Qwen3.7-Plus de Alibaba: multimodal a bajo costo, pero propietario
Nuevo modelo multimodal de Alibaba, Qwen3.7-Plus, a bajo costo pero propietario. Analizamos su rendimiento, precios y licencia.
Nuevo modelo multimodal de Alibaba, Qwen3.7-Plus, a bajo costo pero propietario. Analizamos su rendimiento, precios y licencia.

Descubre libros, películas, videojuegos y podcasts que capturan la esencia de The White Lotus: lujo, misterio y crítica social. Perfecto para fans de thriller.

Descubre v-HUB, el nuevo benchmark para evaluar cómo los modelos multimodales entienden el humor en videos. ¿Puede la IA captar la comedia visual y sonora?

Evaluamos el rendimiento de seis apps de videollamada con IA. ¿Qué importa más: latencia o capacidad del modelo? Resultados sorprendentes.

StreamingVLM revoluciona la comprensión de video en tiempo real: procesa flujos infinitos con solo 8 FPS en un H100, superando a GPT-4O mini. ¡Descubre su arquitectura!
CoFi mejora la planificación a largo plazo con difusión composicional. Hasta 8 veces menos evaluaciones. Ideal para robótica, video e imágenes.

Descubre R3-CoVR, un marco zero-shot sin entrenamiento que alcanza 91.9% R@1 en recuperación de videos compuestos mediante razonamiento multimodal y reordenamiento.
Descubre por qué la percepción visual supera al razonamiento en preguntas de video. Análisis del modelo Perception First para el desafío VRR 2026.
Descubre MPMWorlds, un dataset de simulaciones físicas con el Método de Puntos Materiales. Comparamos generación de código y difusión de video para inferir y extrapolar dinámicas. ¡Lee más!

Descubre TLG, un sistema que mejora la precisión en razonamiento temporal de video del 46.9% al 71.37% usando anotaciones reales y lógica formal. ¡Aumenta el rendimiento en preguntas de video!

MAVL es un benchmark multilingüe multimodal para traducir canciones animadas. SylAVL-CoT usa audio-video y restricciones silábicas para letras cantables.
Descubre cómo construimos un sistema escalable de producción de video usando Adobe Premiere Pro para crear contenido viral de alta calidad.

La IA filtra el ruido del feedback de playtest y te entrega peticiones y problemas de equilibrio priorizados. Ahorra tiempo y mejora tu juego.

Descubre APB-V: acelera la comprensión de videos largos en múltiples GPUs hasta 12.72x sin pérdida de rendimiento. Ideal para modelos multimodales.
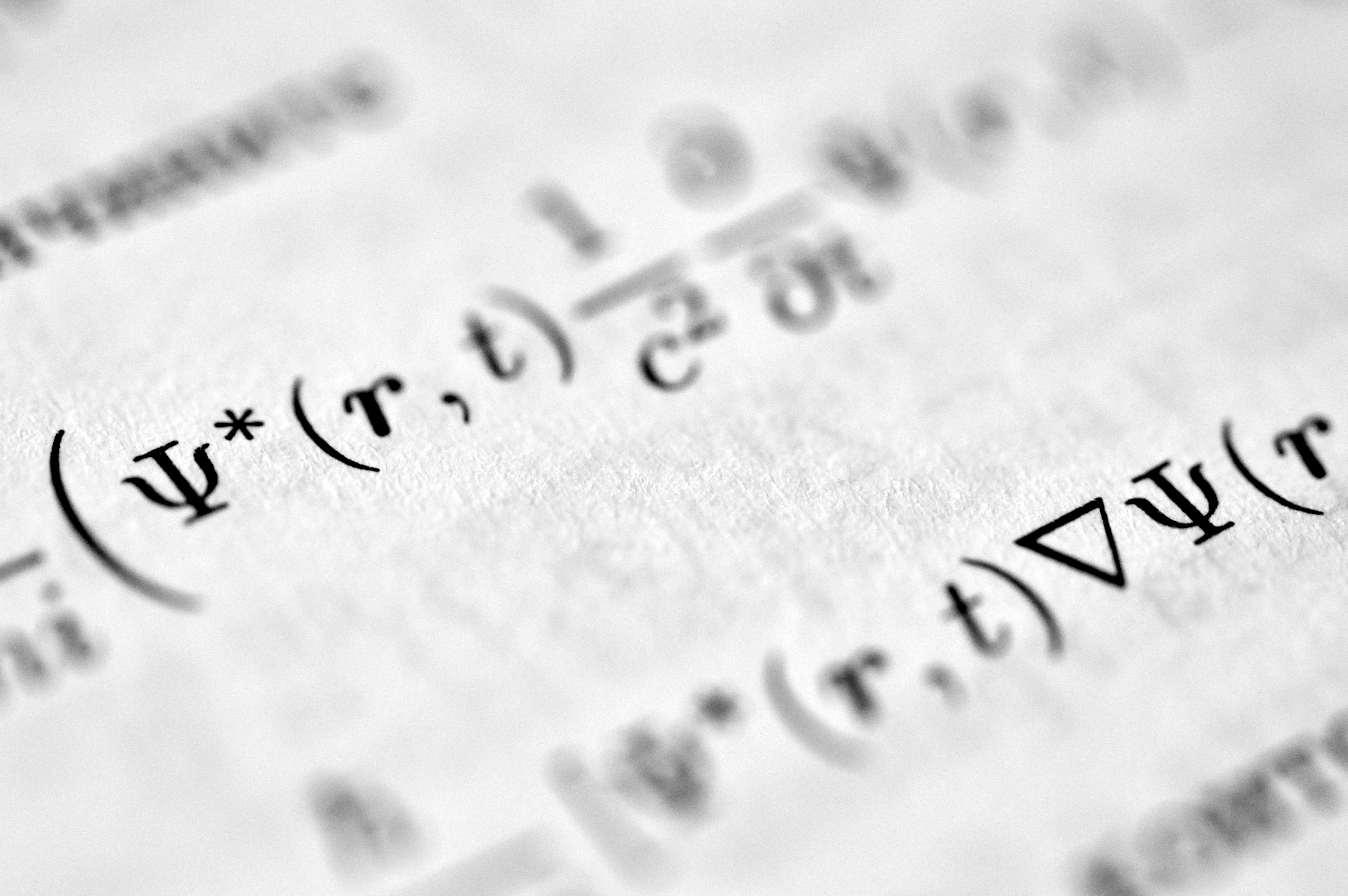
Identifica parámetros físicos desde video con datos mínimos. Sistemas subamortiguados requieren solo un clip. Sin reconstrucción de píxeles.

Construye un auditor de cumplimiento procesal con NVIDIA Nemotron y VSS. Analiza miles de horas de video de campo con IA y obtén hallazgos calibrados en minutos.
RTSP sigue vivo: descubre por qué este protocolo de 1998 es clave en videovigilancia y robótica con baja latencia y simplicidad.

¿Pueden los modelos multimodales advertir peligros en video antes de que ocurran? PaSBench-Video pone a prueba su precisión temporal. Descubre los resultados.
Moment-Video evalúa la capacidad de MLLM para captar eventos visuales que duran solo unos fotogramas. Resultados sorprendentes.

AdaCodec reduce tokens visuales en video MLLMs hasta 1/7, mejorando benchmarks y reduciendo tiempo de primera respuesta de 9.26s a 1.62s.