
WorldFly: Navegación de drones con modelos del mundo
Descubre cómo WorldFly usa modelos del mundo para que los drones naveguen en entornos urbanos complejos, prediciendo futuros estados y superando oclusiones.
Descubre cómo WorldFly usa modelos del mundo para que los drones naveguen en entornos urbanos complejos, prediciendo futuros estados y superando oclusiones.

HyperLoRA elimina sesgos de agregación y retrasos en inicialización, logrando convergencia más rápida y personalización robusta en modelos fundacionales.

Descubre UNIVID, el modelo que unifica visión y lenguaje para moderar videos con precisión, interpretabilidad y eficiencia, reduciendo violaciones y costos.
Nuevo benchmark CausalPhys con 3,000 preguntas evalúa razonamiento causal en VLMs. Mejora precisión e interpretabilidad con aprendizaje causal.

BloomBench: el primer benchmark bilingüe para evaluar cognitivamente modelos de visión-lenguaje. Asimetrías clave entre árabe e inglés.

Descubre BloomBench, benchmark bilingüe (árabe-inglés) que evalúa la capacidad cognitiva de modelos visión-lenguaje. Revela brechas en memoria y creatividad.

Descubre cómo DRIFT adapta modelos de visión-lenguaje para generar salidas continuas con precisión, mejorando tareas como grounding visual y control robótico.
DRIFT adapta modelos VLM para salidas continuas con un adaptador de flujo residual, mejorando precisión en percepción y control robótico.
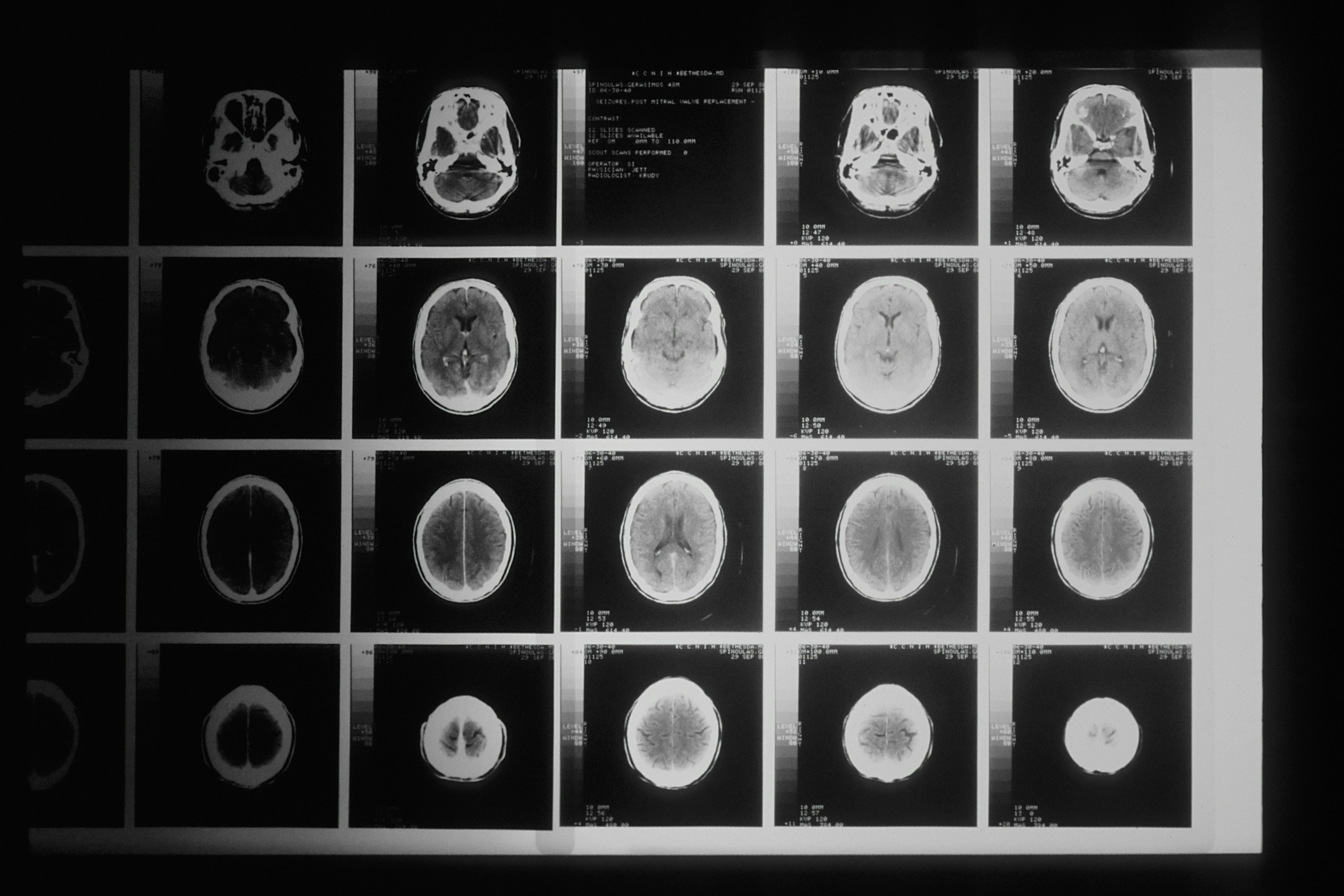
MedReCo: un framework que permite a la IA razonar comparativamente entre imágenes radiológicas, mejorando diagnósticos y seguimientos. Resultados clínicos superiores.

Descubre cómo LEVANTE-bench compara modelos de IA con niños de 5 a 12 años en tareas cognitivas. ¿Son los VLMs más inteligentes que un niño de 5º grado?

Descubre cómo SceneDiver rompe el cuello de botella perceptual en IA visión-lenguaje, reduciendo alucinaciones visuales en robótica y navegación.

Descubre cómo el modelo VLM consciente de creencias combina memoria y RL para un razonamiento similar al humano. Mejora en QA visual con HD-EPIC. ¡Lee más!

Descubre cómo ZeroWBC permite a humanoides interactuar de forma natural sin teleoperación, aprendiendo de videos egocéntricos.

EvoPrompt: evolución guiada de prompts para adaptación sin olvido de VLMs en pocos datos. Preserva conocimiento pre-entrenado.

Codificadores visuales con estado mejoran la comparación entre imágenes en modelos de visión-lenguaje, superando a especialistas en radiología y teledetección.

Descubre cómo los codificadores visuales con estado mejoran los modelos visión-lenguaje en tareas multi-imagen y superan a modelos en radiología y teledetección

SAS revela asimetrías en modelos visión-lenguaje médicos, midiendo desequilibrio de modalidad. Útil para diagnóstico práctico en IA clínica.

KODA compara y alinea representaciones de modelos visión-lenguaje como CLIP y SigLIP usando kernels. Identifica discrepancias estructurales interpretables.

Descubre cómo VISTA combina visión y validación física para adaptar datos UMI y entrenar modelos VLA, mejorando el rendimiento en manipulación robótica real.

Descubre cómo OGKD mejora la precisión en modelos médicos al respetar relaciones entre clases. Resultados superiores en 11 datasets.