Compilación incremental basada en consultas en Rust

La compilación incremental basada en consultas es una arquitectura moderna para compiladores que prioriza consultas finas y reusables sobre las pasadas monolíticas tradicionales. En lugar de ejecutar fases completas como lexing, parsing y generación de código por separado, aquí cada unidad de conocimiento del compilador se modela como una consulta concreta, por ejemplo obtener el tipo de retorno de una función o el árbol sintáctico abstracto de un módulo.
En la arquitectura clásica en pipeline cada etapa produce un artefacto grande que sirve de entrada a la siguiente, lo que puede implicar trabajo innecesario cuando solo se requiere una parte de la información. En cambio, la arquitectura basada en consultas permite pedir únicamente la pieza de información necesaria, reduciendo el coste de cómputo y facilitando la recompilación incremental.
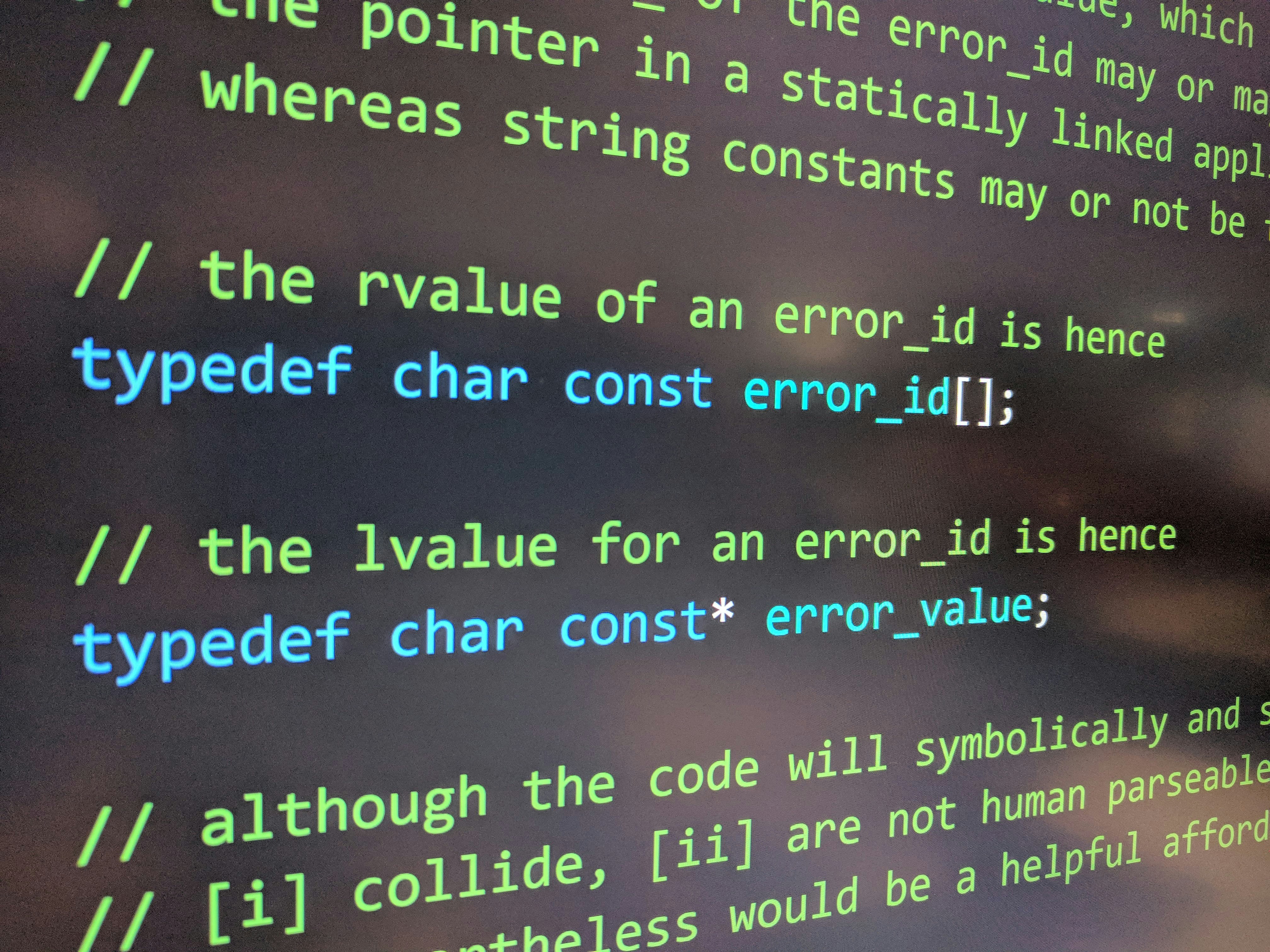
La implementación típica incluye tres componentes lógicos: la definición de la clave de consulta que describe entrada y salida, la implementación que ejecuta la consulta y un motor central que registra ejecutores y despacha consultas. El motor mantiene un registro de resultados, versiones y dependencias para decidir qué respuestas pueden reutilizarse y cuáles deben recomputarse.
Las dependencias entre consultas forman un grafo dirigido acíclico. Al ejecutar una consulta el motor registra qué otras consultas fueron solicitadas, construyendo así el grafo. Cuando se detecta un cambio en el código fuente, el motor recorre este grafo para invalidar o verificar resultados, evitando recomputar lo que permanece válido.
Controlar versiones y huellas digitales es clave. Cada resultado se guarda con metadatos como versión de creación, versión de verificación, huella estable de 128 bits y la lista de dependencias. La huella sirve para comparar el resultado entre ejecuciones y decidir si, aunque se haya recomputado algo, su valor efectivo no cambió y por tanto no debe invalidar a consumidores posteriores.
La detección de ciclos en las dependencias es necesaria para evitar consultas recursivas infinitas. En la práctica el motor lleva una pila de llamadas a consultas y, si se detecta un ciclo, devuelve un error específico que se propaga hacia arriba para que el compilador lo gestione.
Para permitir compilación incremental entre ejecuciones del compilador es imprescindible persistir los resultados. En lugar de serializar un único gran objeto en memoria, es más eficiente almacenar resultados individualmente en una base de datos clave valor. Esto permite carga puntual al pedido, guarda en segundo plano y arranques mucho más rápidos.
La paralelización es un beneficio importante pero exige diseño cuidadoso. Es necesario evitar contención excesiva en estructuras de datos compartidas, permitir que una única ejecución de una consulta sea exclusiva mientras otras la esperan, y preferir modelos asíncronos para evitar bloqueos y agotamiento de hilos. Los caminos rápidos de lectura y caminos lentos de escritura ayudan a escalar el motor.
Entre las ventajas de esta aproximación destacan testabilidad, paralelismo natural y ejecución bajo demanda que evita trabajo innecesario. Las desventajas incluyen sobrecarga inicial para montar la infraestructura, posible boilerplate al definir consultas y mayor consumo de memoria por el seguimiento de estados y dependencias en grandes bases de código.
En la práctica, muchas implementaciones en Rust aprovechan rasgos y técnicas de type erasure para registrar ejecutores heterogéneos, además de traits estables para generar huellas reproducibles. Aunque aquí no se describen detalles de bajo nivel, el patrón general consiste en desacoplar la declaración de una consulta de su ejecución y centralizar el control en un Engine que gestiona registro, ejecución, caché y persistencia.
En Q2BSTUDIO aportamos experiencia en desarrollo de software a medida y diseño de arquitecturas eficientes como motores de compilación incremental, integrando buenas prácticas de ingeniería de software, pruebas y despliegue. Si su proyecto requiere aplicaciones a medida o soluciones específicas de backend para análisis de código, podemos ayudarle a diseñar una plataforma basada en consultas que escale con su código base. Vea más sobre nuestro enfoque de desarrollo de aplicaciones en Desarrollo de aplicaciones y software a medida.
Además, la combinación de este tipo de arquitecturas con servicios cloud permite implementar almacenamiento persistente y procesamiento distribuido. En Q2BSTUDIO ofrecemos integración con servicios cloud aws y azure para desplegar bases de datos clave valor, colas y entornos serverless que optimizan la persistencia y la concurrencia de un motor de consultas. Conozca nuestros servicios cloud en AWS y Azure para escalar su plataforma.
Como empresa especializada en inteligencia artificial, ciberseguridad y servicios de inteligencia de negocio, en Q2BSTUDIO también podemos enriquecer pipelines de compilación y análisis estático con agentes IA que automaticen detección de patrones, o con paneles de Power BI para visualizar métricas clave del proceso de compilación. Palabras clave que representan nuestra oferta incluyen aplicaciones a medida, software a medida, inteligencia artificial, ciberseguridad, servicios cloud aws y azure, servicios inteligencia de negocio, ia para empresas, agentes IA y power bi.
Si necesita asesoría para construir un motor de compilación incremental, integrar técnicas de fingerprinting estable o desplegar la solución en la nube de forma segura y escalable, Q2BSTUDIO le acompaña desde la arquitectura hasta la entrega continua y el soporte operativo.
Resumen rápido: la compilación incremental basada en consultas introduce consultas finas, grafo de dependencias, versionado y fingerprinting, persistencia por clave valor y ejecución concurrente segura. Es una inversión en infraestructura con alto retorno para proyectos grandes donde la velocidad de recompilación y la paralelización son críticas.
También te puede interesar
Explorando índices y cardinalidad con JavaScript

¡SerpApi: Una API completa para obtener datos de motores de búsqueda!

Creando SVGs adaptables con <symbol>, <use> y consultas de medios en CSS

¿Cómo puedo obtener soporte técnico para los servicios de desarrollo de n8n?
El costo real de integrar GPT en el cuidado de la salud

Comentarios