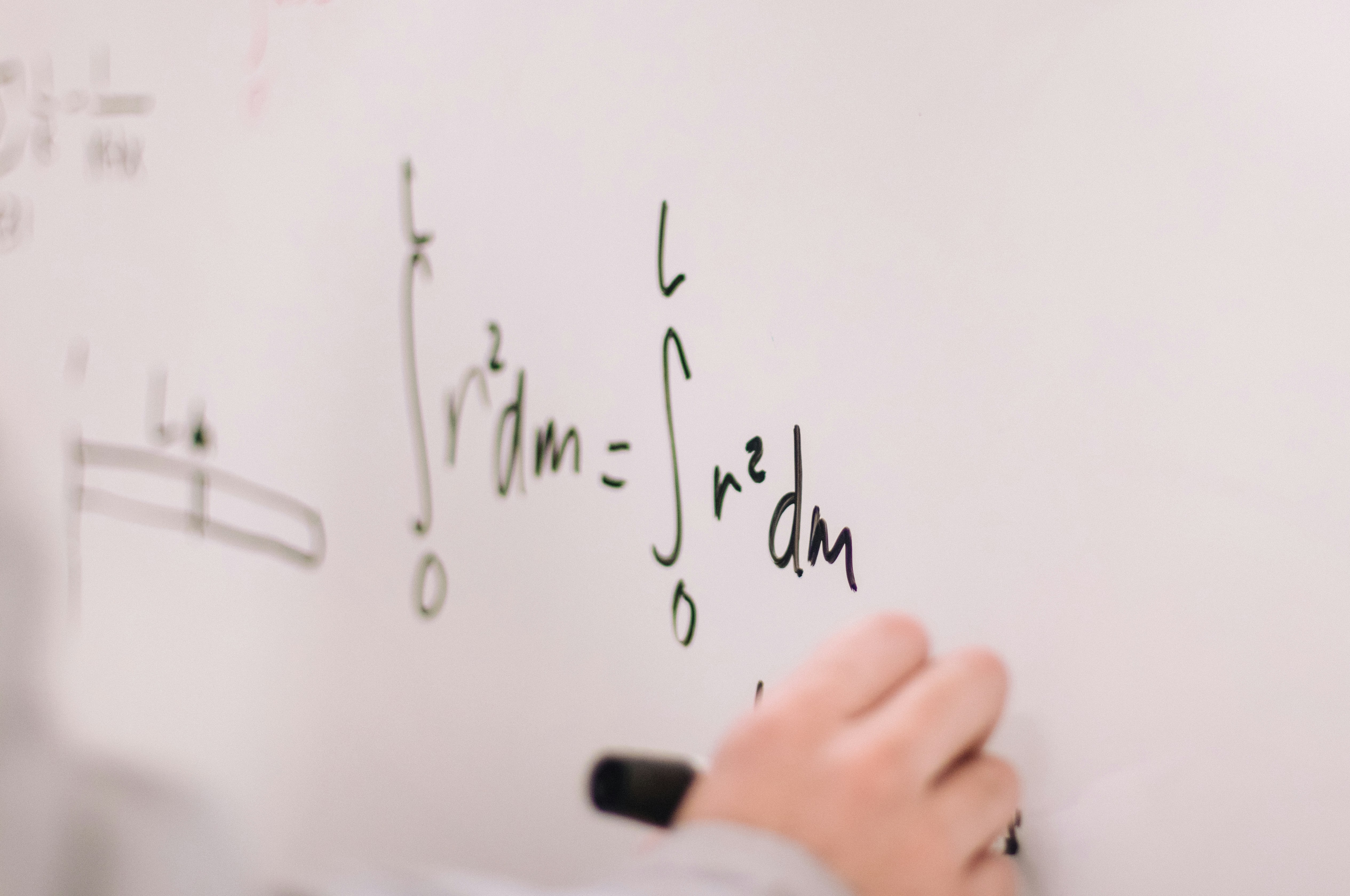
Resolviendo el problema de probabilidad de cadenas de 3Blue1Brown (sin IA)
Resuelve el problema de probabilidad de cadenas de 3Blue1Brown aplicando ciencia de datos, sin IA. ¡Pon a prueba tu pensamiento analítico!
Resuelve el problema de probabilidad de cadenas de 3Blue1Brown aplicando ciencia de datos, sin IA. ¡Pon a prueba tu pensamiento analítico!

El procesamiento inteligente de documentos acelera la innovación verde al conectar investigación, operaciones y ecosistemas sostenibles.

Aprende cómo estimar gradientes de forma insesgada en cadenas de Markov, incluso con mezcla lenta. Perfecto para modelos con redes neuronales.

Optimiza el razonamiento de LLMs en borde móvil con redes de expertos y CoT adaptativo: logra 90% de precisión y latencia en menos de 1 segundo.

El nuevo enfoque Thinking-RFT supera atajos en ToM: mejora un 6% frente a SFT mediante razonamiento y refuerzo.

Aprende cómo los robots superan la lectura errónea de video con destilación en bucle cerrado para predecir acciones exitosas.

Descubre cómo los LLMs construyen grafos causales implícitos desde texto con descubrimiento de cadenas y sabiduría de masas. Evaluado con 1,560 pares.

El Mythos es real: las cadenas de vulnerabilidades más creativas están desafiando a los escáneres SAST. Conoce los hallazgos que cambiarán tu perspectiva.

EP-HUBO usa optimización cuántica para seleccionar la mejor evidencia en razonamiento legal, superando el voto mayoritario y preservando hipótesis correctas.

Descubre cómo RREDCoT redistribuye recompensas en segmentos de cadenas de pensamiento para reducir la varianza y mejorar el aprendizaje por refuerzo en modelos de razonamiento.

Descubre cómo la latencia de autocompromiso revela hacking implícito en modelos de lenguaje sin recompensa externa. Un nuevo enfoque para seguridad en IA.

¿Cómo aplicar los derechos de rectificación y supresión del GDPR en modelos de ML? Analizamos los desafíos en cadenas de suministro y el fenómeno 'modelos en la oscuridad'.
Descubre cómo los grafos causales y las cadenas contrafactuales revelan el razonamiento interno de los LLM, mejorando la transparencia y la interpretabilidad en tareas de clasificación.

Descubre cómo el post-razonamiento y UCoT comprimen cadenas de pensamiento en LLMs, reduciendo tokens un 50% sin perder rendimiento. ¡Mejora la eficiencia!

Descubre cómo el contexto irrelevante acorta hasta un 65% las cadenas de razonamiento de los LLM, reduciendo su autoverificación y afectando tareas complejas.

Aprende cómo los flujos normalizantes Neural Galerkin permiten inferencia bayesiana eficiente en difusiones con fronteras inaccesibles.

Aprende cómo la geometría Monge con conos resuelve transporte óptimo de alta dimensión, ofreciendo soluciones cerradas y métricas Wasserstein interpretables.

Descubre ThoughtFold, un framework que elimina exploraciones redundantes en modelos de razonamiento, reduciendo tokens hasta un 56% sin perder precisión.

¿Los modelos de razonamiento grandes expresan su confianza de forma fiel? Cuantificamos la calibración entre incertidumbre interna y verbalizada, revelando desa
Los mercados tokenizados necesitan protecciones en cadena, no guardianes centralizados. Descubre cómo lograr adopción masiva sin sacrificar la descentralización.