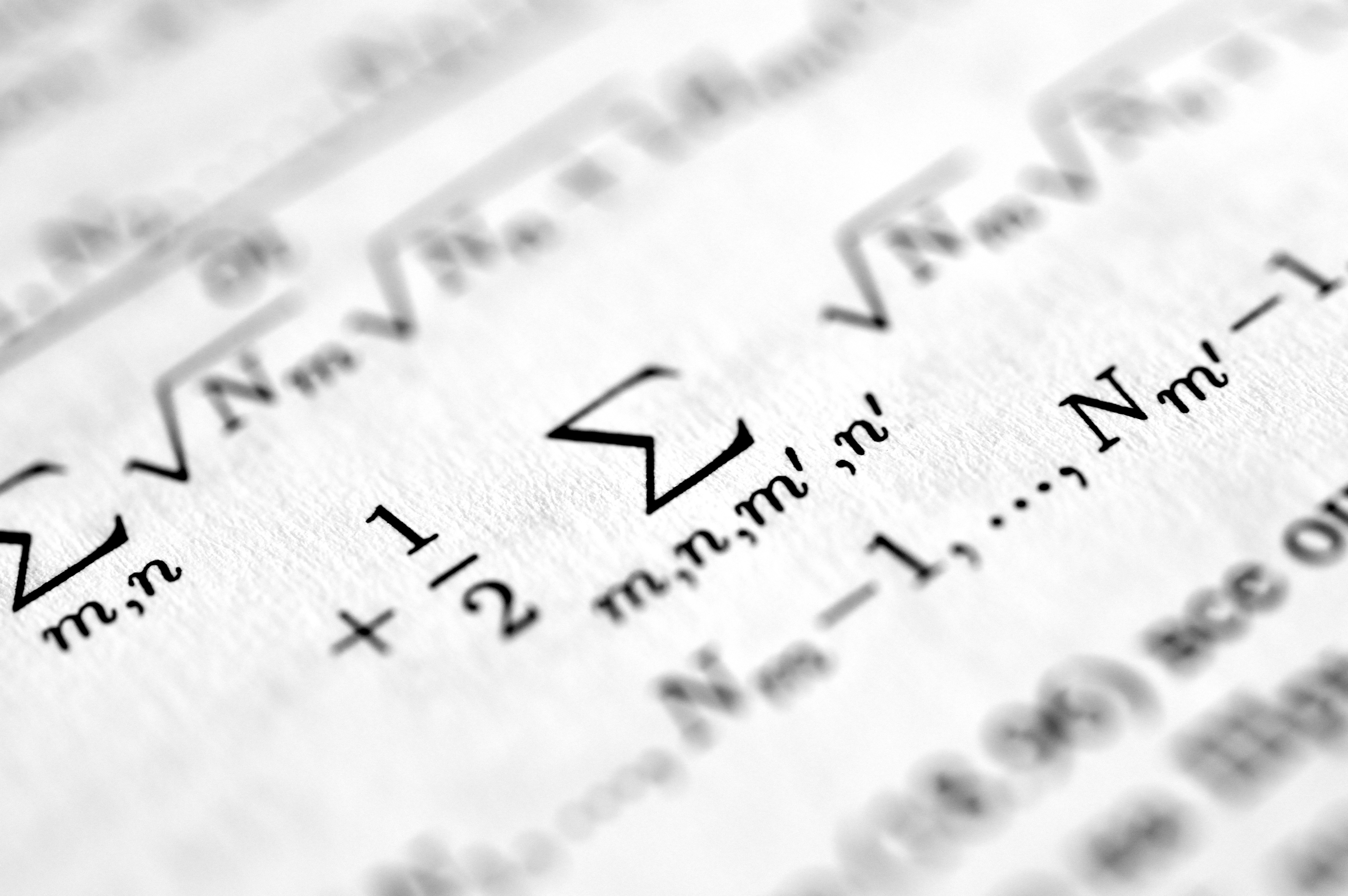
Variables Canónicas en el Espacio Métrico de Wasserstein
Descubre cómo las variables canónicas en el espacio métrico de Wasserstein mejoran la clasificación de distribuciones mediante la maximización de la razón de
Descubre cómo las variables canónicas en el espacio métrico de Wasserstein mejoran la clasificación de distribuciones mediante la maximización de la razón de
La arquitectura GRIL permite a redes recurrentes lineales realizar descenso de gradiente en una sola pasada, aprendiendo en contexto de forma eficiente para

Descubre PURe, un módulo residual plug-and-play que mejora redes de visión mediante interacciones multiplicativas. Aumenta precisión sin aumentar parámetros.

Descubre Mosaic, método de destilación sin datos que usa mezcla de expertos para superar heterogeneidad en aprendizaje federado.

AC-ODM acelera el preentrenamiento de LLM hasta un 66% y mejora precisión en MMLU y HumanEval. ¡Conoce más!

Descubre el rendimiento de clasificadores binarios sin rebalanceo. Evaluamos su robustez ante desbalance extremo con datos reales y sintéticos.

Descubre AL-GNN, un nuevo marco para aprendizaje continuo de grafos que elimina el buffer de replay, preserva la privacidad y reduce el tiempo de entrenamiento

¿GPU necesaria para seguridad de LLM? Los clasificadores CPU igualan rendimiento al 20% del coste. Descubre el pipeline GuardChain.

Descubre cómo un modelo de grafo adaptativo basado en HNSW acelera la inferencia kNN en tiempo real sin comprometer la precisión. Ideal para grandes volúmenes

SLUM-i: aprendizaje semisupervisado para mapeo de asentamientos informales con mejora en calidad de datos. Logra +5.9 pp mIoU.

Descubre CLARITY, un framework de fusión RGB-T adaptativa guiado por lenguaje visual, que logra SOTA en segmentación de escenas de conducción (62.3% mIoU).
NeurMLLM unifica acústica y texto con LLM multimodales para detectar Alzheimer y Parkinson. Resultados superiores en clasificación de etapas.

Descubre cómo un ensemble de InceptionV3 y MobileNetV2 clasifica enfermedades en hojas de limón con un 99.27% de precisión. Entrenamiento adversarial y

Descubre la destilación de conocimiento mejorada que logra 99.04% precisión en clasificación uso de suelo, comprimiendo modelos sin perder rendimiento.

Atención multimodal logra 94.9% de precisión en clasificación automática de daños por desastres usando imágenes satelitales. Ideal para respuesta rápida.

Descubre FastMix, un marco que optimiza automáticamente la mezcla de datos usando gradiente descendente, reduciendo costos y mejorando el rendimiento de tus

Aprende cómo la IA contextual mejora la clasificación de defectos en STEM, alcanzando 98% de precisión con datos químicos.

¿La coactivación revela circuitos de atención? Descubre cómo la prueba de cierre separa propuestas de circuitos confirmados en modelos Pythia y OLMo.
El marco DEC interpreta la procedencia como postura epistémica, agrupa declaraciones en mundos cognitivos y permite razonar sin inconsistencias en grafos.

Descubre las 4 decisiones clave que tomé en el primer año y llevaron a mi startup a una valoración de $120M. Aprende a controlar tu futuro.