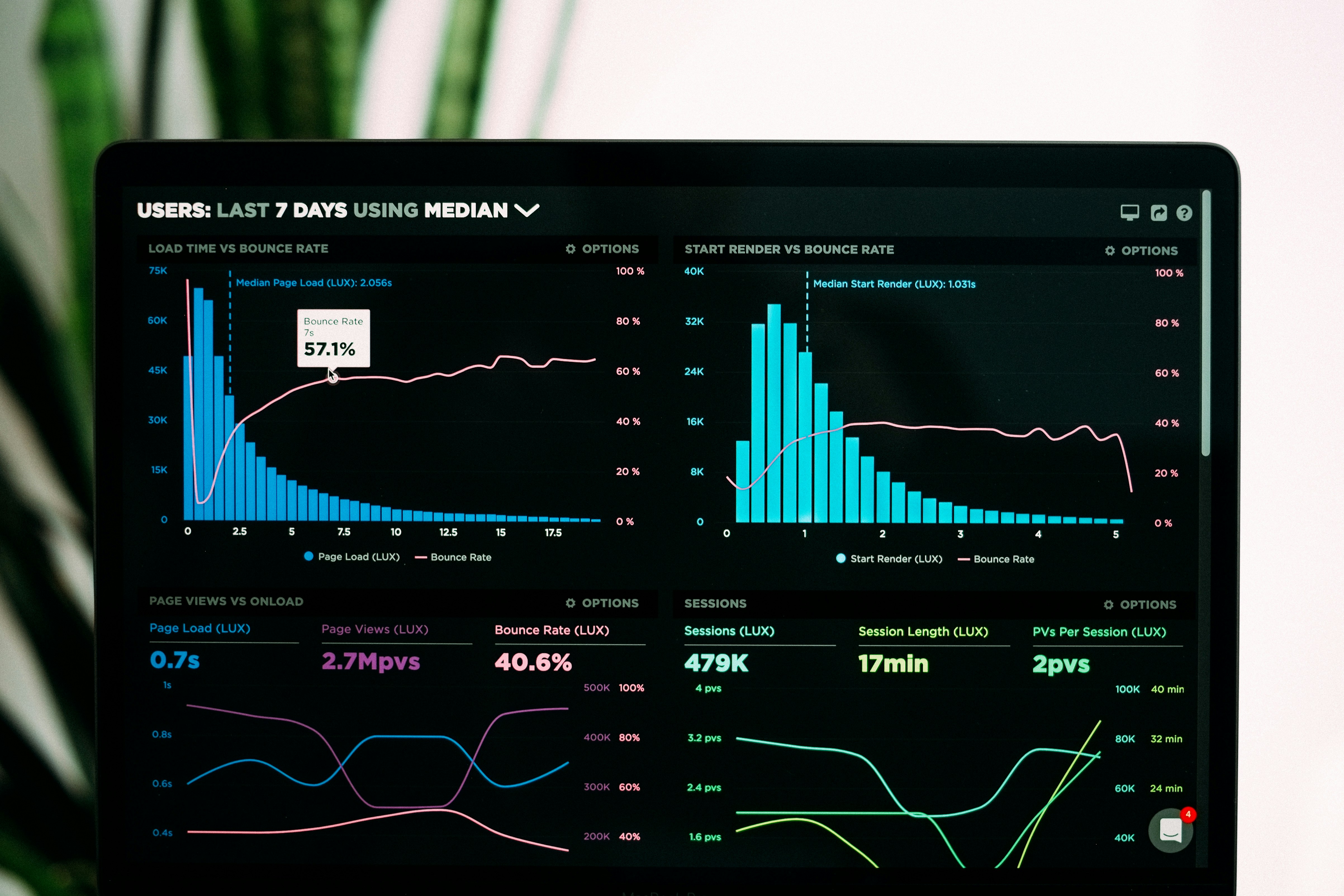
Optimice una base de datos Postgres de 1.7M filas para ejecutarse en 66ms en 6GB RAM
Aprende a optimizar una base de datos Postgres de 1.7M filas en solo 66ms con índices compuestos, caché de traducciones y UGC seguro. Técnicas de bajo costo.
Aprende a optimizar una base de datos Postgres de 1.7M filas en solo 66ms con índices compuestos, caché de traducciones y UGC seguro. Técnicas de bajo costo.

Aprende a reconstruir la tabla de contenidos de un PDF que no incluye índice, usando dos métodos clave para que RAG pueda segmentar por secciones. Incluye paso
Descubre cómo optimizar búsquedas lentas en bases de datos relacionales sin recurrir a un motor de búsqueda. Técnicas prácticas para pasar de 90 segundos a

Descubre cómo el análisis de 138k trayectorias de agentes revela la brecha intención-ejecución y mejora el rendimiento de modelos IA.
Descubre cómo Transformers con aumento de datos desplazados (SDA) mejora precisión y robustez en pronóstico de índices como VN30 y S&P 500.

¿Cansado de luchar con los tipos de Mongoose? Descubre Mongster, un ODM TypeScript que unifica esquema, inferencia y validación con una sola dependencia.
Descubre DerivBot Pro: trading automatizado con TensorFlow.js para Deriv.com. 6 tipos de contrato, 23 índices sintéticos, ML continuo. ¡Licencia vitalicia $25!

Descubre cómo escalar un motor de exposición de credenciales a 3.8B registros: lecciones de ingeniería de datos, optimización de índices y deduplicación masiva.

Descubre cómo elegir el índice vectorial en Postgres según memoria, recall, escrituras y filtros. De HNSW a DiskANN y búsqueda híbrida con BM25.

Guía completa sobre índices vectoriales en Postgres: cuándo usar HNSW, IVFFlat o DiskANN según memoria, recall, escrituras y filtros. ¡Optimiza tu búsqueda!

Descubre BLINQ, el nuevo algoritmo basado en modelos que aprende índices Whittle de forma más rápida y precisa que Q-learning, reduciendo muestras y costo computacional.

Descubre cómo la proyección y cuantización unifican el aprendizaje de hash, desde técnicas clásicas hasta la era RAG, optimizando la búsqueda de vecinos cercanos.

EinSort: ordenando índices para tensorizar LLMs. Descubre estructuras de rango bajo y comprime pesos y KV-cache con mejor calidad. ¡Optimiza tus modelos!

Descubre cómo SIFT optimiza el prefill de RAG usando índices selectivos de atención, acelerando el TTFT hasta 1.71x con precisión casi perfecta.

¿Tu RAG da respuestas seguras pero obsoletas? Aprende cómo una capa de confianza en recuperación evita que datos desactualizados lleguen al usuario.