Code-on-Graph: Razonamiento Programático con LLMs
Descubre Code-on-Graph, framework que combina LLMs y grafos de conocimiento para razonamiento programático flexible. Supera limitaciones de precisión y escalabilidad.
Descubre Code-on-Graph, framework que combina LLMs y grafos de conocimiento para razonamiento programático flexible. Supera limitaciones de precisión y escalabilidad.
CA-RAG optimiza el enrutamiento en RAG: reduce tokens 26% y latencia 34%.

Descubre cómo las representaciones generalizadas de Fourier permiten aprender DNF bajo distribuciones no producto. Un avance clave en teoría del aprendizaje automático.

FlowGuard protege IDS energéticos de robos de modelos sin identidad. Detecta consultas fuera de distribución mediante flujo normalizado. ¡Aumenta tu seguridad!
Descubre cómo la elicitación causal de preferencias acelera el descubrimiento causal con consultas activas a expertos. Un enfoque bayesiano para concentrar la posterior sobre DAGs.
Descubre cómo los LLMs optimizan planes de consulta física en tiempo de prueba, logrando aceleraciones de hasta 4.78x en consultas OLAP. ¡Aumenta la eficiencia!

Descubre cómo un enfoque adaptativo con LLM y redes neuronales predice opiniones grupales con solo el 10% de encuestados.

MLSkip usa metadatos ligeros para optimizar filtros ML en bases de datos. Logra aceleración hasta 1.07x en DuckDB. ¡Mejora el rendimiento de tus consultas!

Descubre por qué los modelos del mundo pueden fallar en IA encarnada y cómo construir modelos físicamente viables para consultas de intervención.

Descubre marco optimización prompts que utiliza evaluación unificada para mejorar calidad respuestas por consulta. Resultados interpretables y consistentes.
SchemaForge mejora precisión en consultas SPARQL heterogéneas con validación contrafactual. Aumenta accuracy 11.5% en benchmarks clave.

Descubre cómo determinar si un conjunto de datos se ajusta a una hipótesis lógica en estructuras infinitas. Análisis de complejidad y uso de consultas naturales para clasificar muestras.

Descubre cómo las consultas adaptativas superan el límite de consultas uniformes para recuperar comunidades exactamente.

Mejora la relevancia de búsqueda en la App Store con juicios generados por LLM. Este método escala etiquetas textuales y aumenta la tasa de conversión un 0,24%.

Descubre por qué auditar políticas casi óptimas en RL puede ser exponencialmente difícil. Analizamos cotas inferiores de consulta y la capacidad Rashomon.

Las malas prácticas de SQL en la nube generan fugas financieras. Aprende a arquitecturar consultas eficientes y reducir costos hasta un 40%.

IBM presenta aceleración GPU para watsonx.data: consultas 25x más rápidas y 80% menos costos. Conoce sus beneficios para tu negocio.
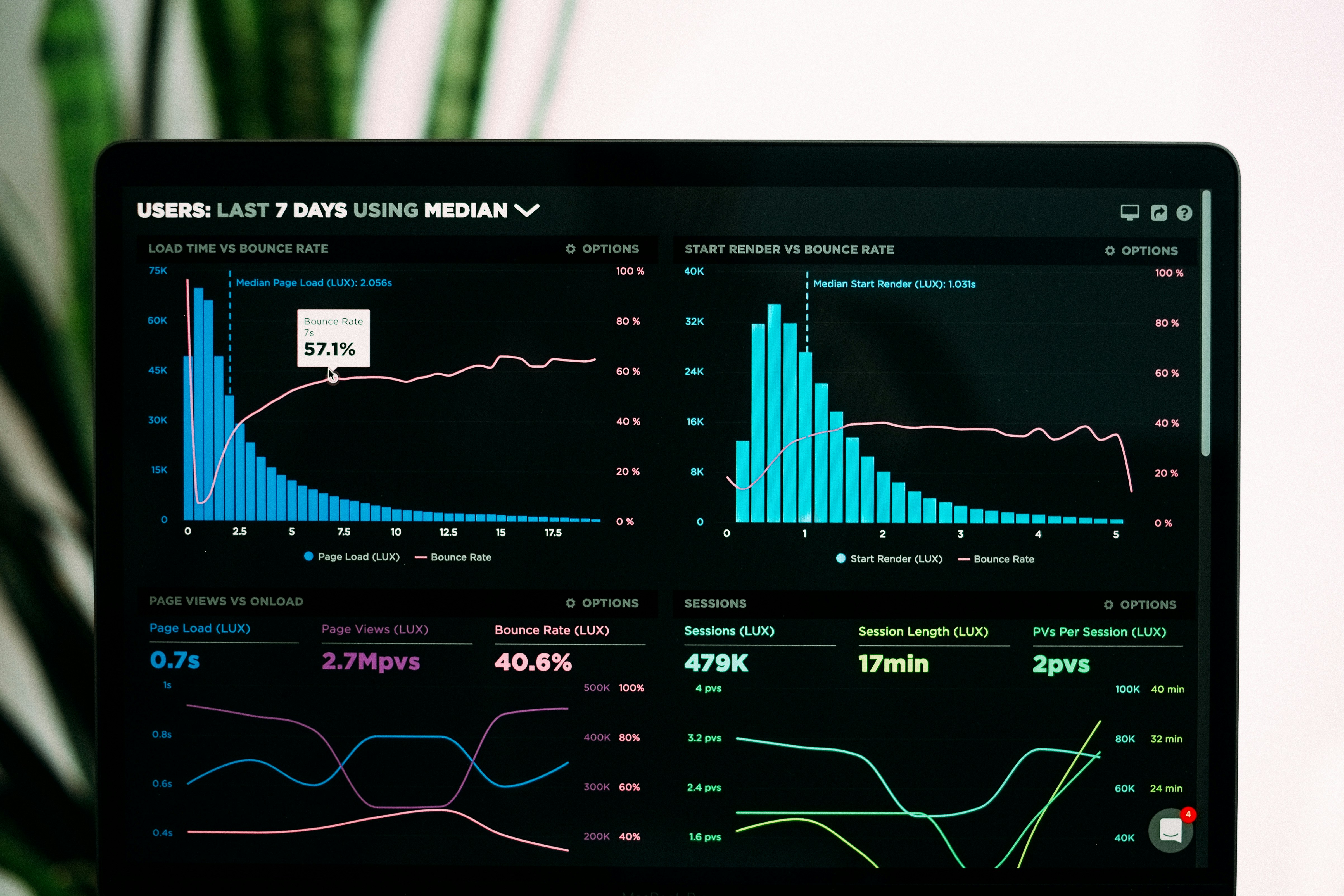
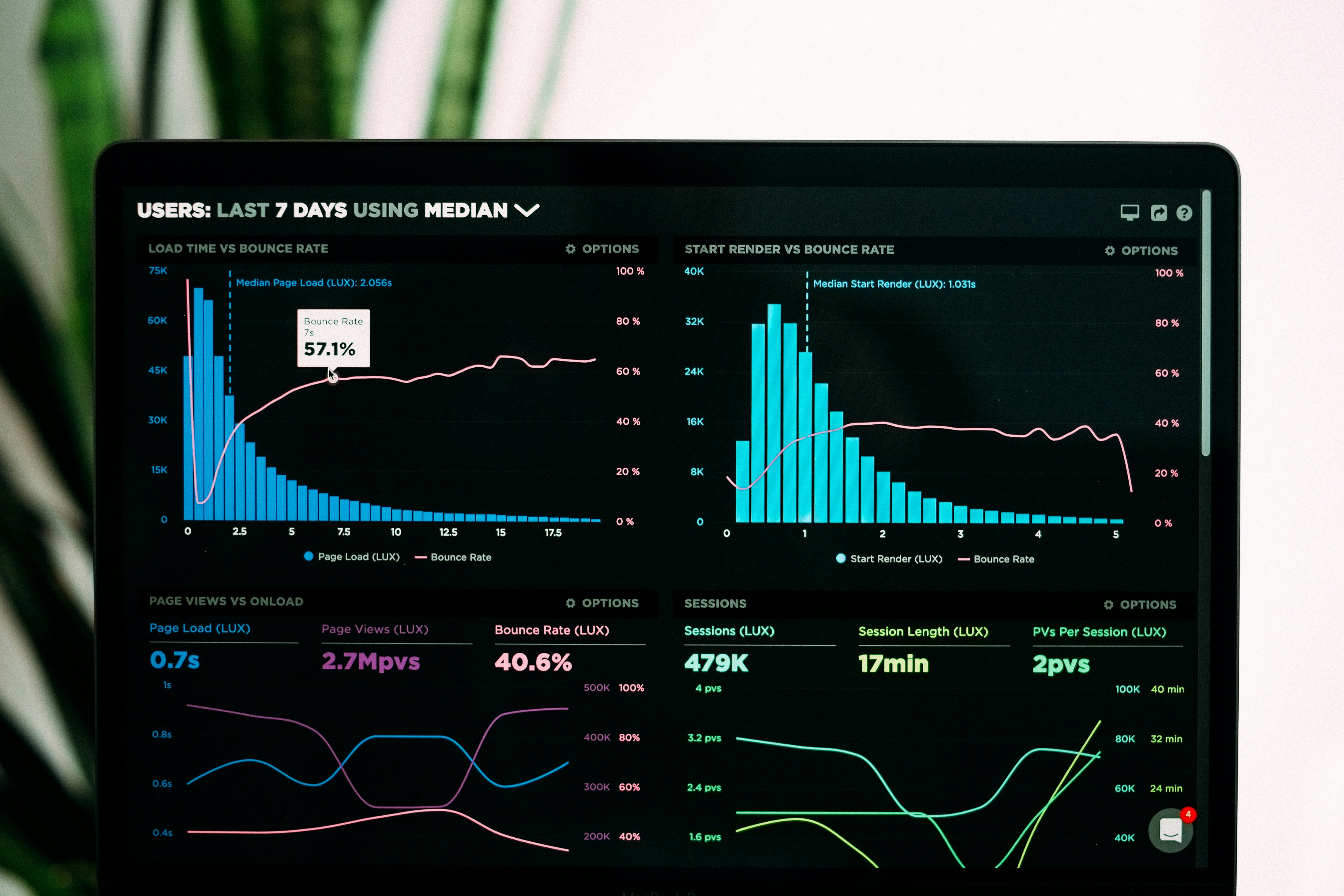
Descubre cómo las consultas pushdown reducen la latencia de API hasta 5x y el consumo de memoria 160x frente al filtrado en memoria. Resultados de benchmark.

SIRIUS-SQL mejora Texto-SQL anclando múltiples candidatos con feedback de ejecución. Logra 75.88% en BIRD y 91.20% en SPIDER. ¡Descubre cómo!

Mueve la consulta en lugar del caché KV y reduce la latencia en atención entre GPUs. Optimiza clusters H100 con RDMA.