
Mejora de VLMs patológicos mediante razonamiento multiescala
Mejora diagnóstico patológico con VLMs entrenados con razonamiento multiescala. Scale-VQA y ScaleReasoner-R1 superan atajos textuales con rendimiento superior.
Mejora diagnóstico patológico con VLMs entrenados con razonamiento multiescala. Scale-VQA y ScaleReasoner-R1 superan atajos textuales con rendimiento superior.

OmniTraffic: pipeline y benchmark para razonamiento espacio-temporal. Evalúa 11 MLLMs con 8M VQA, revela brecha humano-modelo. Simulación mejora rendimiento.

Descubre cómo el sesgo de primacía Perdidos al final afecta a los sistemas de QA multimodal con recuperación, donde la información al inicio del contexto

Descubre el sesgo de primacía en VQA multimodal: la información al principio supera al final en hasta 26 puntos. Clave para IA.

OpenMedQ: modelo de VLM médico preentrenado en 14 datasets abiertos logra SOTA en PathVQA y VQA-MED. Supera modelos 80x mayores. Código abierto.

IAPO: un algoritmo de RL que mejora la capacidad de llamar a herramientas en agentes multimodales pequeños, logrando un 3% más de precisión en VQA.

Aumenta un 3% la precisión en VQA con IAPO, algoritmo RL que alinea la atribución de entrada en agentes multimodales pequeños. ¡Descubre cómo!

MSUE combina texto, imagen y video para responder preguntas sobre fútbol con un 95% de precisión. Conoce su arquitectura multi-experto.

Descubre cómo Reroute optimiza tokens visuales en VLMs, mejora grounding y mantiene rendimiento VQA. Técnica sin entrenamiento que redirige tokens.

SD-GRPO mejora la generación de respuestas largas en modelos multimodales al descomponer segmentos verificables y asignar recompensas precisas.

Modelos de visión-lenguaje con múltiples personalidades: ¿cómo afecta al rendimiento? Conoce los hallazgos sobre equilibrio y residuales.

Descubre cómo la inferencia colaborativa edge-to-server reduce el costo de comunicación en modelos VLM sin sacrificar precisión. Optimiza tu infraestructura con transmisión selectiva.

¿Puede una IA entender tu carrete de fotos? Conoce camroll-agent, un asistente que responde preguntas visuales personales con memoria jerárquica. Dataset de 50 usuarios.

Un agente de IA personal responde preguntas visuales sobre tu galería. El dataset Camroll y agente Camroll-Agent con memoria jerárquica.
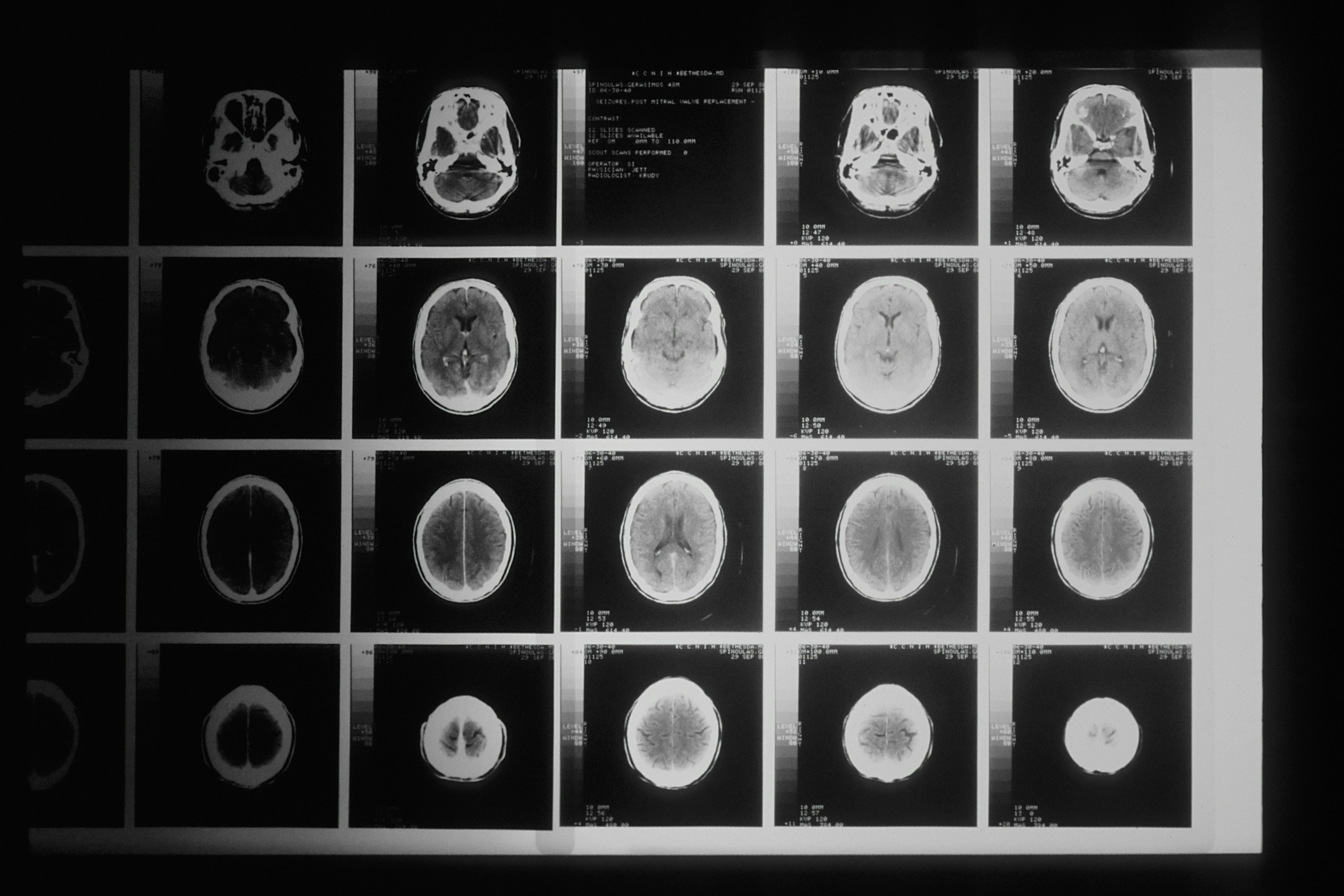
MedReCo: un framework que permite a la IA razonar comparativamente entre imágenes radiológicas, mejorando diagnósticos y seguimientos. Resultados clínicos superiores.

Descubre cómo un modelo VLM consciente de creencias integra memoria y aprendizaje por refuerzo para un razonamiento similar al humano, mejorando tareas de VQA.

R3G: marco de razonamiento-recuperación-reordenamiento para VQA. Mejora la precisión al integrar un plan de razonamiento y recuperación de imágenes en dos etapas.

Descubre Hyper-ICL, un método ligero que elimina la necesidad de demostraciones en ICL multimodal, calibrando la atención con destilación hiperbólica para mejorar precisión y estabilidad.

Descubre cómo VISTA combina visión y validación física para adaptar datos UMI y entrenar modelos VLA, mejorando el rendimiento en manipulación robótica real.

Aprende a destilar reglas de programación lógica desde LLMs para VQA interpretable, con solo pocos ejemplos. Alternativa eficiente al aprendizaje de reglas tradicional.