Efecto Scaffold: Cómo el Marco del Prompt Influye en Evaluación VLM Clínicos
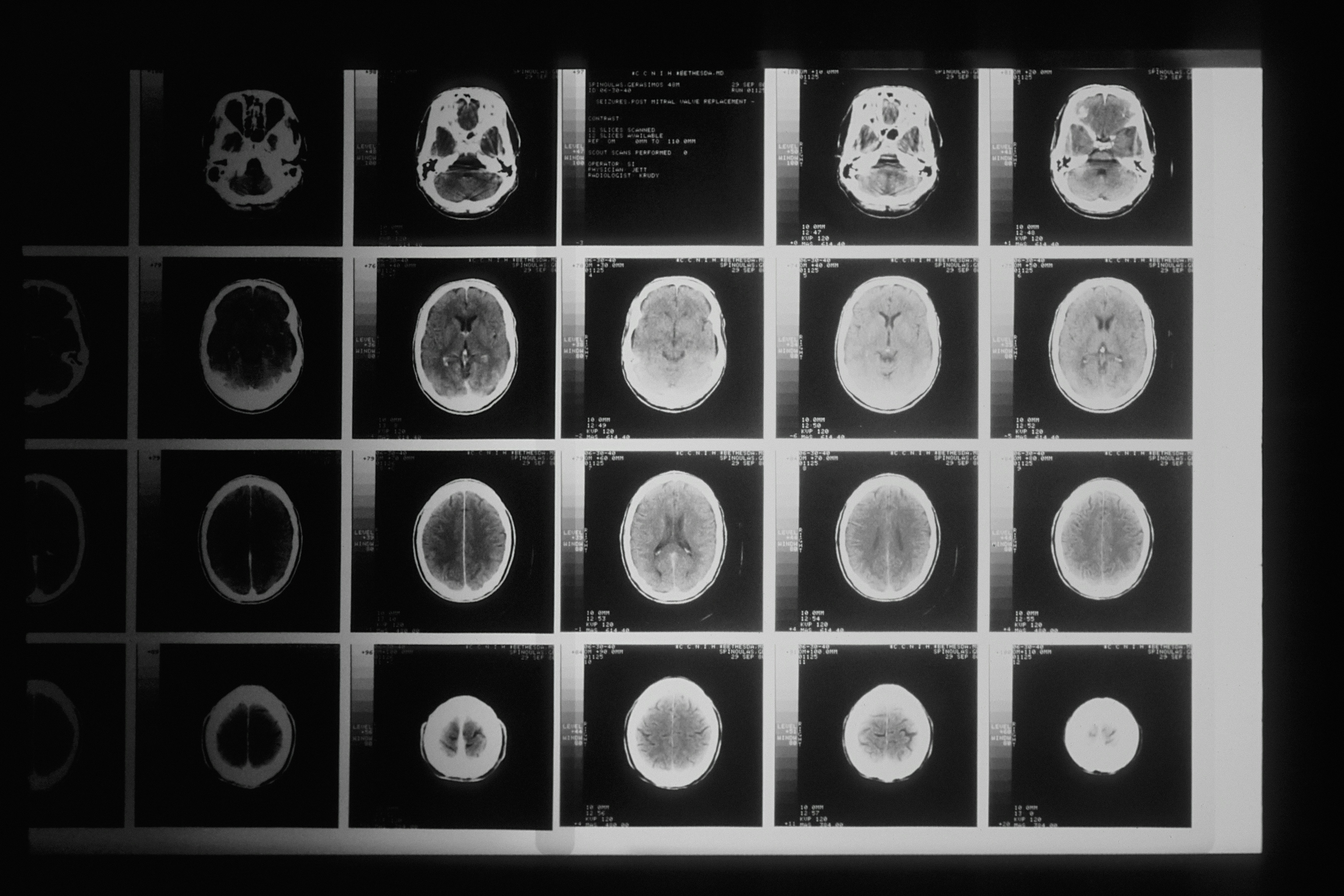
La inteligencia artificial aplicada al diagnóstico clínico promete transformar la medicina, pero su fiabilidad depende de que los modelos realmente aprendan a integrar información relevante y no simplemente a explotar atajos superficiales. Un fenómeno recientemente identificado en la evaluación de modelos de lenguaje y visión (VLMs) para neuroimagen revela una trampa sutil: el simple hecho de mencionar la disponibilidad de resonancias magnéticas en el prompt del modelo, incluso cuando esas imágenes no están presentes, puede inflar artificialmente las métricas de rendimiento. Este hallazgo, denominado 'efecto scaffold', demuestra que hasta un 80% de la mejora aparente al incorporar contexto multimodal se debe al marco textual y no a un verdadero razonamiento basado en datos de imagen.
Para las empresas que desarrollan soluciones de ia para empresas, esta advertencia es clave: evaluar correctamente un modelo no solo implica medir su precisión, sino entender qué señales utiliza realmente para decidir. Si no se diseñan protocolos de validación robustos, un sistema podría parecer competente en el laboratorio y fallar estrepitosamente en un entorno real. Esto conecta directamente con la necesidad de contar con servicios de inteligencia artificial que incorporen principios de auditoría, transparencia y pruebas adversariales desde la fase de diseño.
En Q2BSTUDIO, como empresa de desarrollo de software y tecnología, abordamos este desafío combinando conocimiento técnico con metodologías probadas. Nuestros equipos trabajan en aplicaciones a medida y software a medida que integran modelos de lenguaje y visión, pero sometemos cada componente a análisis de confianza: evaluamos si el modelo realmente razona sobre las entradas multimodales o si se apoya en correlaciones espurias. Además, ofrecemos servicios cloud aws y azure para desplegar estos sistemas con la escalabilidad y seguridad necesarias, y servicios inteligencia de negocio con power bi para monitorear métricas de rendimiento y detectar sesgos en tiempo real.
El efecto scaffold también alerta sobre los riesgos de confiar ciegamente en benchmarks simplistas. En el ámbito clínico, donde las decisiones afectan vidas humanas, es imprescindible que los agentes IA sean entrenados y evaluados con datos que reflejen la incertidumbre real del diagnóstico. Por eso, desde nuestra experiencia en desarrollo de aplicaciones multiplataforma, diseñamos soluciones que incluyen capas de verificación y explicabilidad, garantizando que la inteligencia artificial no solo acierte, sino que lo haga por las razones correctas.
La lección es clara: la innovación en IA debe ir acompañada de rigor metodológico. Ya sea que se trate de un sistema de clasificación de imágenes médicas o de un asistente virtual para atención al cliente, la calidad de los datos y la honestidad de las evaluaciones determinan el éxito a largo plazo. En un mercado donde la ciberseguridad y la ética son cada vez más importantes, apostar por un desarrollo responsable no es opcional: es la única vía para construir tecnología verdaderamente confiable.
Comentarios