
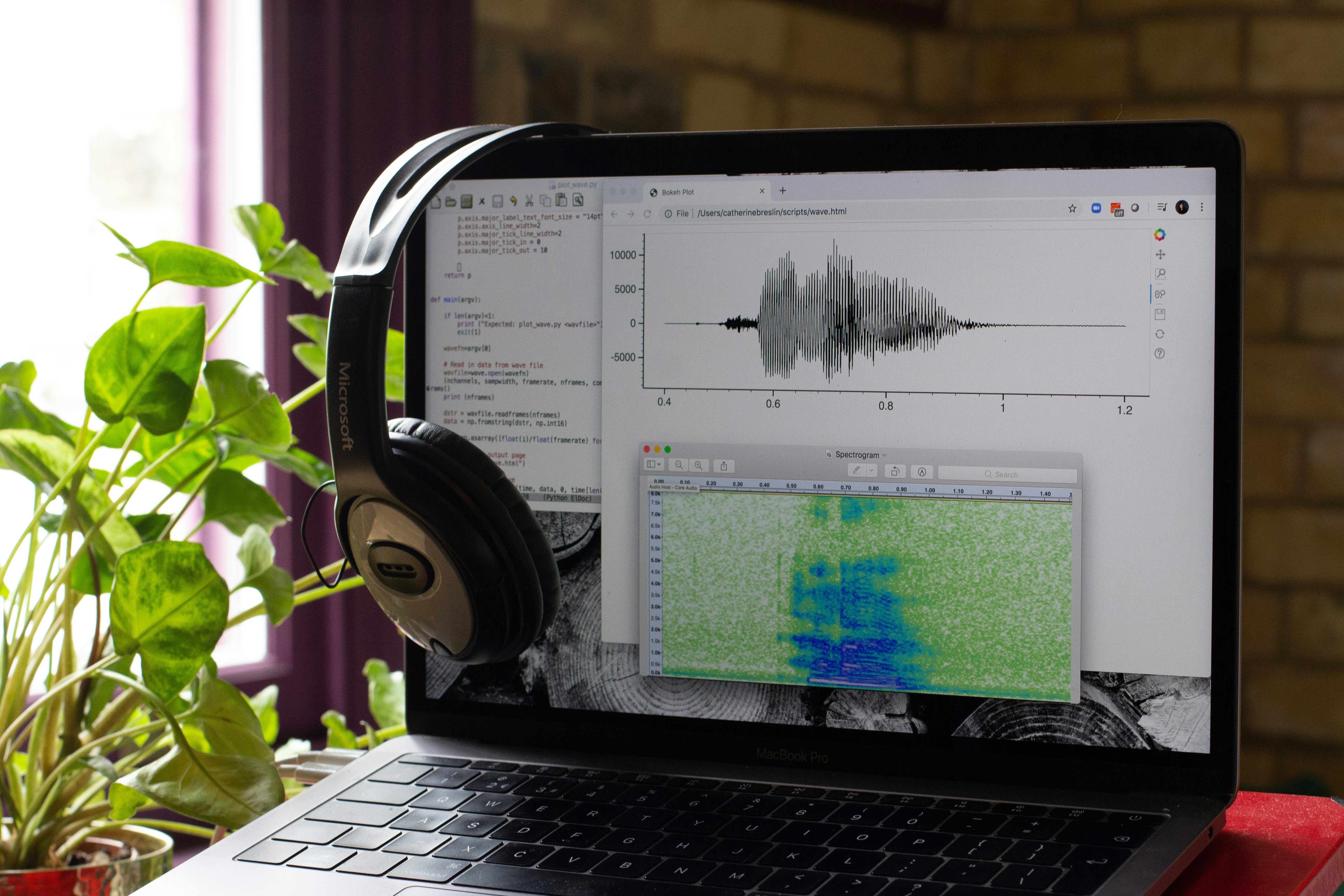
Aprendizaje Federado Personalizado para Reconocimiento de Voz Disártrica
Mejora el reconocimiento de voz disártrica con aprendizaje federado personalizado. Descubre estrategias que reducen el WER hasta un 4.73% relativo. ¡Protege la privacidad!
Mejora el reconocimiento de voz disártrica con aprendizaje federado personalizado. Descubre estrategias que reducen el WER hasta un 4.73% relativo. ¡Protege la privacidad!
Corrige errores de ASR en conversaciones largas usando una memoria ontológica que contextualiza el diálogo y mejora la precisión.

Descubre cómo AuRA internaliza la comprensión del audio en LLMs mediante LoRA, superando a sistemas en cascada con mayor eficiencia y precisión.

Descubre AuRA: integra comprensión de audio en LLMs mediante LoRA para modelado conjunto y eficiente inferencia paralela. Supera a sistemas en cascada.

Whisfusion revoluciona la transcripción ASR con decodificación paralela usando difusión enmascarada, superando a Whisper en precisión y velocidad hasta 5x.

Mejora el reconocimiento de voz en entornos ruidosos con un nuevo método sin entrenamiento que fusiona señales de forma inteligente. Aumenta la precisión y robustez.

Descubre cómo el fine-tuning de Whisper logra 25.6% WER en alemán suizo, evitando contaminación de benchmarks. Un análisis honesto con 13.8% cWER y modelos públicos.

Speechmatics es la empresa de IA de voz destacada esta semana. Su tecnología de transcripción en tiempo real entiende acentos, ruido y jerga. Descubre más.

Descubre MAI-Transcribe-1.5: precisión récord en FLEURS, velocidad 5x superior y biasing de entidades. Ideal para transcripción empresarial.

El ataque Semantic Gambit explota LLMs para aumentar el Word Error Rate al 35.6% en ASR en tiempo real. Conoce esta nueva vulnerabilidad.

Reduce alucinaciones de Whisper hasta un 86% usando autoencoders dispersos. Aprende la técnica de steering en representaciones ocultas.
Descubre Nemotron 3.5 ASR de NVIDIA: modelo de 600M parámetros que transcribe 40 idiomas en tiempo real con latencia ajustable. Código abierto en Hugging Face.

Nuevo ataque adversario en ASR evade defensas al perturbar representaciones SSL, mejorando la transferibilidad como en Whisper.

El grupo TA4922 vinculado a China expande ataques de phishing a Reino Unido, Alemania, Italia y Sudáfrica usando malware ValleyRAT y AtlasRAT.

Optimiza el reconocimiento de voz con LARM: un Transformer en bucle que escala el cómputo en tiempo de prueba, mejorando la tasa de error de palabras.

Descubre cómo el modelo Audio-Interaction unifica tareas de audio en streaming, permitiendo interacción en tiempo real con percepción, decisión y respuesta proactiva.

Descubre cómo FSA-GRPO entrena modelos auditivos con aprendizaje por refuerzo para mejorar el reconocimiento de voz usando pocos ejemplos.
Descubre BaltiVoice, el primer corpus de voz público para el idioma balti. Ajustamos Whisper y reducimos el error de 182% a 30%. ¡Modelo y demo disponibles!

Descubre cómo generar conversaciones sintéticas con LLM y TTS para entrenar ASR de forma eficiente, logrando mejor rendimiento con pocos datos reales

AlignAtt4LLM logra traducción simultánea inglés-alemán/italiano con baja latencia aplicando AlignAtt en LLMs solo decodificador. Resultados superiores.