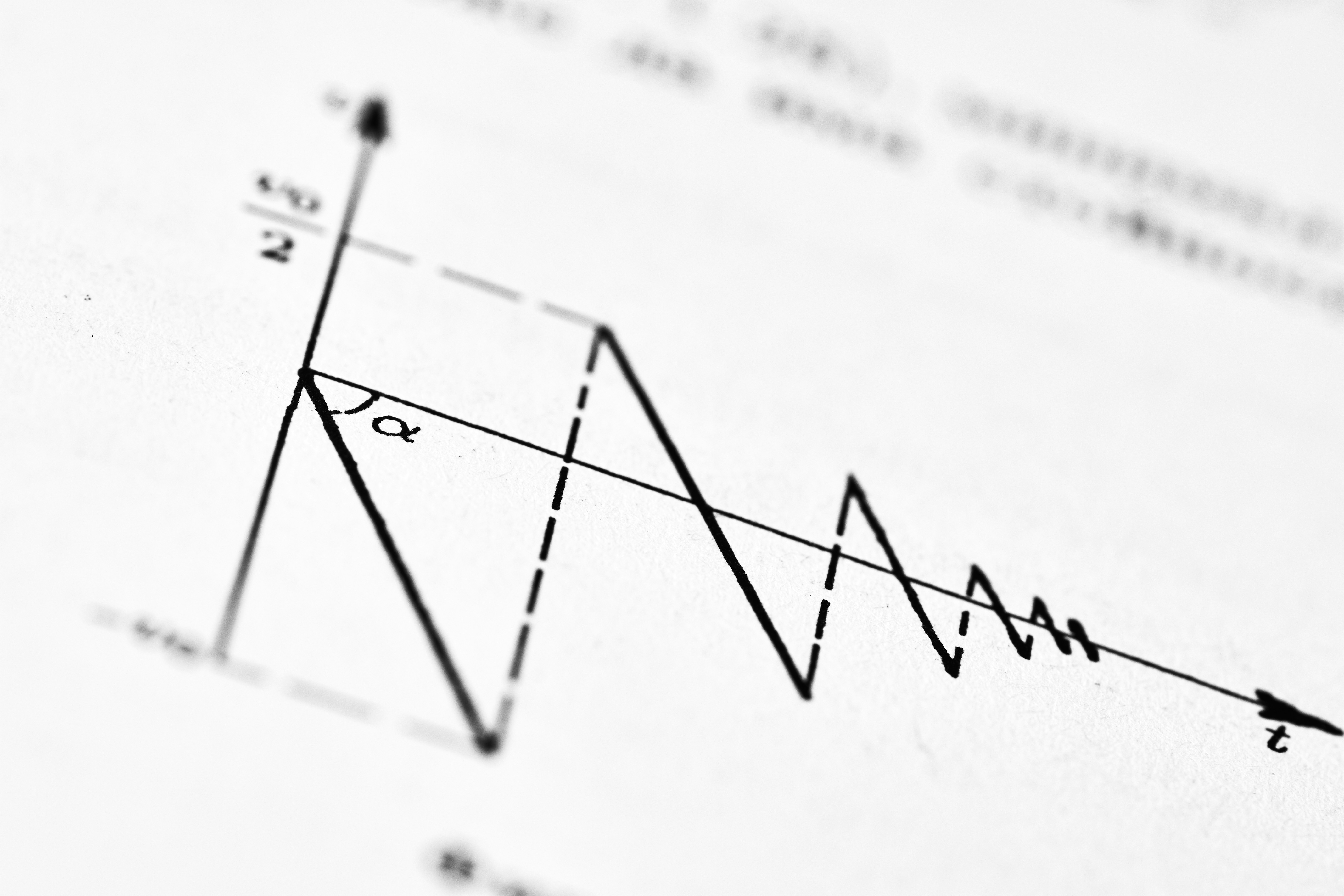
Nuevo método SPS protegido para optimización no suave en redes neuronales. Convergencia robusta sin gradientes pequeños. ¡Mejora tu entrenamiento!
Aproxima divergencias-f con estadísticos de rango. Método rank-statistic para alta dimensión usando proyecciones aleatorias. Eficiente y validado.

Descubre cómo una gaussiana aproxima iteraciones de SA con cotas de error explícitas y tasas de convergencia óptimas, validado con simulaciones.

Mejora la asimilación de datos continua con modelos sustitutos de IA. Reduce error de modelo y asegura convergencia exponencial. Ideal para sistemas dinámicos.

Aprende a resolver ecuaciones diferenciales con deep learning: redes neuronales, retropropagación y método Deep Galerkin. Sin GPU.